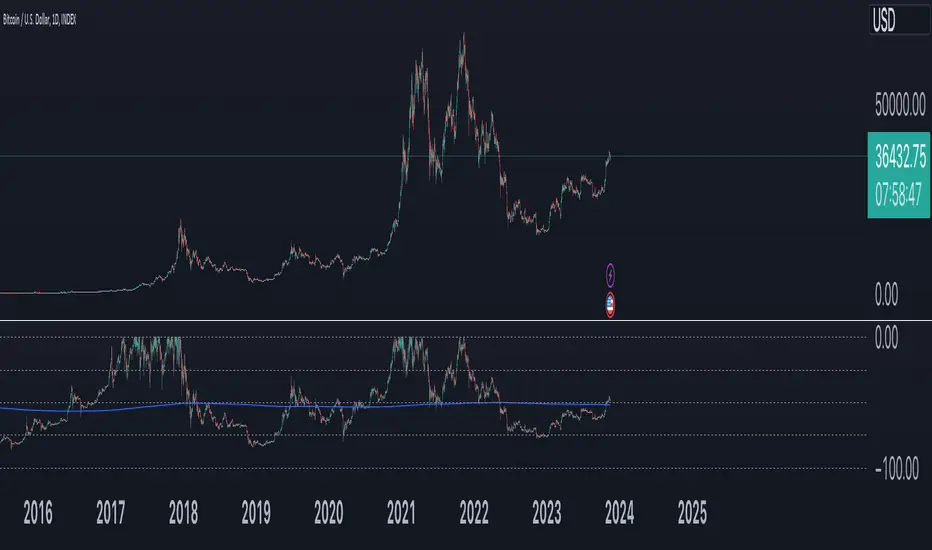
VaR Market Sentiment by TenozenHello there! I am excited to share with you my new trading concept implemented in the "VaR Market Sentiment" indicator. But before that, let me explain what VaR is. VaR, or Value at Risk, is an indicator that helps you identify the worst-case scenario of a market movement based on a percentile/confidence level. This means that it calculates the worst moves, whether it's a buy or sell, based on the timeframe you're using.
Now, let's discuss how VaR Market Sentiment works. It uses a historical VaR to calculate the worst move either if the market goes up or down based on a percentile/confidence level. The default setting is the 95th percentile, which means that the market is unlikely to hit your SL level within the day if you're using a daily timeframe, etc.
To determine the strength of a candle, it subtracts the value of both sides based on the returns of the current timeframe with the VaR value (Bullish VaR - Bullish Returns, Bearish VaR - Bearish Returns). If the result is above the mean, the current candle is potentially weak. Conversely, if the result is below the mean, the current candle is potentially strong. The deviation shows critical sentiments, where if the market is above the deviation, it means that the current candle is really weak. If it's below the deviation, it means that the current candle is really strong.
It's important to note that this indicator needs other supporting indicators such as trend-following or mean reversion indicators based on your trading style. Also, as a follow-up to my previous concept, I called out that the market has what's called "power." And for now, I conclude that VaR Market Sentiment is the "power."
I'm going to share more helpful indicators in the future! I hope this indicator will be helpful for you guys! Ciao!
Statistics
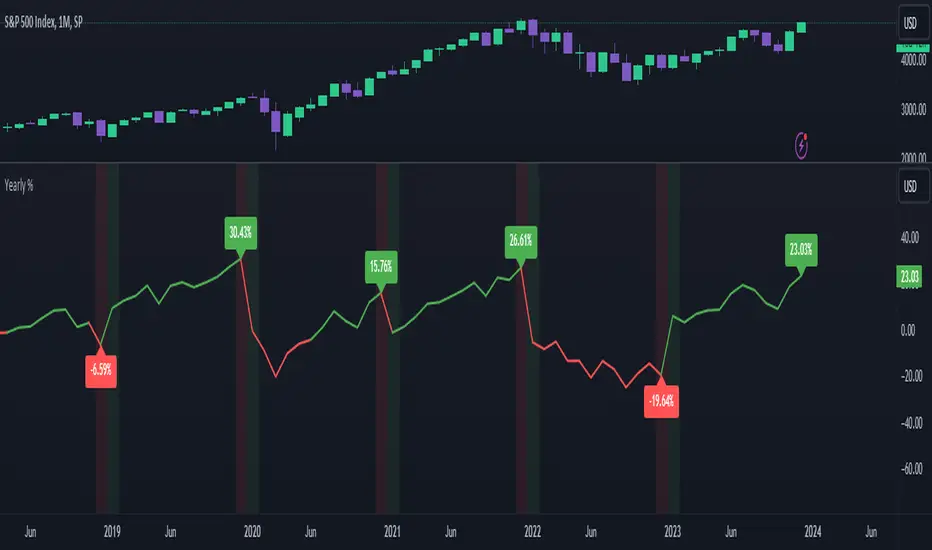
Yearly Return [%] - VisualizedCalculates the % Return from the first trading candle of any given year, and shows the % Return at that year end.
FX Forecasting Model [TrendX_]FX Forecasting Model indicator is a forecasting tool that takes advantages of macroeconomic analysis and market surveillance to predict Exchange rate movement.
*** Customize the macro data for home country (base currency) and foreign country
USAGE
This consists of 4 editable options align with 4 Forecasting Models
TrendX Model)
TrendX Model is a type of multiple linear regression, which is a statistical method that estimates the relationship between the currency exchange rate and various macroeconomic indicators.
*** Remember the 1st thing to do is to customize the macro data for home country (base currency) and foreign country, before take any further steps.
Purchasing Power Parity (PPP Model)
The PPP model is a conceptual model of currency exchange. The model illustrates how the exchange rate between two countries’ currencies is influenced by the variations in the prices of goods and services in those countries, which depend on the inflation rate. The activity of buying and selling goods and services internationally will shift the exchange rate to balance the prices in both countries.
Interest Rate Parity (IRP Model)
Interest Rate Parity (IRP) model is a theoretical model that relates the interest rates and the exchange rates of two countries. According to IRP, the difference between the forward and spot exchange rates of two currencies should be equal to the difference between their interest rates. IRP helps traders to determine the fair value of a currency pair and compare it with the market value. If the market value deviates from the fair value, then there is a potential for arbitrage or hedging.
Combined Forecast Model (Mixed Model)
Since each model has its own advantages, many people are interested in the concept of using a mix of forecasts to get better results than any single forecast. Mix Model is a method that uses different proportions of the forecasts from three models: TrendX, PPP and IRP models. The default proportion is 0.2 for TrendX, and 0.4 for both PPP and IRP. You can change these proportions according to your liking.
CONCLUSION
FX Forecasting Model Indicator is very practical for FOREX traders who wants to make informed and rational decisions based on Macroeconomic Analysis. It can help find arbitrage opportunity in currency exchange market. Accordingly, it can also be helpful for traders to use alongside other forms of Technical Analysis.
DISCLAIMER
The results achieved in the past are not all reliable sources of what will happen in the future. There are many factors and uncertainties that can affect the outcome of any endeavor, and no one can guarantee or predict with certainty what will occur.
Therefore, you should always exercise caution and judgment when making decisions based on past performance.

Normalized Fisher Transformed VolumeGreetings Traders,
I am thrilled to introduce a game-changing tool that I've passionately developed to enhance your trading precision – the Normalized Fisher Transformed Volume indicator. Let's dive into the specifics and explore how this tool can empower you in the markets.
Unlocking Trading Precision:
Normalization and Transformation:
Normalize raw volume data to ensure a consistent scale for analysis.
The Fisher Transformation converts normalized volume data into a Gaussian distribution, providing enhanced insights into trend dynamics.
Flexible Modes for Tailored Strategies:
Choose from three distinct modes:
Volume T3 (MA) + Heatmap: Identify trends with T3 Moving Average and visualize volume strength with Heatmap.
Volume Percent Rank: Evaluate the position of current volume relative to historical data.
Volume T3 (MA) Percent Rank: Combine T3 Moving Average with percentile ranking for a comprehensive analysis.
Heatmap Visualization for Quick Insights:
Heatmap Zones and Lines visually represent volume strength relative to historical data.
Customize threshold multipliers and color options for precise Heatmap interpretation.
T3 Moving Average Integration:
Smoothed representation of volume trends with the T3 Moving Average enhances trend identification.
Percent Rank Analysis for Context:
Gauge the position of normalized volume within historical context using Percent Rank analysis.
User-Friendly Customization:
Easily adjust parameters such as length, T3 Moving Average length, Heatmap standard deviation length, and threshold multipliers.
Intuitive interface with colored bars and customizable background options for personalized analysis.
How to Use Effectively:
Mode Selection:
Identify your preferred trading strategy and select the mode that aligns with your approach.
Parameter Adjustment:
Fine-tune the indicator by adjusting parameters to match your preferred trading style.
Interpret Heatmap and T3 Analysis:
Leverage Heatmap and T3 Moving Average analysis to spot potential trend reversals, overbought/oversold conditions, and market sentiment shifts.
Conclusion:
The Normalized Fisher Transformed Volume indicator is not just a tool; it's your key to unlocking precision in trading. Crafted by Simwai, this indicator offers unique insights tailored to your specific trading needs. Dive in, explore its features, experiment with parameters, and let it guide you to more informed and precise trading decisions.
Trade wisely and prosper,
simwai

commonThe "Pineify/common" library presents a specialized toolkit crafted to empower traders and script developers with state-of-the-art time manipulation functions on the TradingView platform. It is instead a foundational utility aimed at enriching your script's ability to process and interpret time-based data with unparalleled precision.
Key Features
String Splitter:
The 'str_split_into_two' function is a universal string handler that separates any given input into two distinct strings based on a specified delimiter. This function is especially useful in parsing time strings or any scenario where a string needs to be divided into logical parts efficiently.
Example:
= str_split_into_two("a:b", ":")
// a = "a"
// b = "b"
Time Parser:
With 'time_to_hour_minute', users can effortlessly convert a time string into numerical hours and minutes. This function is pivotal for those who need to exact specific time series data or wish to schedule their trades down to the minute.
Example:
= time_to_hour_minute("02:30")
// time_hour = 2
// time_minute = 30
Unix Time Converter
The 'time_range_to_unix_time' function transcends traditional boundaries by converting a given time range into Unix timestamp format. This integration of date, time, and timezone, accounts for a comprehensive approach, allowing scripts to make timed decisions, perform historical analyses, and account for international markets across different time zones.
Example:
// Support 'hhmm-hhmm' and 'hh:mm-hh:mm'
= time_range_to_unix_time("09:30-12:00")
Summary:
Each function is meticulously designed to minimize complexity and maximize versatility. Whether you are a programmer seeking to streamline your code, or a trader requiring precise timing for your strategies, our library provides the logical framework that aligns with your needs.
The "Pineify/common" library is the bridge between high-level time concepts and actionable trading insights. It serves a multitude of purposes – from crafting elegant time-based triggers to dissecting complex string data. Embrace the power of precision with "Pineify/common" and elevate your TradingView scripting experience to new heights.
Price Volume Harmony Indicator [Nasan]The indicator "Price Volume Harmony Indicator " (abbreviated as PVHI) combines relative volume intensity (RVI) and relative price change (PC) to identify potential synergy or divergence between price and volume movements. Let's break down the key components and discuss how to interpret the output:
Relative Volume Intensity (RVI):
It calculates the mean volume intensity using simple moving averages (SMA) of different periods (5, 8, 13, and 144).
It then computes point volume intensity based on the current volume compared to the previous bar's volume.
The final RVI is a combination of mean and point volume intensities.
Relative Price Change (PC):
It calculates the median absolute deviation (MAD) and the price change relative to MAD for three different lengths (5, 8, and 13).
The average relative PC is a weighted combination of the three PC values.
Normalization:
RVI and PC are normalized using Z-scores (standard scores) to bring them to the same scale. This enables easier comparison.
Histogram Plotting:
The RVI and PC are plotted as histograms below the main price chart. Green color bars represent RVI, and blue color bars indicate PC. The RVI bars are light green when the RVI values are decreasing compared to previous bar. Similarly, when PC bars are light blue it indicates that the PC values are decreasing compared to previous bars.
There is a zero line +/- 0.5 SD lines movements above and below the SD lines are practically
significant.
Interpretation :
(1) Strong Bullish Movement :
This is when both the green bars (RVI) and blue bars (PC) increases and are on the same side above zero .
(2) Strong Bearish Movement :
This is when the green bars (RVI) increases and blue bars (PC) decreases. The green bars above zero but blue bars below zero.
(3) Weak Bullish Movement :
This is when the green bars (RVI) decreases and are below zero but the blue bars (PC) increases and are above zero .
(2) Weak Bearish Movement :
This is when both the green bars (RVI) and blue bars (PC) decreases. The green bars and blue bars are below zero.
This output is slightly hard to read but with practice can be read easily.

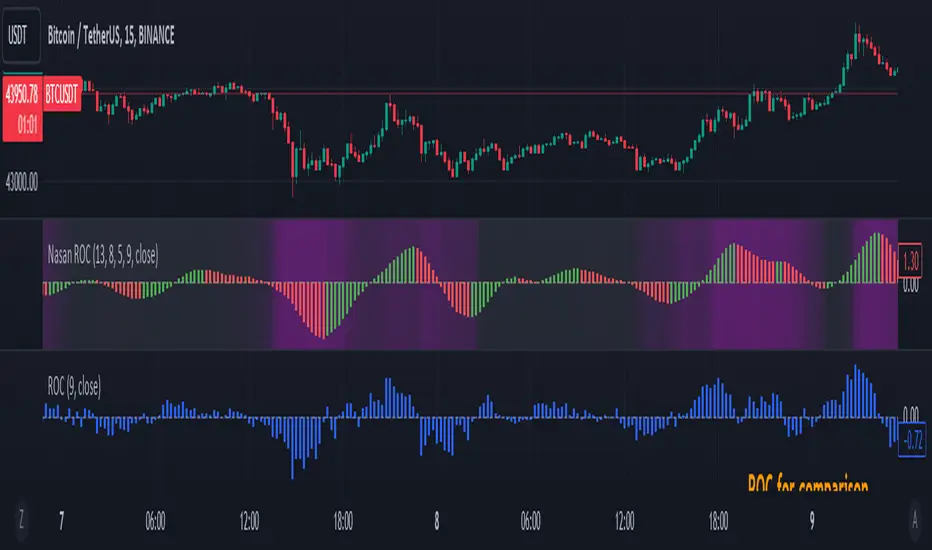
Nasan Rate of Change (ROC)**NOTE: FOR COMPARISON TRADITIONAL ROC IS PLOTTED WITH THE SAME ROC LENGTH OF 9. IT IS NOT PART OF THE INDICATOR"
The Nasan ROC indicator is smoothed version of the of the traditional ROC indicator. The Nasna ROC uses a triple pass moving average differencing strategy. A cumulative sum of the deviations obtained from the moving average differencing provides a smooth "noise free" trend and this cumulative sum of deviations is used for calculating ROC.
Let's break down the components and understand the indicator we discussed earlier:
Sequential Triple Pass Filter:
Three filters with lengths specified by length1, length2, and length3 are applied to the closing prices (close).
The filters involve calculating the cumulative sum of the differences between the closing prices and their respective moving averages.
The idea is to detrend the data and accumulate the deviations from the average over time, emphasizing longer-term trends.
Calculation of Rate of Change (ROC) of Cumulative Sum:
The Rate of Change (ROC) of the cumulative sum (rocCumulativeSum) is calculated using the ta.roc function with a specified length (rocLength).
ROC measures the percentage change in the cumulative sum over a specified period.
The ROC histogram provides insights into the momentum of the detrended series. Positive values suggest increasing momentum, while negative values suggest decreasing momentum.
Pay attention to the color of the histogram bars.
The histogram bars are colored green if the current ROC value is greater than or equal to the previous ROC value, and red otherwise.
This coloring is based on the concept that a positive ROC suggests upward momentum, while a negative ROC suggests downward momentum.
Volatility - Volume Impact:
The Average True Range (ATR) is calculated with a period of 14.
Volume strength is calculated as a factor (VCF) that considers the ratio of the simple moving average (SMA) of the current volume to the SMA of the volume over a longer period (144).
This volume factor (VCF) is then multiplied by ATR, creating a synergy with volatility and volume.
Visualization with Background Color Gradient:
A background color gradient is applied to the chart based on the calculated volume strength (f1).
The gradient color ranges from black (indicating low ATR and volume strength) to purple (indicating high ATR and volume strength). A low value indicates a ranging market with no significant price movements and it is safter to avoid signals generated from ROC histogram in these region.
Synergy of ROC and Volume Strength:
Observe how the ROC signals align with the background color gradient. For example, confirm whether positive ROC aligns with periods of high ATR and volume strength.
This synergy can provide confirmation or divergence signals, adding another layer of analysis.
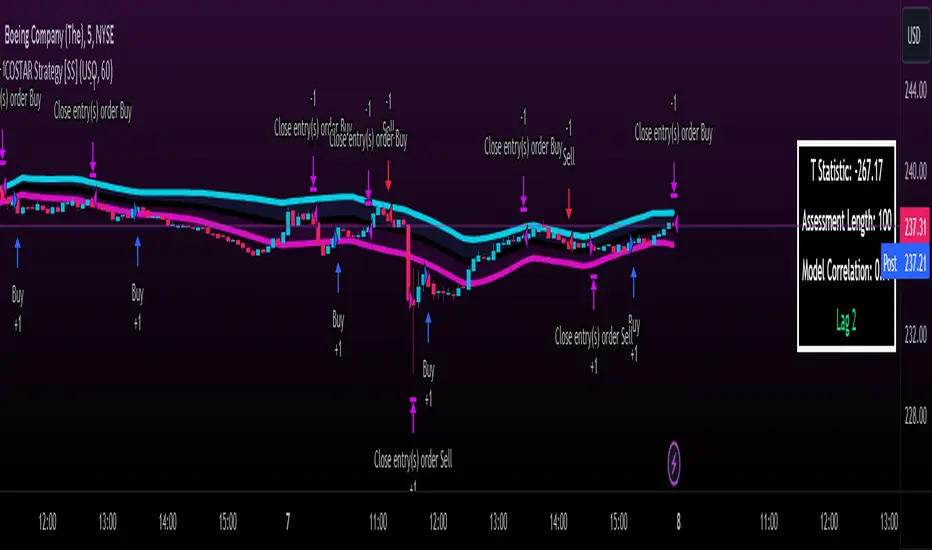
COSTAR Strategy [SS]A little late posting this but here it is, as promised!
This is the companion to the COSTAR indicator.
What it does:
It creates a co-integration paired relationship with a separate, cointegrated ticker. It then plots out the expected range based on the value of the cointegrated pair. When the current ticker is below the value of its co-integrated partner, it becomes a "Buy" and should be longed. When it becomes overvalued in comparison, it becomes a "Sell" and should be shorted.
The example above is with BA and USO, which have a strong inverse relationship.
How it works:
I made the strategy version a bit more intuitive. Instead of you selecting the parameters for your model, it will autoselect the ideal parameters based on your desired co-integrated pair. You simply enter the ticker you want to compare against, and it will sort through the values at various lags to find significance and stationarity. It will then create a model and plot the model out for you on your chart, as you can see above.
The premise of the strategy:
The premise of the strategy is as stated before. You long when the ticker is undervalued in comparison to its co-integrated pair, and short when it is overvalued. The conditions for entry are simply a co-integrated pair being over the expected range (short) or below the expected range (long).
The condition to exit is a "re-integration", or a crossover of the expected value of the ticker (the centreline).
What if it can't find a relationship?
In some instances, the indicator will not be able to determine a co-integrated relationship, owning to a lack of stationarity between the data. When this happens, you will get the following error:
The indicator provides you with prompts, such as switching the timeframe or trying an alternative ticker. In the case displayed above, if we simply switch to the 1 hour timeframe, we have a viable model with great backtest results:
You can toggle in the settings menu the various parameters, such as timeframe, fills and displays.
And that is the strategy in a nutshell, be sure to check out its partner indicator, COSTAR, for more information on the premise of using co-integrated models for trading. And let me know your questions below!
Safe trades everyone!
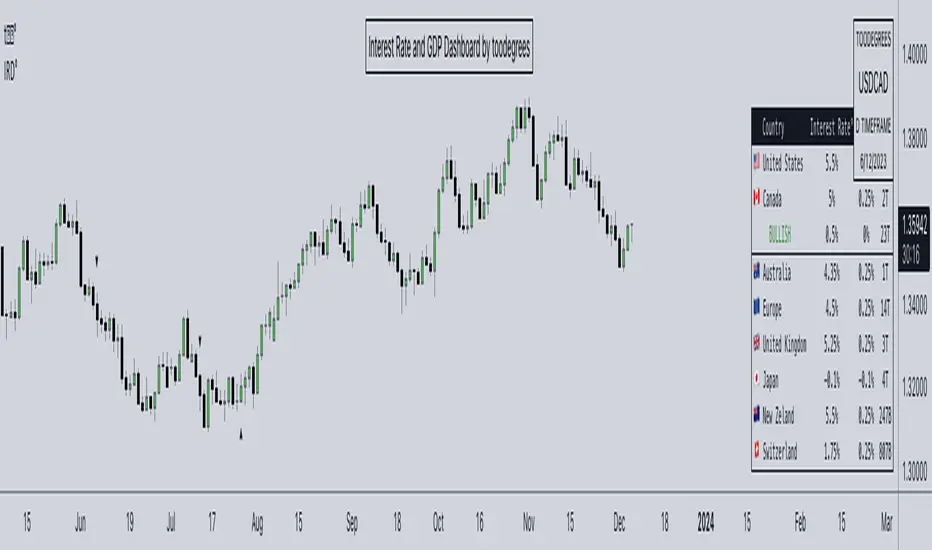
Interest Rate and GDP Dashboard by toodegreesDescription:
The Interest Rate and GDP Dashboard is a powerful tool designed to provide traders with valuable insights into Interest Rate and Gross Domestic Product (GDP) of the largest Central Banks.
Interest Rates are closely monitored from all around the world, and play a massive role in Interbank Institutional Trading. Although mainly used by Forex traders, it's important for all types of analysts to understand risk-on and risk-off environments in respective currencies, or other asset classes, based on a global financial landscape.
Forex Pair Dashboard ( FOREXCOM:EURUSD ):
Non-Forex Pair Dashboard ( CME_MINI:ES1! ):
This tool displays the Live Interest Rates (as well as latest Interest Rate Change) and GDP, of the following countries/regions:
Australia
Canada
Europe
Japan
New Zealand
Switzerland
United Kingdom
United States
Further, analysts will be able to see Interest Rate Change labels directly on chart, to monitor Time and price relationship following rate hikes or rate cuts. The labels will display according to the impact of the Interest Rate Change on the current asset on chart, and their tooltips will display the %Change:
Analysts can also choose to mark Interest Rate Changes with vertical lines, to aid in marking changes in sentiment or global financial environment:
The real power and value provided by this tool is its tailored Interest Rate (and GDP) Differential feature for Forex markets, based on the Interest Rate Differential concept as taught by the Inner Circle Trader (ICT).
Using Interest Rate Differentials as a further Long Term Bias factor was introduced by ICT in conjunction with other higher Timeframe principles like Seasonal Tendency, Commitment of Traders, and Open Interest. This fusion ensures a holistic approach to dissecting specific Forex pairs, and the involvement of Institutional traders.
Key Features:
Dynamically calculates and organizes the dashboard to display the interest rate differential of the chart's forex pair, or displays all if outside of forex markets.
Pinpoint historical interest rate changes with precision using vertical lines and/or dynamic labels with tooltips.
Other Features:
Toggle Options: Customize your viewing experience by toggling the display of previous rate changes, enabling or disabling GDP visibility, and tailoring the size and location of the dashboard.
Fine-tune Visuals: Adjust the size and style of the previous interest rate labels and lines to suit your preferences, offering a personalized touch to your analytical workspace.
Usage Guidance:
Add the Interest Rate and GDP Dashboard to your Tradingview chart.
Tailor your experience by customizing the table and style to be in line with your analytical preferences, ensuring a visually engaging and personalized chart.
Observe where and when key Interest Rate decisions impact the macro trend or market environment.
Leverage this invaluable information to shape your Higher Timeframe narrative in confluence with other tools.
Volume Outlier Signal Detector (Based on IQR)This indicator can detect outliers in trading volume using the 1.5 IQR rule or the outlier formula.
The outlier formula designates outliers based on upper and lower boundaries. Any value that is 1.5 times the Interquartile Range (IQR) greater than the third quartile is designated as an outlier.
The indicator computes the Q3 (75th percentile) and Q1 (25th percentile) of a given volume dataset. The IQR is then calculated by subtracting the Q1 volume from the Q3 volume.
To identify volume outliers, the indicator uses the formula:
Q3 Volume + IQR Multiplier(1.5) * IQR
If the trading volume surpasses the volume outlier, the indicator will display either a green or red column.
A green column indicates that the current bar volume is higher than the volume outlier, and simultaneously, the current bar close is higher than the previous bar's close. Vice versa for the red column.
Moving averages are an optional parameter that can be added to filter out instances where the indicator shows a green or red column. If this option is enabled, the indicator will not display a green column if the price is not above the moving average, and vice versa for red columns.
Several settings can be customized to personalize this indicator, such as setting the moving average filter to higher timeframes. The MA type can also be switched, and IQR settings can be adjusted to fit different markets.
This indicator only works with TradingView charts with volume data.
***Disclaimer:
Before using this indicator for actual trading, make sure to conduct a back test to ensure the strategy is not a losing one in the long run. Apply proper risk management techniques, such as position sizing and using stop loss.

Modified Box Plots
Box Plot Concept: The script creates a modified box plot where the central box represents the range within 1 standard deviation from the midpoint (hl2), which is the average of the high and low prices. The whiskers extend to cover a range of 3 standard deviations, providing a visualization of the overall price distribution.
Color Scheme: The color of the modified box plot is determined based on comparisons between the current midpoint (g) and the +/- 1 SD values of the previous candle (i and j ). If g > i , the color is green; if g < j , it's red; otherwise, it's yellow. This color scheme allows users to quickly assess the relationship between the current market conditions and recent price movements. if the mid point price is above/below +/- 1 SD values of the previous candle the price movement is considered as significant.
Plotcandle Function: The plotcandle function is employed to visualize the modified box plot. The color of the box is dynamically determined by the candleColor variable, which reflects the current market state based on the color scheme. The wicks, represented by lines extending from the box, are colored in white.
Explanation of Box and Wicks:
Box (Open and Close): In this modified box plot, the box does not represent traditional open and close prices. Instead, it signifies a range within 1 standard deviation of the midpoint (hl2), providing insight into the typical price variation around the average of the high and low.
Wicks (High and Low): The wicks extend from the box to cover a range of 3 standard deviations from the midpoint (hl2). They do not correspond to the actual high and low prices but serve as a visualization of potential outliers in the price distribution. The actual high and low prices are also plotted as green and red dots when the actual high and low prices fall outside the +/- 3SD wicks (whiskers) and also indicate the prices does not fit the distribution based on the recent price volatility.
In summary, this modified box plot offers a unique perspective on price distribution by considering standard deviations from the midpoint. The color scheme aids in quickly assessing market conditions, and the wicks provide insights into the potential presence of outliers. It's essential to understand that the box and wicks do not represent traditional open, close, high, and low prices but offer a different way to visualize and interpret intraday price movements.
Step by step explanation
Here's the step-by-step explanation:
a = ta.highest(high, 7): Calculates the highest high in the last 7 bars.
b = ta.lowest(low, 7): Calculates the lowest low in the last 7 bars.
c = ta.stdev(hl2, 7): Calculates the standard deviation of the average of high and low prices (hl2) over the last 7 bars.
d = (a - b) / c: Computes a scaling factor d based on the highest, lowest, and standard deviation. This factor is used to scale the intraday range in the next steps.
e = (high - low): Calculates the intraday range of the candle.
f = e / d: Estimates the standard deviation (f) of the intraday candle price using the scaling factor d.
g = hl2: Defines the intraday midpoint of the candle, which is the average of high and low prices.
i = g + 1 * f, j = g - 1 * f, k = g + 3 * f, l = g - 3 * f: Calculate values representing coverage of +1 SD, -1 SD, +3 SD, and -3 SD from the intraday midpoint.
The script utilizes historical high, low, and standard deviation values to dynamically estimate the standard deviation of the intraday candle, providing a measure of volatility for the current price range. This estimation is then used to construct a modified box plot around the intraday midpoint.
In addition I have included a 7 period hull moving average just to see the overall trend direction.
Conclusion:
The "Nasan Modified Box Plots" indicator on TradingView is a dynamic visualization tool that provides insights into the distribution of price ranges over a specified period. It adapts to changing market conditions by incorporating historical data in the calculation of a scaling factor (d). The indicator constructs a modified box plot, where the size of the box and the whiskers is determined by recent volatility

Tips,Notes,RulesEasy Annotation:
Quickly create custom annotations during your trading sessions to capture important ideas, strategies and observations as you go.
User-friendly Interface:
The indicator offers an intuitive interface, ensuring a smooth experience for adding notes to your chart.
Custom Appearance:
Personalize your annotations according to your preferences.
Adjust the text size to make your notes easily readable and tailored to your visual preferences.
Choose from a variety of colors to make your annotations visually distinct and recognizable.
Align your text according to your preferences to create a visually appealing graphic.
Flexible Positioning:
Place your annotations at the top, middle, or bottom of the chart, providing flexibility without obstructing your view of the price action.
Clear View of Price Action:
Make sure your personalized notes don't interfere with your analysis of market movements.
Tracking Trading Rules:
Use the indicator to record your trading rules, ensuring that you follow your established strategies consistently.
Implement and follow your risk management plans, helping you maintain control over your transactions.
Capture and examine the psychological cues that influence your decisions, promoting greater discipline in your approach to trading.
Improved Trading Experience:
The Trading Notes indicator integrates seamlessly into your trading workflow, allowing you to focus on market analysis and decision-making.
Develop a complete record of your trading sessions, facilitating post-analysis and continuous improvement.
CAPM Calculator [TrendX_]CAPM calculator is a powerful tool that helps find the cost of equity, which is the minimum return that shareholders require to invest in a company.
With the CAPM calculator, you can assess how well your trading strategy performs compared to the market. The goal of your strategy is to earn higher returns than what you would get by investing in the market with the same level of risk. This is called the risk-adjusted cost of capital, and it represents the minimum return that you should accept for your investment.
USAGE
A simple way to measure this is to compare the Compound annual growth rate (CAGR) of the trading strategy with the “Compound CAPM”, which is the CAGR of investing in the market with the same beta as the strategy.
If the trading strategy has a higher CAGR than the “Compound CAPM”, it means that it has outperformed the market on a risk-adjusted basis.
This is a sign of an effective trading strategy.
DISCLAIMER
The results achieved in the past are not all reliable sources of what will happen in the future. There are many factors and uncertainties that can affect the outcome of any endeavor, and no one can guarantee or predict with certainty what will occur.
Therefore, you should always exercise caution and judgment when making decisions based on past performance.

WRESBAL PlusWRESBAL Plus is an improved way of looking at the same data that drives WRESBAL, which is a commonly used series on FRED.
WRESBAL is a weekly average of combined balances on FRED using inputs that are weekly averages in some cases. For example the Treasury General Account has multiple FRED series including WDTGAL (wednesday level) and WTREGEN (wednesday weekly average) There are data sets that are tracking the same metrics which are updated daily such as RRPONTSYD as opposed to WLRRAL.
This situation leads to an opportunity to create a new and improved WRESBAL with the data that is updated more frequently. WRESBAL Plus solves the problem of waiting for weekly averages to update trends.
WRESBAL plus combines data sets from FRED that are updated more frequently and are the basis for the original WRESBAL equation. WRESBAL Plus offers a signal that predicts where WRESBAL will go, and this is important when determining the direction of asset prices as they relate to liquidity. One example of an asset that closely follows WRESBAL is Bitcoin.

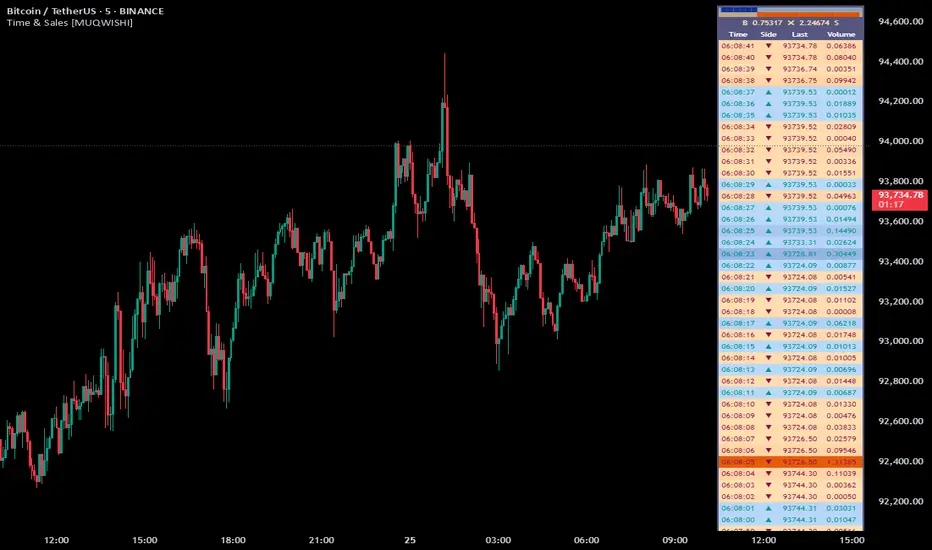
Time & Sales (Tape) [By MUQWISHI]▋ INTRODUCTION :
The “Time and Sales” (Tape) indicator generates trade data, including time, direction, price, and volume for each executed trade on an exchange. This information is typically delivered in real-time on a tick-by-tick basis or lower timeframe, providing insights into the traded size for a specific security.
_______________________
▋ OVERVIEW:
_______________________
▋ Volume Dynamic Scale Bar:
It's a way for determining dominance on the time and sales table, depending on the selected length (number of rows), indicating whether buyers or sellers are in control in selected length.
_______________________
▋ INDICATOR SETTINGS:
#Section One: Table Settings
#Section Two: Technical Settings
(1) Implement By: Retrieve data by
(1A) Lower Timeframe: Fetch data from the selected lower timeframe.
(1B) Live Tick: Fetch data in real-time on a tick-by-tick basis, capturing data as soon as it's observed by the system.
(2) Length (Number of Rows): User able to select number of rows.
(3) Size Type: Volume OR Price Volume.
_____________________
▋ COMMENT:
The values in a table should not be taken as a major concept to build a trading decision.
Please let me know if you have any questions.
Thank you.
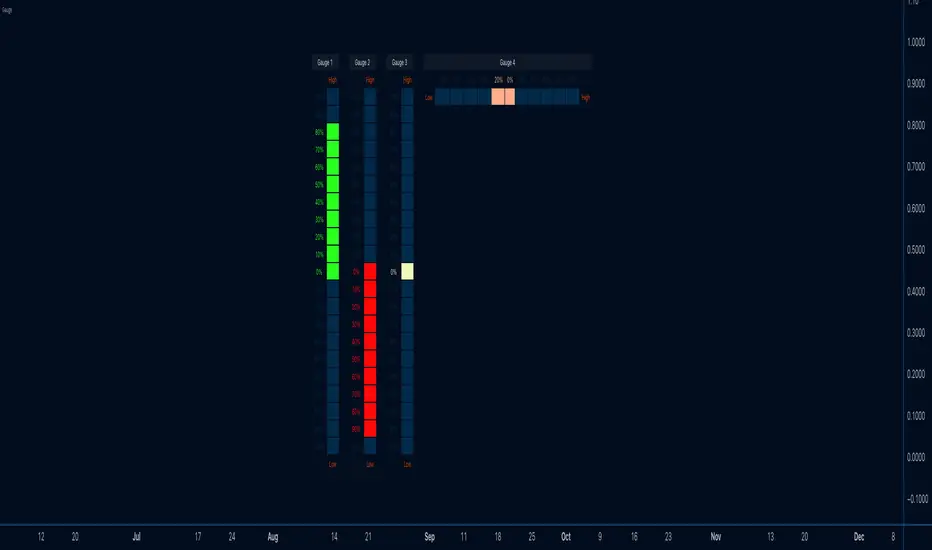
GuageLibrary "Gauge"
The gauge library utilizes a gaugeParams object, encapsulating crucial parameters for gauge creation. Essential attributes include num (the measured value) , min (the minimum value equating to 100% on the gauge's minimum scale) , and max (the maximum value equating to 100% on the gauge's maximum scale) . The size attribute (defaulting to 10) splits the scale into increments, each representing 100% divided by the specified size.
The num value dynamically shifts within the gauge based on its percentage move from the mathematical average between min and max . When num is below the average, the minimum portion of the scale activates, displaying the appropriate percentage based on the distance from the average to the minimum. The same principle applies when num exceeds the average. The 100% scale is reached at either end when num equals min or max .
The library offers full customization, allowing users to configure color schemes, labels, and titles. The gauge can be displayed either vertically (default) or horizontally. The colors employ a gradient, adapting based on the number's movement. Overall, the gauge library provides a flexible and comprehensive tool for visualizing and interpreting numerical values within a specified range.
Dynamic Volume-Volatility Adjusted MomentumThis Indicator in a refinement of my earlier script PC*VC Moving average Old with easier to follow color codes, overbought and oversold zones. This script has converted the previous script into a standardized measure by converting it into Z-scores and also incorporated a volatility based dynamic length option. Below is a detailed Explanation.
The "Dynamic Volume-Volatility Adjusted Momentum" or "Nasan Momentum Oscillator" is designed to capture market momentum while accounting for volume and volatility fluctuations. It leverages the Typical Price (TP), calculated as the average of high, low, and close prices, and introduces the Price Coefficient (PC) based on deviations from the simple moving average (SMA) across various time frames. Additionally, the Volume Coefficient (VC) compares current volume to SMA, and calculates Intraday Volatility (IDV) which gauges the daily price range relative to the close. Then intraday volatility ratio is calculated ( IDV Ratio) as the ratio of current Intraday Volatility (IDV) to the average of IDV for three different length periods, which provides a relative measure of current intraday volatility compared to its recent historical average. An inter-day ATR based Relative Volatility (RV) is calculated to adjusts for changing market volatility based on which the dynamic length adjustment adapts the moving average (standard length is 14). The PC *VC/IDV Ratio integrates price, volume, and volatility information which provides a volume and volatility adjusted momentum. This volume and volatility adjusted momentum is converted into a standardized Z-Score. The Z-Score measures deviations from the mean. Color-coded plots visually represent momentum, and thresholds aid in identifying overbought or oversold conditions.
The indicator incorporates a nuanced approach to emphasize the joint impact of price and volume while considering the stabilizing effect of lower intraday volatility. Placing the volume ratio (VC) in the numerator means that higher volume positively contributes to the overall ratio, aligning with the observation that increased volumes often accompany robust price movements. Simultaneously, the decision to include the inverse of intraday volatility (1/IDV) in the denominator acts as a dampener, reducing the impact of extreme intraday volatility on the momentum indicator. This design choice aims to filter out noise, giving more weight to significant price changes supported by substantial trading activity. In essence, the indicator's design seeks to provide a more robust momentum measure that balances the influence of price, volume, and volatility in the analysis of market dynamics.

EntryPrice Gain&Loss IndicatorThis indicator takes (1) an entry price or average position price and (2) position size (denominator) to calculate current gain or loss and returns those as well as the position change in percent. It will also draw into the Chart and show relevant data in a table.
It is mainly supposed to help tracking an (average) spot position easily.
It is recommended to switch it to invisible when switching to other charts.
You can also use several instances of the indicator to track your positions in different assets.
Features:
- table position and text size can be adjusted
- colors can be changed
(recommending 25% opacity for plot backgrounds)
- several instances possible
(recommended to tuen indicator invisible when switching to other charts or analyzing
Version 1.0

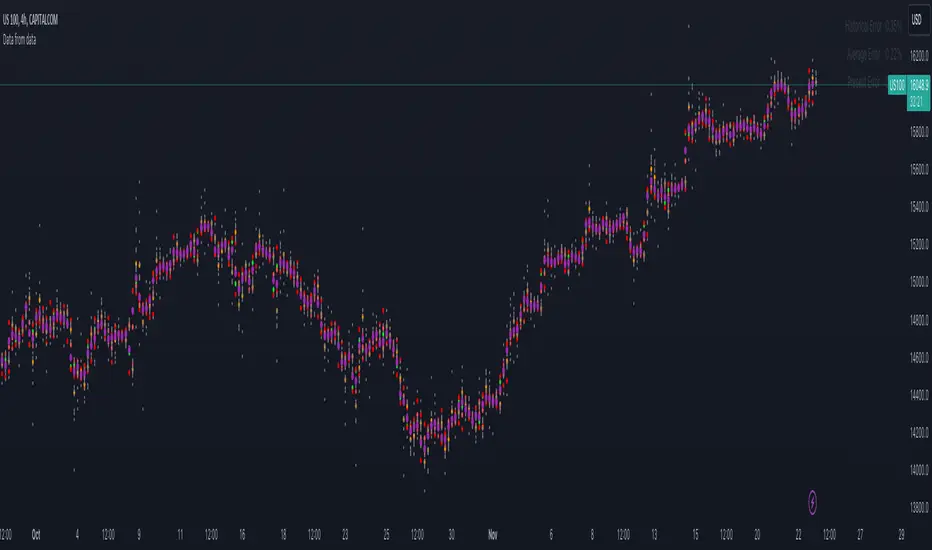
Data from dataThe "Data from Data" indicator, developed by OmegaTools, is a sophisticated and versatile tool designed to offer a nuanced analysis of various market dynamics, catering to traders and investors seeking a comprehensive understanding of price movements considering a large amount of data and variables.
The uses of this indicator are nonconventional. You can use the indicator as a stand-alone tool on the chart, hiding the current symbol price data, to be able to analyze the price action with the Semaphore visualization method, you can also hide the indicator and choose from your favorite indicators and oscillator one of the data output as a source to have additional insight on the asset.
The last use of this indicator, which depends on the X Value that you set in the settings, is to have a possible scenario for the future outcomes of the markets. Remember that there is no tool that can really predict what the market will do in the future, this tool applies a large amount of formulas to use past prices as an indication that aims to be as close as possible to the future prices. The X Value not only changes the lookback of the formulas but also changes the number of future scenarios that the indicator will plot on the chart.
Key Features:
1. Rate of Change Analysis:
The indicator evaluates the rate of change variations in closing prices, providing insights into the current rate of change and expected rate of change variation.
2. Momentum Analysis:
Momentum is analyzed through calculations involving simple moving averages, offering expected values derived from momentum and momentum variation.
3. High/Low Variation:
The expected market behavior is assessed based on the average variation between high and low prices, contributing to a more holistic analysis.
4. Liquidity Targets:
Liquidity targets can be found by analyzing the highs and lows in the direction of the current fair price.
5. Regression Sequence:
Linear regression analysis is applied to closing prices, assessing momentum and providing expected values based on regression sequences.
6. Volume Presence:
The indicator evaluates the Rate of Change (ROC) by volume presence, offering insights into price movements influenced by trading volume.
7. Liquidity Grabs:
Expected market behavior is determined based on liquidity grabs, considering both current and historical price levels.
8. Fair Value Analysis:
Expected values are derived from fair value closes and fair value highs and lows, contributing to a more nuanced analysis of market conditions.
9. STT (Sequential Trend Test):
The Sequential Trend Test is employed to analyze market trends, providing expected values for a more informed decision-making process.
Visualization:
The indicator shows a "Semaphore" on the chart, visually representing all of the data extrapolated from the script. The visualization can be more minimalistic or more complex, to let the user decide that, in the settings, it's possible to decide if to show all of the data or only the average.
Additionally, the user can choose to display bars on the chart, that visualize the standard high and low of the price data, with the difference between the expected forecasted value and the actual closing price.
My suggestion is to try to change the colors of the data to fit best your eye and the data that you find more useful, and also to try to change some parameters from circle to line as a visualization method to catch with more ease some price patterns.
Error Analysis:
The indicator provides a detailed error analysis, including historical error, average error, and present error. This information is presented in a user-friendly table for quick reference. This table can be used to analyze the margin of error of the expected future price.
THISMA btccorrelationDescription:
This is a tool designed for traders who want to analyze correlation between any traded crypto's price in USD and the price of Bitcoin in USD.
Key Features:
Adjustable Correlation Window: The script features an input parameter that allows traders to set the length of the correlation window, with a default value of 14. Lower if you want faster granularity.
Clear Visualization: The correlation coefficient is plotted in a distinct pane below the main trading chart.
Reference Lines for Interpretation: Horizontal reference lines are included at 0.5 (indicating weak positive correlation), -0.5 (indicating weak negative correlation), and 0 (indicating no correlation). These lines, color-coded in green, red, and gray respectively, assist traders in quickly interpreting the correlation coefficient's value.
Applications:
Market Insight: If you want to be able to monitor if you should enter a trade on an altcoin or if its better to stick to Bitcoin to avoid being double exposed.
Risk Management: Identifying the correlation can help in assessing and managing the systemic risk associated with market movements, especially in cryptocurrency markets where Bitcoin's influence is significant.

ADR % RangesThis indicator is designed to visually represent percentage lines from the open of the day. The % amount is determined by X amount of the last days to create an average...or Average Daily Range (ADR).
1. ADR Percentage Lines: The core function of the script is to apply lines to the chart that represent specific percentage changes from the daily open. It first calculates the average over X amount of days and then displays two lines that are 1/3rd of that average. One line goes above the other line goes below. The other two lines are the full "range" of the average. These lines can act as boundaries or targets to know how an asset has moved recently. *Past performance is not indicative of current or future results.
The calculation for ADR is:
Step 1. Calculate Today's Range = DailyHigh - DailyLow
Step 2. Store this average after the day has completed
Step 3. Sum all day's ranges
Step 4. Divide by total number of days
Step 5. Draw on chart
2. Customizable Inputs: Users have the flexibility to customize the script through various inputs. This includes the option to display lines only for the current trading day (`todayonly`), and to select which lines are displayed. The user can also opt to show a table the displays the total range of previous days and the average range of those previous days.
3. No Secondary Timeframe: The ADR is computed based on whatever timeframe the chart is and does not reference secondary periods. Therefore the script cannot be used on charts greater than daily.
This script is can be used by all traders for any market. The trader might have to adjust the "X" number of days back to compute a historical average. Maybe they only want to know the average over the past week (5 days) or maybe the past month (20 days).

unconscious lineThis indicator was created with the idea that if everyone trades, it will move in that direction, i.e., it will repeatedly converge on an unaware area. The unaware area is defined by calculating the difference between the high and high of the current bar and the previous bar, and the low and low of the current bar, and then plotting the maximum and minimum values of the unaware area. If the price converges to this line, the time when it does not go to this line can be taken as the bias of the theoretical price, so it is not plotted, but the time when it does not touch the right edge of the indicator title is plotted.
Parameters
Arybuf -Specifies the range of values to be determined from the current time. The smaller the value, the more recent the value will be used.
Style
1. Display the smallest value in the judgment range
2. Display the largest value in the judgment range.
3. Display line 1 to draw the range with the largest difference.
Displays line 2 that draws the range with the largest difference.
The area with the largest difference, i.e., the unaware area, is the range of values from Style 3 to 4.
Period of noncoucentration.
This value is the number of bars that have not touched the least concentrated area.
Indicator Usage.
Set the value of the parameter.
Draw a long enough moving average.
Use the moving average to recognize the environment and make an entry at a push.
Note that this indicator draws a convergence point and does not predict the future. While this allows you to find a push, the value itself has no driving force.
When used in a contrarian manner, it should be used with the expectation that it will be caught at a buying or selling climax at some point in the future.
ATH Drawdown Indicator by Atilla YurtsevenThe ATH (All-Time High) Drawdown Indicator, developed by Atilla Yurtseven, is an essential tool for traders and investors who seek to understand the current price position in relation to historical peaks. This indicator is especially useful in volatile markets like cryptocurrencies and stocks, offering insights into potential buy or sell opportunities based on historical price action.
This indicator is suitable for long-term investors. It shows the average value loss of a price. However, it's important to remember that this indicator only displays statistics based on past price movements. The price of a stock can remain cheap for many years.
1. Utility of the Indicator:
The ATH Drawdown Indicator provides a clear view of how far the current price is from its all-time high. This is particularly beneficial in assessing the magnitude of a pullback or retracement from peak levels. By understanding these levels, traders can gauge market sentiment and make informed decisions about entry and exit points.
2. Risk Management:
This indicator aids in risk management by highlighting significant drawdowns from the ATH. Traders can use this information to adjust their position sizes or set stop-loss orders more effectively. For instance, entering trades when the price is significantly below the ATH could indicate a higher potential for recovery, while a minimal drawdown from the ATH may suggest caution due to potential overvaluation.
3. Indicator Functionality:
The indicator calculates the percentage drawdown from the ATH for each trading period. It can display this data either as a line graph or overlaid on candles, based on user preference. Horizontal lines at -25%, -50%, -75%, and -100% drawdown levels offer quick visual cues for significant price levels. The color-coding of candles further aids in visualizing bullish or bearish trends in the context of ATH drawdowns.
4. ATH Level Indicator (0 Level):
A unique feature of this indicator is the 0 level, which signifies that the price is currently at its all-time high. This level is a critical reference point for understanding the market's peak performance.
5. Mean Line Indicator:
Additionally, this indicator includes a 'Mean Line', representing the average percentage drawdown from the ATH. This average is calculated over more than a thousand past bars, leveraging the law of large numbers to provide a reliable mean value. This mean line is instrumental in understanding the typical market behavior in relation to the ATH.
Disclaimer:
Please note that this ATH Drawdown Indicator by Atilla Yurtseven is provided as an open-source tool for educational purposes only. It should not be construed as investment advice. Users should conduct their own research and consult a financial advisor before making any investment decisions. The creator of this indicator bears no responsibility for any trading losses incurred using this tool.
Please remember to follow and comment!
Trade smart, stay safe
Atilla Yurtseven