STD-Filtered, N-Pole Gaussian Filter [Loxx]This is a Gaussian Filter with Standard Deviation Filtering that works for orders (poles) higher than the usual 4 poles that was originally available in Ehlers Gaussian Filter formulas. Because of that, it is a sort of generalized Gaussian filter that can calculate arbitrary (order) pole Gaussian Filter and which makes it a sort of a unique indicator. For this implementation, the practical mathematical maximum is 15 poles after which the precision of calculation is useless--the coefficients for levels above 15 poles are so high that the precision loss actually means very little. Despite this maximal precision utility, I've left the upper bound of poles open-ended so you can try poles of order 15 and above yourself. The default is set to 5 poles which is 1 pole greater than the normal maximum of 4 poles.
The purpose of the standard deviation filter is to filter out noise by and by default it will filter 1 standard deviation. Adjust this number and the filter selections (price, both, GMA, none) to reduce the signal noise.
What is Ehlers Gaussian filter?
This filter can be used for smoothing. It rejects high frequencies (fast movements) better than an EMA and has lower lag. published by John F. Ehlers in "Rocket Science For Traders".
A Gaussian filter is one whose transfer response is described by the familiar Gaussian bell-shaped curve. In the case of low-pass filters, only the upper half of the curve describes the filter. The use of gaussian filters is a move toward achieving the dual goal of reducing lag and reducing the lag of high-frequency components relative to the lag of lower-frequency components.
A gaussian filter with...
One Pole: f = alpha*g + (1-alpha)f
Two Poles: f = alpha*2g + 2(1-alpha)f - (1-alpha)2f
Three Poles: f = alpha*3g + 3(1-alpha)f - 3(1-alpha)2f + (1-alpha)3f
Four Poles: f = alpha*4g + 4(1-alpha)f - 6(1-alpha)2f + 4(1-alpha)3f - (1-alpha)4f
and so on...
For an equivalent number of poles the lag of a Gaussian is about half the lag of a Butterworth filters: Lag = N*P / pi^2, where,
N is the number of poles, and
P is the critical period
Special initialization of filter stages ensures proper working in scans with as few bars as possible.
From Ehlers Book: "The first objective of using smoothers is to eliminate or reduce the undesired high-frequency components in the eprice data. Therefore these smoothers are called low-pass filters, and they all work by some form of averaging. Butterworth low-pass filters can do this job, but nothing comes for free. A higher degree of filtering is necessarily accompanied by a larger amount of lag. We have come to see that is a fact of life."
References John F. Ehlers: "Rocket Science For Traders, Digital Signal Processing Applications", Chapter 15: "Infinite Impulse Response Filters"
Included
Loxx's Expanded Source Types
Signals
Alerts
Bar coloring
Related indicators
STD-Filtered, Gaussian Moving Average (GMA)
STD-Filtered, Gaussian-Kernel-Weighted Moving Average
One-Sided Gaussian Filter w/ Channels
Fisher Transform w/ Dynamic Zones
R-sqrd Adapt. Fisher Transform w/ D. Zones & Divs .
Стандартное отклонение (волатильность)
STD-Filtered, Gaussian Moving Average (GMA) [Loxx]STD-Filtered, Gaussian Moving Average (GMA) is a 1-4 pole Ehlers Gaussian Filter with standard deviation filtering. This indicator should perform similar to Ehlers Fisher Transform.
The purpose of the standard deviation filter is to filter out noise by and by default it will filter 1 standard deviation. Adjust this number and the filter selections (price, both, GMA, none) to reduce the signal noise.
What is Ehlers Gaussian filter?
This filter can be used for smoothing. It rejects high frequencies (fast movements) better than an EMA and has lower lag. published by John F. Ehlers in "Rocket Science For Traders". First implemented in Wealth-Lab by Dr René Koch.
A Gaussian filter is one whose transfer response is described by the familiar Gaussian bell-shaped curve. In the case of low-pass filters, only the upper half of the curve describes the filter. The use of gaussian filters is a move toward achieving the dual goal of reducing lag and reducing the lag of high-frequency components relative to the lag of lower-frequency components.
A gaussian filter with...
one pole is equivalent to an EMA filter.
two poles is equivalent to EMA(EMA())
three poles is equivalent to EMA(EMA(EMA()))
and so on...
For an equivalent number of poles the lag of a Gaussian is about half the lag of a Butterworth filters: Lag = N * P / (2 * ¶2), where,
N is the number of poles, and
P is the critical period
Special initialization of filter stages ensures proper working in scans with as few bars as possible.
From Ehlers Book: "The first objective of using smoothers is to eliminate or reduce the undesired high-frequency components in the eprice data. Therefore these smoothers are called low-pass filters, and they all work by some form of averaging. Butterworth low-pass filtters can do this job, but nothing comes for free. A higher degree of filtering is necessarily accompanied by a larger amount of lag. We have come to see that is a fact of life."
References John F. Ehlers: "Rocket Science For Traders, Digital Signal Processing Applications", Chapter 15: "Infinite Impulse Response Filters"
Included
Loxx's Expanded Source Types
Signals
Alerts
Bar coloring
Related indicators
STD-Filtered, Gaussian-Kernel-Weighted Moving Average
One-Sided Gaussian Filter w/ Channels
Fisher Transform w/ Dynamic Zones
R-sqrd Adapt. Fisher Transform w/ D. Zones & Divs.

STD-Filtered, Gaussian-Kernel-Weighted Moving Average [Loxx]STD-Filtered, Gaussian-Kernel-Weighted Moving Average is a moving average that weights price by using a Gaussian kernel function to calculate data points. This indicator also allows for filtering both source input price and output signal using a standard deviation filter.
Purpose
This purpose of this indicator is to take the concept of Kernel estimation and apply it in a way where instead of predicting past values, the weighted function predicts the current bar value at each bar to create a moving average that is suitable for trading. Normally this method is used to create an array of past estimators to model past data but this method is not useful for trading as the past values will repaint. This moving average does NOT repaint, however you much allow signals to close on the current bar before taking the signal. You can compare this to Nadaraya-Watson Estimator wherein they use Nadaraya-Watson estimator method with normalized kernel weighted function to model price.
What are Kernel Functions?
A kernel function is used as a weighing function to develop non-parametric regression model is discussed. In the beginning of the article, a brief discussion about properties of kernel functions and steps to build kernels around data points are presented.
Kernel Function
In non-parametric statistics, a kernel is a weighting function which satisfies the following properties.
A kernel function must be symmetrical. Mathematically this property can be expressed as K (-u) = K (+u). The symmetric property of kernel function enables its maximum value (max(K(u)) to lie in the middle of the curve.
The area under the curve of the function must be equal to one. Mathematically, this property is expressed as: integral −∞ + ∞ ∫ K(u)d(u) = 1
Value of kernel function can not be negative i.e. K(u) ≥ 0 for all −∞ < u < ∞.
Kernel Estimation
In this article, Gaussian kernel function is used to calculate kernels for the data points. The equation for Gaussian kernel is:
K(u) = (1 / sqrt(2pi)) * e^(-0.5 *(j / bw)^2)
Where xi is the observed data point. j is the value where kernel function is computed and bw is called the bandwidth. Bandwidth in kernel regression is called the smoothing parameter because it controls variance and bias in the output. The effect of bandwidth value on model prediction is discussed later in this article.
Included
Loxx's Expanded Source types
Signals
Alerts
Bar coloring

Polynomial Regression Bands w/ Extrapolation of Price [Loxx]Polynomial Regression Bands w/ Extrapolation of Price is a moving average built on Polynomial Regression. This indicator paints both a non-repainting moving average and also a projection forecast based on the Polynomial Regression. I've included 33 source types and 38 moving average types to smooth the price input before it's run through the Polynomial Regression algorithm. This indicator only paints X many bars back so as to increase on screen calculation speed. Make sure to read the tooltips to answer any questions you have.
What is Polynomial Regression?
In statistics, polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as an nth degree polynomial in x. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted E(y |x). Although polynomial regression fits a nonlinear model to the data, as a statistical estimation problem it is linear, in the sense that the regression function E(y | x) is linear in the unknown parameters that are estimated from the data. For this reason, polynomial regression is considered to be a special case of multiple linear regression .
Related indicators
Polynomial-Regression-Fitted Oscillator
Polynomial-Regression-Fitted RSI
PA-Adaptive Polynomial Regression Fitted Moving Average
Poly Cycle
Fourier Extrapolator of Price w/ Projection Forecast
STD-Stepped Fast Cosine Transform Moving Average [Loxx]STD-Stepped Fast Cosine Transform Moving Average is an experimental moving average that uses Fast Cosine Transform to calculate a moving average. This indicator has standard deviation stepping in order to smooth the trend by weeding out low volatility movements.
What is the Discrete Cosine Transform?
A discrete cosine transform (DCT) expresses a finite sequence of data points in terms of a sum of cosine functions oscillating at different frequencies. The DCT, first proposed by Nasir Ahmed in 1972, is a widely used transformation technique in signal processing and data compression. It is used in most digital media, including digital images (such as JPEG and HEIF, where small high-frequency components can be discarded), digital video (such as MPEG and H.26x), digital audio (such as Dolby Digital, MP3 and AAC), digital television (such as SDTV, HDTV and VOD), digital radio (such as AAC+ and DAB+), and speech coding (such as AAC-LD, Siren and Opus). DCTs are also important to numerous other applications in science and engineering, such as digital signal processing, telecommunication devices, reducing network bandwidth usage, and spectral methods for the numerical solution of partial differential equations.
The use of cosine rather than sine functions is critical for compression, since it turns out (as described below) that fewer cosine functions are needed to approximate a typical signal, whereas for differential equations the cosines express a particular choice of boundary conditions. In particular, a DCT is a Fourier-related transform similar to the discrete Fourier transform (DFT), but using only real numbers. The DCTs are generally related to Fourier Series coefficients of a periodically and symmetrically extended sequence whereas DFTs are related to Fourier Series coefficients of only periodically extended sequences. DCTs are equivalent to DFTs of roughly twice the length, operating on real data with even symmetry (since the Fourier transform of a real and even function is real and even), whereas in some variants the input and/or output data are shifted by half a sample. There are eight standard DCT variants, of which four are common.
The most common variant of discrete cosine transform is the type-II DCT, which is often called simply "the DCT". This was the original DCT as first proposed by Ahmed. Its inverse, the type-III DCT, is correspondingly often called simply "the inverse DCT" or "the IDCT". Two related transforms are the discrete sine transform (DST), which is equivalent to a DFT of real and odd functions, and the modified discrete cosine transform (MDCT), which is based on a DCT of overlapping data. Multidimensional DCTs (MD DCTs) are developed to extend the concept of DCT to MD signals. There are several algorithms to compute MD DCT. A variety of fast algorithms have been developed to reduce the computational complexity of implementing DCT. One of these is the integer DCT (IntDCT), an integer approximation of the standard DCT, : ix, xiii, 1, 141–304 used in several ISO/IEC and ITU-T international standards.
Notable settings
windowper = period for calculation, restricted to powers of 2: "16", "32", "64", "128", "256", "512", "1024", "2048", this reason for this is FFT is an algorithm that computes DFT (Discrete Fourier Transform) in a fast way, generally in 𝑂(𝑁⋅log2(𝑁)) instead of 𝑂(𝑁2). To achieve this the input matrix has to be a power of 2 but many FFT algorithm can handle any size of input since the matrix can be zero-padded. For our purposes here, we stick to powers of 2 to keep this fast and neat. read more about this here: Cooley–Tukey FFT algorithm
smthper = smoothing count, this smoothing happens after the first FCT regular pass. this zeros out frequencies from the previously calculated values above SS count. the lower this number, the smoother the output, it works opposite from other smoothing periods
Included
Alerts
Signals
Loxx's Expanded Source Types
Additional reading
A Fast Computational Algorithm for the Discrete Cosine Transform by Chen et al.
Practical Fast 1-D DCT Algorithms With 11 Multiplications by Loeffler et al.
Cooley–Tukey FFT algorithm
STD-Filtered Variety RSI of Double Averages w/ DSL [Loxx]STD-Filtered Variety RSI of Double Averages w/ DSL is a standard deviation step filtered RSI indicator that is calculated using double smoothing. The user can choose from 8 different RSI types and 38 different double smoothing types. This indicator uses Discontinued Signal Lines instead of regular signals and levels. This allows the signals to be more precise in catching early trend breakouts and breakdowns.
Things to note
Double smoothing of the source does not function like DEMA, for example. This double smoothing is just smoothing of smoothing of source
There are two types of smoothing for Discontinued Signals Lines: Regular EMA and Fast EMA
T3 RSI has been added on top of Loxx's Variety RSI library
Contained inside this indicator
Loxx's Moving Averages
Loxx's Variety RSI
Related indicators
Corrected RSI w/ Floating Levels
Adaptive, Jurik-Filtered, Floating RSI
Variety RSI w/ Dynamic Zones
Included
Bar coloring
Alerts
2 types of signals with precision adjustment
Loxx's Variety RSI
Loxx's Moving Averages
MTF VWAP & StDev BandsMulti Timeframe Volume Weighted Average Price with Standard Deviation Bands
I used the script "Koalafied VWAP D/W/M/Q/Y" by Koalafied_3 and made some changes, such as adding more standard deviation bands.
The script can display the daily, weekly, monthly, quarterly and yearly VWAP.
Standard deviation bands values can be changed (default values are 0.618, 1, 1.618, 2, 2.618, 3).
Also the previous standard deviation bands can be displayed.

EMA-Deviation-Corrected Super Smoother [Loxx]This indicator is using the modified "correcting" method. Instead of using standard deviation for calculation, it is using EMA deviation and is applied to Ehlers' Super Smoother.
What is EMA-Deviation?
By definition, the Standard Deviation (SD, also represented by the Greek letter sigma σ or the Latin letter s) is a measure that is used to quantify the amount of variation or dispersion of a set of data values. In technical analysis we usually use it to measure the level of current volatility.
Standard Deviation is based on Simple Moving Average calculation for mean value. This version is not doing that. It is, instead, using the properties of EMA to calculate what can be called a new type of deviation, and since it is based on EMA. It is similar to Standard Deviation, but on a first glance you shall notice that it is "faster" than the Standard Deviation and that makes it useful when the speed of reaction to volatility is expected from any code or trading system.
What is Ehlers Super Smoother?
The Super Smoother filter uses John Ehlers’s “Super Smoother” which consists of a a Two-pole Butterworth filter combined with a 2-bar SMA (Simple Moving Average) that suppresses the 22050 Hz Nyquist frequency: A characteristic of a sampler, which converts a continuous function or signal into a discrete sequence.
Things to know
The yellow and fuchsia thin line is the original Super Smoother
The green and red line is the Corrected Super Smoother
When the original Super Smoother crosses above the Corrected Super Smoother line, its a long, when it crosses below, its a short
Included
Alerts
Signals
Bar coloring

vol_boxA simple script to draw a realized volatility forecast, in the form of a box. The script calculates realized volatility using the EWMA method, using a number of periods of your choosing. Using the "periods per year", you can adjust the script to work on any time frame. For example, if you are using an hourly chart with bitcoin, there are 24 periods * 365 = 8760 periods per year. This setting is essential for the realized volatility figure to be accurate as an annualized figure, like VIX.
By default, the settings are set to mimic CBOE volatility indices. That is, 252 days per year, and 20 period window on the daily timeframe (simulating a 30 trading day period).
Inside the box are three figures:
1. The current realized volatility.
2. The rank. E.g. "10%" means the current realized volatility is less than 90% of realized volatility measures.
3. The "accuracy": how often price has closed within the box, historically.
Inputs:
stdevs: the number of standard deviations for the box
periods to project: the number of periods to forecast
window: the number of periods for calculating realized volatility
periods per year: the number of periods in one year (e.g. 252 for the "D" timeframe)

Adaptive-LB, Jurik-Filtered, Triangular MA w/ Price Zones [Loxx]Adaptive-LB, Jurik-Filtered, Triangular MA w/ Price Zones is a moving average indicator that takes as its input an adaptive lookback period. This is an experimental indicator and I wouldn't use this for trading. It's more to explore different adaptive calculation methods and their applications to moving averages and channels. Unlike the traditional Triangular Moving Average, this one uses Jurik smoothing.
What is the Triangular Moving Average
The Triangular Moving Average is basically a double-smoothed Simple Moving Average that gives more weight to the middle section of the data interval. The TMA has a significant lag to current prices and is not well-suited to fast moving markets. TMA = SUM (SMA values)/ N Where N = the number of periods.
What is Jurik Volty used in the Juirk Filter?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Included:
Bar coloring
Signals
Alerts
STD-Adaptive T3 Channel w/ Ehlers Swiss Army Knife Mod. [Loxx]STD-Adaptive T3 Channel w/ Ehlers Swiss Army Knife Mod. is an adaptive T3 indicator using standard deviation adaptivity and Ehlers Swiss Army Knife indicator to adjust the alpha value of the T3 calculation. This helps identify trends and reduce noise. In addition. I've included a Keltner Channel to show reversal/exhaustion zones.
What is the Swiss Army Knife Indicator?
John Ehlers explains the calculation here: www.mesasoftware.com
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types

Corrected JMA [Loxx]This indicator uses the Juirk Moving Average to calculate price deviations from the JMA and if the changes are not significant, then the value is "flattened". That way we can easily see both trends and potential chop zones. This uses the regular JMA as a trigger.
What is Jurik Volty used in the Juirk Filter?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Included:
Bar coloring

STD-Stepped VIDYA w/ Quantile Bands [Loxx]STD-Stepped VIDYA w/ Quantile Bands is a VIDYA moving average with Standard Deviation step filtering on either/neither/both price and VIDYA. Also included are quantile bands to identify breakouts/breakdowns/reversals.
What is VIDYA?
Variable Index Dynamic Average Technical Indicator ( VIDYA ) was developed by Tushar Chande. It is an original method of calculating the Exponential Moving Average ( EMA ) with the dynamically changing period of averaging.
What is Quantile Bands?
In statistics and the theory of probability, quantiles are cutpoints dividing the range of a probability distribution into contiguous intervals with equal probabilities, or dividing the observations in a sample in the same way. There is one less quantile than the number of groups created. Thus quartiles are the three cut points that will divide a dataset into four equal-size groups ( cf . depicted example). Common quantiles have special names: for instance quartile, decile (creating 10 groups: see below for more). The groups created are termed halves, thirds, quarters, etc., though sometimes the terms for the quantile are used for the groups created, rather than for the cut points.
q-Quantiles are values that partition a finite set of values into q subsets of (nearly) equal sizes. There are q − 1 of the q-quantiles, one for each integer k satisfying 0 < k < q. In some cases the value of a quantile may not be uniquely determined, as can be the case for the median (2-quantile) of a uniform probability distribution on a set of even size. Quantiles can also be applied to continuous distributions, providing a way to generalize rank statistics to continuous variables. When the cumulative distribution function of a random variable is known, the q-quantiles are the application of the quantile function (the inverse function of the cumulative distribution function) to the values {1/q, 2/q, …, (q − 1)/q}.
Included:
3 types of signal options
Alerts
Bar coloring
Loxx's Expanded Source Types
Dynamic Zone of Bollinger Band Stops Line [Loxx]Dynamic Zone of Bollinger Band Stops Line is a Bollinger Band indicator with Dynamic Zones. This indicator serves as both a trend indicator and a dynamic stop-loss indicator.
What are Bollinger Bands?
A Bollinger Band is a technical analysis tool defined by a set of trendlines plotted two standard deviations (positively and negatively) away from a simple moving average (SMA) of a security's price, but which can be adjusted to user preferences.
Bollinger Bands were developed and copyrighted by famous technical trader John Bollinger, designed to discover opportunities that give investors a higher probability of properly identifying when an asset is oversold or overbought.
What are Dynamic Zones?
As explained in "Stocks & Commodities V15:7 (306-310): Dynamic Zones by Leo Zamansky, Ph .D., and David Stendahl"
Most indicators use a fixed zone for buy and sell signals. Here’ s a concept based on zones that are responsive to past levels of the indicator.
One approach to active investing employs the use of oscillators to exploit tradable market trends. This investing style follows a very simple form of logic: Enter the market only when an oscillator has moved far above or below traditional trading lev- els. However, these oscillator- driven systems lack the ability to evolve with the market because they use fixed buy and sell zones. Traders typically use one set of buy and sell zones for a bull market and substantially different zones for a bear market. And therein lies the problem.
Once traders begin introducing their market opinions into trading equations, by changing the zones, they negate the system’s mechanical nature. The objective is to have a system automatically define its own buy and sell zones and thereby profitably trade in any market — bull or bear. Dynamic zones offer a solution to the problem of fixed buy and sell zones for any oscillator-driven system.
An indicator’s extreme levels can be quantified using statistical methods. These extreme levels are calculated for a certain period and serve as the buy and sell zones for a trading system. The repetition of this statistical process for every value of the indicator creates values that become the dynamic zones. The zones are calculated in such a way that the probability of the indicator value rising above, or falling below, the dynamic zones is equal to a given probability input set by the trader.
To better understand dynamic zones, let's first describe them mathematically and then explain their use. The dynamic zones definition:
Find V such that:
For dynamic zone buy: P{X <= V}=P1
For dynamic zone sell: P{X >= V}=P2
where P1 and P2 are the probabilities set by the trader, X is the value of the indicator for the selected period and V represents the value of the dynamic zone.
The probability input P1 and P2 can be adjusted by the trader to encompass as much or as little data as the trader would like. The smaller the probability, the fewer data values above and below the dynamic zones. This translates into a wider range between the buy and sell zones. If a 10% probability is used for P1 and P2, only those data values that make up the top 10% and bottom 10% for an indicator are used in the construction of the zones. Of the values, 80% will fall between the two extreme levels. Because dynamic zone levels are penetrated so infrequently, when this happens, traders know that the market has truly moved into overbought or oversold territory.
Calculating the Dynamic Zones
The algorithm for the dynamic zones is a series of steps. First, decide the value of the lookback period t. Next, decide the value of the probability Pbuy for buy zone and value of the probability Psell for the sell zone.
For i=1, to the last lookback period, build the distribution f(x) of the price during the lookback period i. Then find the value Vi1 such that the probability of the price less than or equal to Vi1 during the lookback period i is equal to Pbuy. Find the value Vi2 such that the probability of the price greater or equal to Vi2 during the lookback period i is equal to Psell. The sequence of Vi1 for all periods gives the buy zone. The sequence of Vi2 for all periods gives the sell zone.
In the algorithm description, we have: Build the distribution f(x) of the price during the lookback period i. The distribution here is empirical namely, how many times a given value of x appeared during the lookback period. The problem is to find such x that the probability of a price being greater or equal to x will be equal to a probability selected by the user. Probability is the area under the distribution curve. The task is to find such value of x that the area under the distribution curve to the right of x will be equal to the probability selected by the user. That x is the dynamic zone.
Included
Bar coloring
Signals
Alerts
3 types of signal smoothing

Visible Range Mean Deviation Histogram [LuxAlgo]This script displays a histogram from the mean and standard deviation of the visible price values on the chart. Bin counting is done relative to high/low prices instead of counting the price values within each bin, returning a smoother histogram as a result.
Settings
Bins Per Side: Number of bins computed above and below the price mean
Deviation Multiplier: Standard deviation multiplier
Style
Relative: Determines whether the bins length is relative to the maximum bin count, with a length controlled with the width settings to the left.
Bin Colors: Bin/POC Lines colors
Show POCs: Shows point of controls
Usage
Histograms are generally used to estimate the underlying distribution of a series of observations, their construction is generally done taking into account the overall price range.
The proposed histogram construct N intervals above*below the mean of the visible price, with each interval having a size of: σ × Mult / N , where σ is the standard deviation and N the number of Bins per side and is determined by the user. The standard deviation multipliers are highlighted at the left side of each bin.
A high bin count reflects a higher series of observations laying within that specific interval, this can be useful to highlight ranging price areas.
POCs highlight the most significant bins and can be used as potential support/resistances.

[Sidders]Std. Deviation from Mean/MA (Z-score)This indicator visualizes in a straight forward way the distance price is away from the mean in absolute standard deviations (Z-score) over a certain lookback period (can be configured). Additionally I've included a moving average of the distance, the MA type can be configured in the settings.
Personally using this indicator for some of my algo mean reversion strategies. Price reaching the extreme treshold (can be configured in settings, standard is 3) could be seen as a point where price will revert to the mean.
I've included alerts for when price crosses into extreme areas, as well as alerts for when crosses back into 'normal' territory again. Both are also plotted on the indicator through background coloring/shapes.
Since I've learned so much from other developers I've decided to open source the code. Let me know if you have any ideas on how to improve, I'll see if I can implement them.
Enjoy!
Volatility Ratio Adaptive RSX [Loxx]Volatility Ratio Adaptive RSX this indicator adds volatility ratio adapting and speed value to RSX in order to make it more responsive to market condition changes at the times of high volatility, and to make it smoother in the times of low volatility
What is RSX?
RSI is a very popular technical indicator, because it takes into consideration market speed, direction and trend uniformity. However, the its widely criticized drawback is its noisy (jittery) appearance. The Jurik RSX retains all the useful features of RSI, but with one important exception: the noise is gone with no added lag.
Included:
-Toggle on/off bar coloring

STD-Stepped, CFB-Adaptive Jurik Filter w/ Variety Levels [Loxx]STD-Stepped, CFB-Adaptive Jurik Filter w/ Variety Levels is a Composite Fractal Behavior, single/double Jurik filter with floating boundary levels, alerts, and signals.
What is Composite Fractal Behavior ( CFB )?
All around you mechanisms adjust themselves to their environment. From simple thermostats that react to air temperature to computer chips in modern cars that respond to changes in engine temperature, r.p.m.'s, torque, and throttle position. It was only a matter of time before fast desktop computers applied the mathematics of self-adjustment to systems that trade the financial markets.
Unlike basic systems with fixed formulas, an adaptive system adjusts its own equations. For example, start with a basic channel breakout system that uses the highest closing price of the last N bars as a threshold for detecting breakouts on the up side. An adaptive and improved version of this system would adjust N according to market conditions, such as momentum, price volatility or acceleration.
Since many systems are based directly or indirectly on cycles, another useful measure of market condition is the periodic length of a price chart's dominant cycle, (DC), that cycle with the greatest influence on price action.
The utility of this new DC measure was noted by author Murray Ruggiero in the January '96 issue of Futures Magazine. In it. Mr. Ruggiero used it to adaptive adjust the value of N in a channel breakout system. He then simulated trading 15 years of D-Mark futures in order to compare its performance to a similar system that had a fixed optimal value of N. The adaptive version produced 20% more profit!
This DC index utilized the popular MESA algorithm (a formulation by John Ehlers adapted from Burg's maximum entropy algorithm, MEM). Unfortunately, the DC approach is problematic when the market has no real dominant cycle momentum, because the mathematics will produce a value whether or not one actually exists! Therefore, we developed a proprietary indicator that does not presuppose the presence of market cycles. It's called CFB (Composite Fractal Behavior) and it works well whether or not the market is cyclic.
CFB examines price action for a particular fractal pattern, categorizes them by size, and then outputs a composite fractal size index. This index is smooth, timely and accurate
Essentially, CFB reveals the length of the market's trending action time frame. Long trending activity produces a large CFB index and short choppy action produces a small index value. Investors have found many applications for CFB which involve scaling other existing technical indicators adaptively, on a bar-to-bar basis.
What is Jurik Volty used in the Juirk Filter?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Ideally, you would like a filtered signal to be both smooth and lag-free. Lag causes delays in your trades, and increasing lag in your indicators typically result in lower profits. In other words, late comers get what's left on the table after the feast has already begun.
Included:
-Color bars
-Color background
-Color trend
-Color deadzones
-Show signals
-Long/short alerts
-ATR and quantile based levels

ALMA stdev band with fibsArnaud Legoux Moving Average with standard deviation band and standard deviation Fibonacci levels.
Standard deviation band is alma + stdev and alma - stdev.
Fibonacci levels are alma + stdev * fib ratio and alma - stdev * fib ratio (0.382 / 0.5 / 0.618 / 1.618 / 2.618).
Used like a moving average, but also shows probable price range based on past volatility, and helps to recognize support/resistance levels, trends and trend momentum based on the Fibonacci levels.
STD Stepped Ehlers Optimal Tracking Filter MTF w/ Alerts [Loxx]STD Stepped Ehlers Optimal Tracking Filter MTF w/ Alerts is the traditional Ehlers Optimal Tracking Filter but with stepped price levels, access to multiple time frames, and alerts.
What is Ehlers Optimal Tracking Filter?
From "OPTIMAL TRACKING FILTERS" by John Ehlers:
"Dr. R.E. Kalman introduced his concept of optimum estimation in 1960. Since that time, his technique has proven to be a powerful and practical tool. The approach is particularly well suited for optimizing the performance of modern terrestrial and space navigation systems. Many traders not directly involved in system analysis have heard about Kalman filtering and have expressed an interest in learning more about it for market applications. Although attempts have been made to provide simple, intuitive explanations, none has been completely successful. Almost without exception, descriptions have become mired in the jargon and state-space notation of the “cult”.
Surprisingly, in spite of the obscure-looking mathematics (the most impenetrable of which can be found in Dr. Kalman’s original paper), Kalman filtering is a fairly direct and simple concept. In the spirit of being pragmatic, we will not deal with the full-blown matrix equations in this description and we will be less than rigorous in the application to trading. Rigorous application requires knowledge of the probability distributions of the statistics. Nonetheless we end with practically useful results. We will depart from the classical approach by working backwards from Exponential Moving Averages. In this process, we introduce a way to create a nearly zero lag moving average. From there, we will use the concept of a Tracking Index that optimizes the filter tracking for the given uncertainty in price movement and the uncertainty in our ability to measure it."
Included:
-Standard deviation stepping filter, price is required to exceed XX deviations before the moving average line shifts direction
-Selection of filtering based on source price, the moving average, or both; you can also set the Filter deviations to 0 for no filtering at all
-Toggle on/off bar coloring
-Toggle on/off signals
-Long/Short alerts
VWAP Suite█ OVERVIEW
This indicator is an attempt to bring all VWAP functionalities under one umbrella suite, the existing VWAPs are great and this was made to provide all functionalities. (pending more updates as well)
█ FEATURES
Multiple VWAPs MTF
Individual Band configuration
Previous vwap closes
Date tracking of previous closes
MTF Options
Enabling the other VWAPS with any timeframe will allow the user to use the "VWAP Anchor" setting to choose what HTF Vwap to be displayed
"Prev Close"
This setting enables all historical closes to be displayed with extension
"Track Dates"
Can be used to keep date information of 2 previous closes and further back
█ HOW TO USE IT
The indicator is quite straight forward in its application, as you would expect of a normal VWAP.
At the top of the settings pane the indicator has some functionality that would control the VWAPs globally, e.g. disabling show bands disables all bands for all the VWAPs.
Each VWAP has individual settings that can be controlled such as coloring, which bands enabled, previous closes, labelling...
█ SUGGESTION
My suggestion for clarity is to use 1 VWAP with bands, and a 2nd with no bands + Previous close enabled at a higher timeframe
█ LIMITATIONS OF PINE (Please read)
I see many users going on different indicators with MTF in mind and trying to use it for LTF data e.g. 1hour chart, and selecting 5min in chart settings.
This is not recommended by the team themselves and should be noted for use always use HTF: www.tradingview.com
To understand how to use VWAP please refer to some education that can be found for free online
Heres an example of a trader using the tool himself: www.youtube.com
█ Future Updates:
Previous Close Line extensions
Previous Highs and Lows of VWAP mapped out for users
Suggestions Welcome!

Standard Deviation Refurbished█ Standard Deviation Refurbished
This is an indicator that serves to show the standard deviation in a more improved and less trivial form.
Basically, I put the option to normalize the indicator in a range of 0 to 100.
I also put 10 moving averages of standard deviation.
In the graphic part was placed the choice of themes.
Gratitude to the author 'The_Caretaker' by the themes 'Spectrum Blue-Green-Red' and 'Spectrum Blue-Red'.
█ Concepts
"Standard Deviation is a way to measure price volatility by relating a price range to its moving average. The higher the value of the indicator, the wider the spread between price and its moving average, the more volatile the instrument and the more dispersed the price bars become. The lower the value of the indicator, the smaller the spread between price and its moving average, the less volatile the instrument and the closer to each other the price bars become. Standard Deviation is used as part of other indicators such as Bollinger Bands. It is often used in combination with other signals and analysis techniques."
(TradingView)

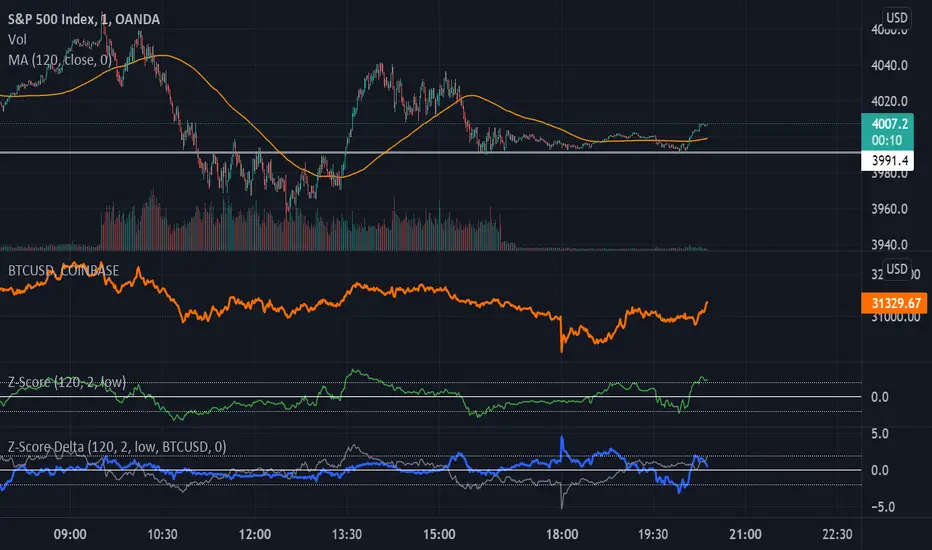
Z-Score DeltaHeavily modified from Z Score by jwammo12
Compares the z-score of two assets, the onscreen one and the reference one configured. If you're familiar, you can think of it as Bollinger Band Percent of Onscreen Asset minus the Bollinger Band Percent of Reference Asset.
It's compared off a simple moving average, due to how standard deviation is calculated.
I view this a more literal meaning of relative strength.
Has the ability to offset or delay in time one to another.
TODO: add MAD and MAD/STD.DEV views
Not my greatest work, but it's functional.