AWR - Chris - V3Calculates the AWR based on Dr. Coles formula. Takes the last 12 weeks (not including the current one) highs and lows, adds them and then divides by twelve, give the average weekly range. Then takes the AWR and show the playing field based on the high and low of the current weekly candle. Must be used on the weekly chart to get the data needed then manually plot your lines on the required charts.
Statistics

Bitcoin Regression Price BoundariesTLDR
DCA into BTC at or below the blue line. DCA out of BTC when price approaches the red line. There's a setting to toggle the future extrapolation off/on.
INTRODUCTION
Regression analysis is a fundamental and powerful data science tool, when applied CORRECTLY . All Bitcoin regressions I've seen (Rainbow Log, Stock-to-flow, and non-linear models), have glaring flaws ... Namely, that they have huge drift from one cycle to the next.
Presented here, is a canonical application of this statistical tool. "Canonical" meaning that any trained analyst applying the established methodology, would arrive at the same result. We model 3 lines:
Upper price boundary (red) - Predicted the April 2021 top to within 1%
Lower price boundary (green)- Predicted the Dec 2022 bottom within 10%
Non-bubble best fit line (blue) - Last update was performed on Feb 28 2024.
NOTE: The red/green lines were calculated using solely data from BEFORE 2021.
"I'M INTRUIGED, BUT WHAT EXACTLY IS REGRESSION ANALYSIS?"
Quite simply, it attempts to draw a best-fit line over some set of data. As you can imagine, there are endless forms of equations that we might try. So we need objective means of determining which equations are better than others. This is where statistical rigor is crucial.
We check p-values to ensure that a proposed model is better than chance. When comparing two different equations, we check R-squared and Residual Standard Error, to determine which equation is modeling the data better. We check residuals to ensure the equation is sufficiently complex to model all the available signal. We check adjusted R-squared to ensure the equation is not *overly* complex and merely modeling random noise.
While most people probably won't entirely understand the above paragraph, there's enough key terminology in for the intellectually curious to research.
DIVING DEEPER INTO THE 3 REGRESSION LINES ABOVE
WARNING! THIS IS TECHNICAL, AND VERY ABBREVIATED
We prefer a linear regression, as the statistical checks it allows are convenient and powerful. However, the BTCUSD dataset is decidedly non-linear. Thus, we must log transform both the x-axis and y-axis. At the end of this process, we'll use e^ to transform back to natural scale.
Plotting the log transformed data reveals a crucial visual insight. The best fit line for the blowoff tops is different than for the lower price boundary. This is why other models have failed. They attempt to model ALL the data with just one equation. This causes drift in both the upper and lower boundaries. Here we calculate these boundaries as separate equations.
Upper Boundary (in red) = e^(3.24*ln(x)-15.8)
Lower Boundary (green) = e^(0.602*ln^2(x) - 4.78*ln(x) + 7.17)
Non-Bubble best fit (blue) = e^(0.633*ln^2(x) - 5.09*ln(x) +8.12)
* (x) = The number of days since July 18 2010
Anyone familiar with Bitcoin, knows it goes in cycles where price goes stratospheric, typically measured in months; and then a lengthy cool-off period measured in years. The non-bubble best fit line methodically removes the extreme upward deviations until the residuals have the closest statistical semblance to normal data (bell curve shaped data).
Whereas the upper/lower boundary only gets re-calculated in hindsight (well after a blowoff or capitulation occur), the Non-Bubble line changes ever so slightly with each new datapoint. The last update to this line was made on Feb 28, 2024.
ENOUGH NERD TALK! HOW CAN I APPLY THIS?
In the simplest terms, anything below the blue line is a statistical buying opportunity. The closer you approach the green line (the lower boundary) the more statistically strong that opportunity is. As price approaches the red line, is a growing statistical likelyhood/danger of an imminent blowoff top.
So a wise trader would DCA (dollar cost average) into Bitcoin below the blue line; and would DCA out of Bitcoin as it approaches the red line. Historically, you may or may not have a large time-window during points of maximum opportunity. So be vigilant! Anything within 10-20% of the boundary should be regarded as extreme opportunity.
Note: You can toggle the future extrapolation of these lines in the settings (default on).
CLOSING REMARKS
Keep in mind this is a pure statistical analysis. It's likely that this model is probing a complex, real economic process underlying the Bitcoin price. Statistical models like this are most accurate during steady state conditions, where the prevailing fundamentals are stable. (The astute observer will note, that the regression boundaries held despite the economic disruption of 2020).
Thus, it cannot be understated: Should some drastic fundamental change occur in the underlying economic landscape of cryptocurrency, Bitcoin itself, or the broader economy, this model could drastically deviate, and become significantly less accurate.
Furthermore, the upper/lower boundaries cross in the year 2037. THIS MODEL WILL EVENTUALLY BREAK DOWN. But for now, given that Bitcoin price moves on the order of 2000% from bottom to top, it's truly remarkable that, using SOLELY pre-2021 data, this model was able to nail the top/bottom within 10%.

NSE Option Straddle Candle Chart
'NSE Option Straddle Candle Chart' plot a straddle chart of the mentioned strike.
Straddle means combine price of a call price and a put price.
User has 4 inputs :
1 : Spot Symbol
2 : Expiry date
3 : Straddle Strikes
4 : Ema Length
5 : Supertrend Inputs
How to use :
1 : Trade need to know first what is a straddle. If ATM straddle price is 405, than it means market is likely to close within 405 points up or down at the expiry.
2 : Straddle is traded on pairs only
3 : If trader sells a straddle than , straddle price should move down. For there reference supertrend and moving average is plotted on chart
4 : Both this indicators helps trade to identify the trend , hence predict market.
5 : Options are dying assite , so is straddle , so prefer selling straddle instead of buying.

Price Scenarios - The Quant ScienceGENERAL OVERVIEW
Price Scenarios - The Quant Science is a quantitative statistical indicator that provides a forecast probability about future prices moving using the mathematical-statistical formula of statistical probability and expected value.
HOW TO USE
The indicator displays arrow-shaped signals that represent the probable future price movement calculated by the indicator, including the current percentage probability. Additionally, the candlesticks are colored based on the predicted direction to facilitate visual analysis. By default, green is used for bullish movements and red for bearish movements. The trader can set the analysis period (default value is 200) and the percentage threshold of probability to consider (default value is greater than 0.50 or 50%) through the user interface.
USER INTERFACE
Lenght analysis: with this features you can handle the length of the dataset to be used for estimating statistical probabilities.
Expected value: with this feature you can handle the threshold of the expected value to filter, only probabilities greater than this threshold will be considered by the model. By default, it is set to 0.50, which is equivalent to 50%.
Design Settings: modify the colors of your indicator with just a few clicks by managing this function.
We recommend disabling 'Wick' and 'Border' from the settings panel for a smoother and more efficient user experience.

NSE Option Chain
This Indicator show Options Data on signal dashboard , that help trader to analyse the market.
Options data consist of two things , Call and Put.
Every Strike has its Call and Put price.
So if user Opens any chart which is traded in options , dashboard will show total 16 Call and 16 Put strikes
8 Above from ATM and 8 Below from ATM.
On left hand side of dashboard there is Call data and on right side there is Put data.
Call side datas are , Call LTP which is latest price of that call strike , Call Chg which is change in points from previous day close and third is Call % which is % change from previous day close.
Same is on put side.
Color code is done based on positive or negative of data. If change or % is negative then color is red else green.
ATM strike data is plotted in bold
Inputs :
Spot Symbol Input for Option dashboard
Expiry date of that option contract
Strike interval between 2 strikes
Reference ATM strike ( user should keep this input as current ATM strike )
How to Use :
If dashboard shows call side is negative and put side is positive then that means market Bearish , because falling market leads to falling price of call and increase in price of Put.
Similarly if put is negative and call is positive then market is bullish.
This dashboard give trend conformation , trader should take other conformation also before taking trade.
Statistics • Chi Square • P-value • SignificanceThe Statistics • Chi Square • P-value • Significance publication aims to provide a tool for combining different conditions and checking whether the outcome is significant using the Chi-Square Test and P-value.
🔶 USAGE
The basic principle is to compare two or more groups and check the results of a query test, such as asking men and women whether they want to see a romantic or non-romantic movie.
–––––––––––––––––––––––––––––––––––––––––––––
| | ROMANTIC | NON-ROMANTIC | ⬅︎ MOVIE |
–––––––––––––––––––––––––––––––––––––––––––––
| MEN | 2 | 8 | 10 |
–––––––––––––––––––––––––––––––––––––––––––––
| WOMEN | 7 | 3 | 10 |
–––––––––––––––––––––––––––––––––––––––––––––
|⬆︎ SEX | 10 | 10 | 20 |
–––––––––––––––––––––––––––––––––––––––––––––
We calculate the Chi-Square Formula, which is:
Χ² = Σ ( (Observed Value − Expected Value)² / Expected Value )
In this publication, this is:
chiSquare = 0.
for i = 0 to rows -1
for j = 0 to colums -1
observedValue = aBin.get(i).aFloat.get(j)
expectedValue = math.max(1e-12, aBin.get(i).aFloat.get(colums) * aBin.get(rows).aFloat.get(j) / sumT) //Division by 0 protection
chiSquare += math.pow(observedValue - expectedValue, 2) / expectedValue
Together with the 'Degree of Freedom', which is (rows − 1) × (columns − 1) , the P-value can be calculated.
In this case it is P-value: 0.02462
A P-value lower than 0.05 is considered to be significant. Statistically, women tend to choose a romantic movie more, while men prefer a non-romantic one.
Users have the option to choose a P-value, calculated from a standard table or through a math.ucla.edu - Javascript-based function (see references below).
Note that the population (10 men + 10 women = 20) is small, something to consider.
Either way, this principle is applied in the script, where conditions can be chosen like rsi, close, high, ...
🔹 CONDITION
Conditions are added to the left column ('CONDITION')
For example, previous rsi values (rsi ) between 0-100, divided in separate groups
🔹 CLOSE
Then, the movement of the last close is evaluated
UP when close is higher then previous close (close )
DOWN when close is lower then previous close
EQUAL when close is equal then previous close
It is also possible to use only 2 columns by adding EQUAL to UP or DOWN
UP
DOWN/EQUAL
or
UP/EQUAL
DOWN
In other words, when previous rsi value was between 80 and 90, this resulted in:
19 times a current close higher than previous close
14 times a current close lower than previous close
0 times a current close equal than previous close
However, the P-value tells us it is not statistical significant.
NOTE: Always keep in mind that past behaviour gives no certainty about future behaviour.
A vertical line is drawn at the beginning of the chosen population (max 4990)
Here, the results seem significant.
🔹 GROUPS
It is important to ensure that the groups are formed correctly. All possibilities should be present, and conditions should only be part of 1 group.
In the example above, the two top situations are acceptable; close against close can only be higher, lower or equal.
The two examples at the bottom, however, are very poorly constructed.
Several conditions can be placed in more than 1 group, and some conditions are not integrated into a group. Even if the results are significant, they are useless because of the group formation.
A population count is added as an aid to spot errors in group formation.
In this example, there is a discrepancy between the population and total count due to the absence of a condition.
The results when rsi was between 5-25 are not included, resulting in unreliable results.
🔹 PRACTICAL EXAMPLES
In this example, we have specific groups where the condition only applies to that group.
For example, the condition rsi > 55 and rsi <= 65 isn't true in another group.
Also, every possible rsi value (0 - 100) is present in 1 of the groups.
rsi > 15 and rsi <= 25 28 times UP, 19 times DOWN and 2 times EQUAL. P-value: 0.01171
When looking in detail and examining the area 15-25 RSI, we see this:
The population is now not representative (only checking for RSI between 15-25; all other RSI values are not included), so we can ignore the P-value in this case. It is merely to check in detail. In this case, the RSI values 23 and 24 seem promising.
NOTE: We should check what the close price did without any condition.
If, for example, the close price had risen 100 times out of 100, this would make things very relative.
In this case (at least two conditions need to be present), we set 1 condition at 'always true' and another at 'always false' so we'll get only the close values without any condition:
Changing the population or the conditions will change the P-value.
In the following example, the outcome is evaluated when:
close value from 1 bar back is higher than the close value from 2 bars back
close value from 1 bar back is lower/equal than the close value from 2 bars back
Or:
close value from 1 bar back is higher than the close value from 2 bars back
close value from 1 bar back is equal than the close value from 2 bars back
close value from 1 bar back is lower than the close value from 2 bars back
In both examples, all possibilities of close against close are included in the calculations. close can only by higher, equal or lower than close
Both examples have the results without a condition included (5 = 5 and 5 < 5) so one can compare the direction of current close.
🔶 NOTES
• Always keep in mind that:
Past behaviour gives no certainty about future behaviour.
Everything depends on time, cycles, events, fundamentals, technicals, ...
• This test only works for categorical data (data in categories), such as Gender {Men, Women} or color {Red, Yellow, Green, Blue} etc., but not numerical data such as height or weight. One might argue that such tests shouldn't use rsi, close, ... values.
• Consider what you're measuring
For example rsi of the current bar will always lead to a close higher than the previous close, since this is inherent to the rsi calculations.
• Be careful; often, there are na -values at the beginning of the series, which are not included in the calculations!
• Always keep in mind considering what the close price did without any condition
• The numbers must be large enough. Each entry must be five or more. In other words, it is vital to make the 'population' large enough.
• The code can be developed further, for example, by splitting UP, DOWN in close UP 1-2%, close UP 2-3%, close UP 3-4%, ...
• rsi can be supplemented with stochRSI, MFI, sma, ema, ...
🔶 SETTINGS
🔹 Population
• Choose the population size; in other words, how many bars you want to go back to. If fewer bars are available than set, this will be automatically adjusted.
🔹 Inputs
At least two conditions need to be chosen.
• Users can add up to 11 conditions, where each condition can contain two different conditions.
🔹 RSI
• Length
🔹 Levels
• Set the used levels as desired.
🔹 Levels
• P-value: P-value retrieved using a standard table method or a function.
• Used function, derived from Chi-Square Distribution Function; JavaScript
LogGamma(Z) =>
S = 1
+ 76.18009173 / Z
- 86.50532033 / (Z+1)
+ 24.01409822 / (Z+2)
- 1.231739516 / (Z+3)
+ 0.00120858003 / (Z+4)
- 0.00000536382 / (Z+5)
(Z-.5) * math.log(Z+4.5) - (Z+4.5) + math.log(S * 2.50662827465)
Gcf(float X, A) => // Good for X > A +1
A0=0., B0=1., A1=1., B1=X, AOLD=0., N=0
while (math.abs((A1-AOLD)/A1) > .00001)
AOLD := A1
N += 1
A0 := A1+(N-A)*A0
B0 := B1+(N-A)*B0
A1 := X*A0+N*A1
B1 := X*B0+N*B1
A0 := A0/B1
B0 := B0/B1
A1 := A1/B1
B1 := 1
Prob = math.exp(A * math.log(X) - X - LogGamma(A)) * A1
1 - Prob
Gser(X, A) => // Good for X < A +1
T9 = 1. / A
G = T9
I = 1
while (T9 > G* 0.00001)
T9 := T9 * X / (A + I)
G := G + T9
I += 1
G *= math.exp(A * math.log(X) - X - LogGamma(A))
Gammacdf(x, a) =>
GI = 0.
if (x<=0)
GI := 0
else if (x
Chisqcdf = Gammacdf(Z/2, DF/2)
Chisqcdf := math.round(Chisqcdf * 100000) / 100000
pValue = 1 - Chisqcdf
🔶 REFERENCES
mathsisfun.com, Chi-Square Test
Chi-Square Distribution Function

Simple SSRThis indicator shows "SSR" on the chart when SSR "Short Sale Restriction" is activated on the ticker.
SSR "Short Sale Restriction" or "alternative uptick rule" is a rule introduced by the SEC that prohibits shorting on the bid when a stock has dropped more than 10% from the prior days close in the regular trading hours.
It will stay activated for the day it has triggered and the following day through regular and extended market hours.
Since this rule only applies to the US stock market it checks for the exchange and only displays it for US stocks.

Historical Correlation [LuxAlgo]The Historical Correlation tool aims to provide the historical correlation coefficients of up to 10 pairs of user-defined tickers starting from a user-defined point in time.
Users can choose to display the historical values as lines or the most recent correlation values as a heat map.
🔶 USAGE
This tool provides historical correlation coefficients, the correlation coefficient between two assets highlight their linear relationship and is always within the range (-1, 1).
It is a simple and easy to use statistical tool, with the following interpretation:
Positive correlation (values close to +1.0): the two assets move in sync, they rise and fall at the same time.
Negative correlation (values close to -1.0): the two assets move in opposite directions: when one goes up, the other goes down and vice versa.
No correlation (values close to 0): the two assets move independently.
The user must confirm the selection of the anchor point in order for the tool to be executed; this can be done directly on the chart by clicking on any bar, or via the date field in the settings panel.
For the parameter Anchor period , the user can choose between the following values NONE, HOURLY, DAILY, WEEKLY, MONTHLY, QUARTERLY and YEARLY. If NONE is selected, there will be no resetting of the calculations, otherwise the calculations will start from the first bar of the new period.
There is a wide range of trading strategies that make use of correlation coefficients between assets, some examples are:
Pair Trading: Traders may wish to take advantage of divergences in the price movements of highly positively correlated assets; even highly positively correlated assets do not always move in the same direction; when assets with a correlation close to +1.0 diverge in their behavior, traders may see this as an opportunity to buy one and sell the other in the expectation that the assets will return to the likely same price behavior.
Sector rotation: Traders may want to favor some sectors that are expected to perform in the next cycle, tracking the correlation between different sectors and between the sector and the overall market.
Diversification: Traders can aim to have a diversified portfolio of uncorrelated assets. From a risk management perspective, it is useful to know the correlation between the assets in your portfolio, if you hold equal positions in positively correlated assets, your risk is tilted in the same direction, so if the assets move against you, your risk is doubled. You can avoid this increased risk by choosing uncorrelated assets so that they move independently.
Hedging: Traders may want to hedge positions with correlated assets, from a hedging perspective, if you are long an asset, you can hedge going long a negative correlated asset or going short a positive correlated asset.
Traders generally need to develop awareness, a key point is to be aware of the relationships between the assets we hold or trade, the historical correlation is an invaluable tool in our arsenal which allows us to make better informed decisions.
On this chart we have an example of historical correlations for several futures markets.
We can clearly see how positively correlated the Nasdaq100 and Dow30 are with the SP500 over the whole period, or how the correlation between the Euro and the SP500 falls from almost +85% to almost -4% since 2021.
As we can see, correlations, like everything else in the market, are not static and vary over time depending on many factors, from macro to technical and everything in between.
🔹 Heatmap
The chart above shows the tool with the default settings and the Drawing Mode set to 'HEATMAP'.
We can see the current correlation between the assets, in this case the FX pairs.
The highest positive correlation is +90% (+0.90) between EURUSD and GBPUSD.
The highest negative correlation is -78% (-0.78) between EURUSD and USDJPY.
The pair with no correlation is AUDUSD and EURCAD with 1% (0.01)
On the above chart we can see the current correlations for the futures markets.
Currently, the assets that are less correlated to the SP500 are NaturalGas and the Euro, the more positive correlations are Nasdaq100 and Dow20, and the more negative correlations are the Yen, Treasury Bonds and 10-Year Notes.
🔶 DETAILS
🔹 Anchor Period
This chart shows the standard FX correlations with the Anchor Period set to `MONTHLY`.
We can clearly see how the calculations restart with the new month, in this case we can clearly see the differences between the correlations from month to month.
Let us look at the correlation coefficient between GBPUSD and USDJPY
In January, their correlation started at close to -100%, rose to close to +50%, only to fall to close to 0% and remain there for the second half of the month.
In February it was -90% in the first few days of the month and is now around -57%.
And between AUDUSD and EURCAD
Last month their correlation was negative for most of the month, reaching -70% and ending around -14%.
This month their correlation has never gone below +21% and at the time of writing is close to +53%.
🔶 SETTINGS
Anchor point: Starting point from which the tool is executed
Anchor period: At the beginning of each new period, the tool will reset the calculations
Pairs from 1 to 10: For each pair of tickers, you can: enable/disable the pair, select the color and specify the two tickers from which you wish to obtain the correlation
🔹 Style
Drawing Mode: Output style, `LINES` will show the historical correlations as lines, `HEATMAP` will show the current correlations with a color gradient from green for correlations near 1 to red for correlations near -1.

Kalman Price Filter [BackQuant]Kalman Price Filter
The Kalman Filter, named after Rudolf E. Kálmán, is a algorithm used for estimating the state of a linear dynamic system from a series of noisy measurements. Originally developed for aerospace applications in the early 1960s, such as guiding Apollo spacecraft to the moon, it has since been applied across numerous fields including robotics, economics, and, notably, financial markets. Its ability to efficiently process noisy data in real-time and adapt to new measurements has made it a valuable tool in these areas.
Use Cases in Financial Markets
1. Trend Identification:
The Kalman Filter can smooth out market price data, helping to identify the underlying trend amidst the noise. This is particularly useful in algorithmic trading, where identifying the direction and strength of a trend can inform trade entry and exit decisions.
2. Market Prediction:
While no filter can predict the future with certainty, the Kalman Filter can be used to forecast short-term market movements based on current and historical data. It does this by estimating the current state of the market (e.g., the "true" price) and projecting it forward under certain model assumptions.
3. Risk Management:
The Kalman Filter's ability to estimate the volatility (or noise) of the market can be used for risk management. By dynamically adjusting to changes in market conditions, it can help traders adjust their position sizes and stop-loss orders to better manage risk.
4. Pair Trading and Arbitrage:
In pair trading, where the goal is to capitalize on the price difference between two correlated securities, the Kalman Filter can be used to estimate the spread between the pair and identify when the spread deviates significantly from its historical average, indicating a trading opportunity.
5. Optimal Asset Allocation:
The filter can also be applied in portfolio management to dynamically adjust the weights of different assets in a portfolio based on their estimated risks and returns, optimizing the portfolio's performance over time.
Advantages in Financial Applications
Adaptability: The Kalman Filter continuously updates its estimates with each new data point, making it well-suited to markets that are constantly changing.
Efficiency: It processes data and updates estimates in real-time, which is crucial for high-frequency trading strategies.
Handling Noise: Its ability to distinguish between the signal (e.g., the true price trend) and noise (e.g., random fluctuations) is particularly valuable in financial markets, where price data can be highly volatile.
Challenges and Considerations
Model Assumptions: The effectiveness of the Kalman Filter in financial applications depends on the accuracy of the model used to describe market dynamics. Financial markets are complex and influenced by numerous factors, making model selection critical.
Parameter Sensitivity: The filter's performance can be sensitive to the choice of parameters, such as the process and measurement noise values. These need to be carefully selected and potentially adjusted over time.
Despite these challenges, the Kalman Filter remains a potent tool in the quantitative trader's arsenal, offering a sophisticated method to extract useful information from noisy financial data. Its use in trading strategies should, however, be complemented with sound risk management practices and an awareness of the limitations inherent in any model-based approach to trading.
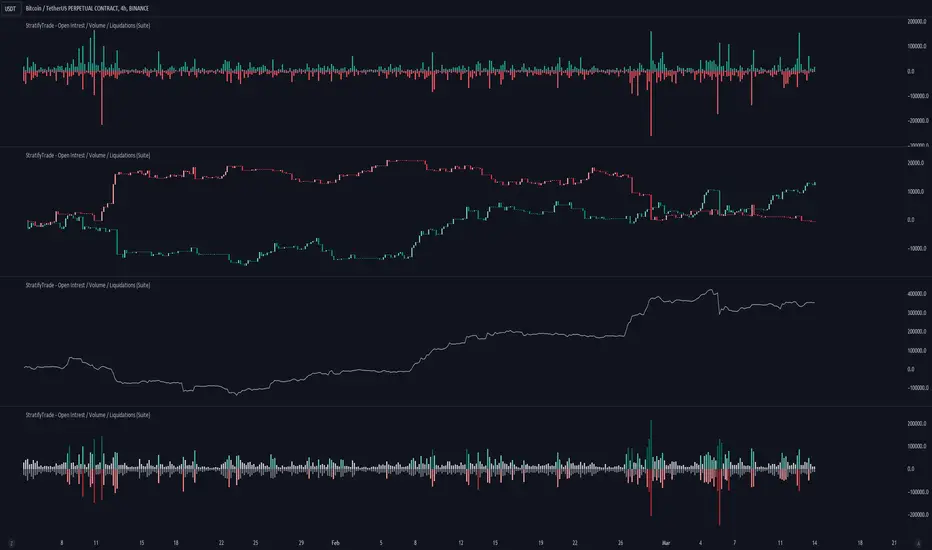
Open Intrest / Volume / Liquidations (Suite) [BigBeluga]This indicator is a suite of tools that aims to provide traders with efficient metrics to analyze the market in a different way, such as various types of Open Interest, Intraday Volume, and Liquidations.
This indicator can both save time and also provide a different approach to the usual price action trading style.
🔶 FEATURES
The indicator contains the following features:
Open Interest Suite
- Delta OI
- Net longs and shorts
- OI Relative Strength Index
Intraday Volume Suite
- Bullish and Bearish LTF Volume
- CVD
- Delta Volume
Liquidations Suite
- Long and Short Liquidations
- Cumulative Liquidations
🔶 EXAMPLE OF SUITE
In the example above, we can see how we can plot long and short positions, both opening and closing out.
This can give a unique way to view which side is the strongest but also which side has the most resting liquidity.
For example, if more longs are entering the market, it also means more liquidity for longs and vice versa.
Or, for example, plotting the delta OI will allow the user to see big percentages in change and spot big areas of position closing out.
This presents a fascinating method for observing numerous positions closing out in conjunction with a surge of liquidations, which could indicate a potential reversal in price.
Here, we can see a basic example of using intraday volume on a 1m LTF.
With this, we are able to see both bullish and bearish volume of the same candle, very useful to see both volumes traded in the same candle.
Using the CVD to see the overall direction based purely on the volume and spot divergence, for example, the price in an uptrend but CVD going down, indicating weak shorts in the market or trapped shorts.
Or simply view liquidations happening in the market in a very different way, both long and short liquidation at the same time + the option to use multi-timeframe liquidations.
🔶 CONCLUSION
The idea of this script is to provide a set of tools in a unique script to optimize time and analyze the market in both a quick way and in a different way than usual.
Kernels©2024, GoemonYae; copied from @jdehorty's "KernelFunctions" on 2024-03-09 to ensure future dependency compatibility. Will also add more functions to this script.
Library "KernelFunctions"
This library provides non-repainting kernel functions for Nadaraya-Watson estimator implementations. This allows for easy substition/comparison of different kernel functions for one another in indicators. Furthermore, kernels can easily be combined with other kernels to create newer, more customized kernels.
rationalQuadratic(_src, _lookback, _relativeWeight, startAtBar)
Rational Quadratic Kernel - An infinite sum of Gaussian Kernels of different length scales.
Parameters:
_src (float) : The source series.
_lookback (simple int) : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_relativeWeight (simple float) : Relative weighting of time frames. Smaller values resut in a more stretched out curve and larger values will result in a more wiggly curve. As this value approaches zero, the longer time frames will exert more influence on the estimation. As this value approaches infinity, the behavior of the Rational Quadratic Kernel will become identical to the Gaussian kernel.
startAtBar (simple int)
Returns: yhat The estimated values according to the Rational Quadratic Kernel.
gaussian(_src, _lookback, startAtBar)
Gaussian Kernel - A weighted average of the source series. The weights are determined by the Radial Basis Function (RBF).
Parameters:
_src (float) : The source series.
_lookback (simple int) : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
startAtBar (simple int)
Returns: yhat The estimated values according to the Gaussian Kernel.
periodic(_src, _lookback, _period, startAtBar)
Periodic Kernel - The periodic kernel (derived by David Mackay) allows one to model functions which repeat themselves exactly.
Parameters:
_src (float) : The source series.
_lookback (simple int) : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_period (simple int) : The distance between repititions of the function.
startAtBar (simple int)
Returns: yhat The estimated values according to the Periodic Kernel.
locallyPeriodic(_src, _lookback, _period, startAtBar)
Locally Periodic Kernel - The locally periodic kernel is a periodic function that slowly varies with time. It is the product of the Periodic Kernel and the Gaussian Kernel.
Parameters:
_src (float) : The source series.
_lookback (simple int) : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_period (simple int) : The distance between repititions of the function.
startAtBar (simple int)
Returns: yhat The estimated values according to the Locally Periodic Kernel.
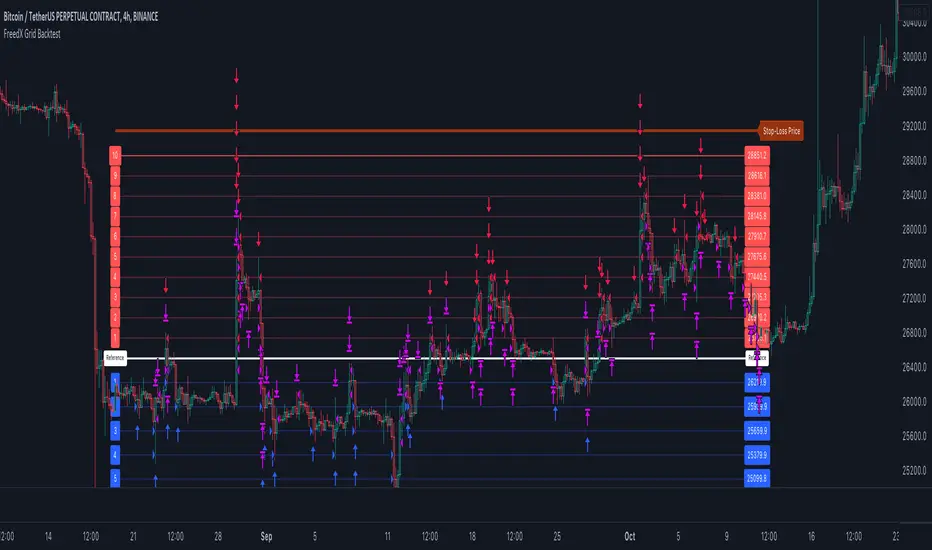
FreedX Grid Backtest█ FreedX Grid Backtest is an open-source tool that offers accurate GRID calculations for GRID trading strategies. This advanced tool allows users to backtest GRID trading parameters with precision, accurately reflecting exchange functionalities. We are committed to enhancing trading strategies through precise backtesting solutions and address the issue of unreliable backtesting practices observed on GRID trading strategies. FreedX Grid Backtest is designed for optimal calculation speed and plotting efficiency, ensuring users to achieve fastest calculations during their analysis.
█ GRID TRADING STRATEGY SETTINGS
The core of the FreedX Grid Backtest tool lies in its ability to simulate grid trading strategies. Grid trading involves placing orders at regular intervals within a predefined price range, creating a grid of orders that capitalize on market volatility.
Features:
⚙️ Backtest Range:
→ Purpose: Allows users to specify the backtesting range of GRID strategy. Closes all positions at the end of this range.
→ How to Use: Drag the dates to fit the desired backtesting range.
⚙️ Investment & Compounding:
→ Purpose: Allows users to specify the total investment amount and select between fixed and compound investment strategies. Compounding adjusts trade quantities based on performance, enhancing the grid strategy's adaptability to market changes.
→ How to Use: Set the desired investment amount and choose between "Fixed" or "Compound" for the investment method.
⚙️ Leverage & Grid Levels:
→ Purpose: Leverage amplifies the investment amount, increasing potential returns (and risks). Users can define the number of grid levels, which determines how the investment is distributed across the grid.
→ How to Use: Input the desired leverage and number of grids. The tool automatically calculates the distribution of funds across each grid level.
⚙️ Distribution Type & Mode:
→ Purpose: Users can select the distribution type (Arithmetic or Geometric) to set how grid levels are determined. The mode (Neutral, Long, Short) dictates the direction of trades within the grid.
→ How to Use: Choose the distribution type and mode based on the desired trading strategy and market outlook.
⚙️ Enable LONG/SHORT Grids exclusively:
█ MANUAL LEVELS AND STOP TRIGGERS
Beyond automated settings, the tool offers manual adjustments for traders seeking finer control over their grid strategies.
Features:
⚙️ Manual Level Adjustment:
→ Purpose: Enables traders to manually set the top, reference, and bottom levels of the grid, offering precision control over the trading range.
→ How to Use: Activate manual levels and adjust the top, reference, and bottom levels as needed to define the grid's scope.
⚙️ Stop Triggers:
→ Purpose: Provides an option to set upper and lower price limits, acting as stop triggers to close or terminate trades. This feature safeguards investments against significant market movements outside the anticipated range.
→ How to Use: Enable stop triggers and specify the upper and lower limits. The tool will automatically manage positions based on these parameters.
---
This guide gives you a quick and clear overview of the FreedX Grid Backtest tool, explaining how you can use this cutting-edge tool to improve your trading strategies.
Blockunity US Market Liquidity (BML)Get a clear view of US market liquidity and monitor its status at a glance to anticipate movements on risky assets.
The Idea
The BML aggregates and analyzes total USD market liquidity in trillions of dollars. It is used to monitor the liquidity of the USD market. When liquidity is good, all is well. If liquidity is low, the US will maneuver and sell treasury bills (debt) to replenish its treasury, which can lead to bearish pressure on markets, particularly those considered risky, such as Bitcoin.
How to Use
The indicator is very easy to use, there's nothing special about it. This tool is mainly intended to be used as fundamental information, and not for active trading.
Elements
The US Market Liquidity has several distinct components:
FED Balance Sheet
The Fed credits member banks’ Fed accounts with money, and in return, banks sell the Fed US Treasuries and/or US Mortgage-Backed Securities. This is how the Fed “prints” money to juice the financial system.
US Treasury General Account
The US Treasury General Account (TGA) balances with the NY Fed. When it decreases, it means the US Treasury is injecting money into the economy directly and creating activity. When it increases, it means the US Treasury is saving money and not stimulating economic activity. The TGA also increases when the Treasury sells bonds. This action removes liquidity from the market as buyers must pay for their bonds with dollars.
Overnight Reverse Repurchase Agreements
A reverse repurchase agreement (known as Reverse Repo or RRP) is a transaction in which the New York Fed under the authorization and direction of the Federal Open Market Committee sells a security to an eligible counterparty with an agreement to repurchase that same security at a specified price at a specific time in the future.
Earnings Remittances Due to the Treasury
The Federal Reserve Banks remit residual net earnings to the US Treasury after providing for the costs of operations, payment of dividends, and the amount necessary to maintain each Federal Reserve Bank’s allotted surplus cap. Positive amounts represent the estimated weekly remittances due to the US Treasury. Negative amounts represent the cumulative deferred asset position, which is incurred during a period when earnings are not sufficient to provide for the cost of operations, payment of dividends, and maintaining surplus.
Settings
Several parameters can be defined in the indicator configuration. You can:
Choose the smoothing and timeframe to be used in the plot.
Set the EMA lookback period and display it or not. This affects the color of the main plot.
Set the period to be taken into account when calculating the variation rate in the table.
Select the data to be taken into account in the calculation.
Activate or not the barcolor.
Lastly, you can modify all table parameters.

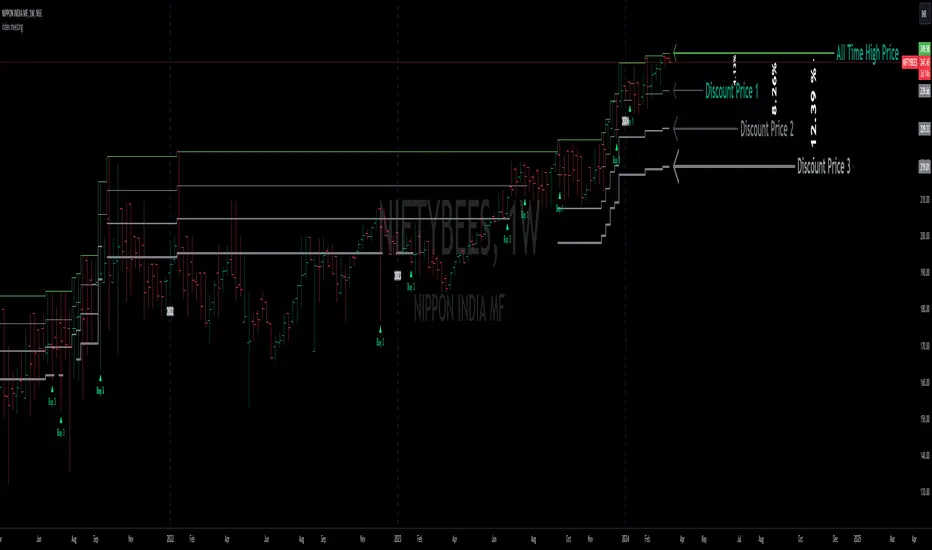
Index investingThe Index Investing indicator simplifies decision-making for adding to Index ETF's Long-term investments. By utilizing a percentage discount methodology, it highlights potential opportunities to enhance portfolios. This straightforward tool aids in identifying favorable moments to invest based on calculated price discounts from selected reference points, making the process more systematic and less subjective.
🔶 SETTINGS
Reference Price: Choose between 'All-Time-High' or 'Start of the Year' as the basis for calculating discount levels. This allows for flexibility in strategy depending on market conditions or investment philosophy.
Discount 1 %, Discount 2 %, Discount 3 %: These inputs define the percentage below the reference price at which buy signals are generated. They represent strategic entry points at discounted prices.
🔶 Default Parameters
The default parameters of 4.13%, 8.26%, and 12.39% for the discount levels are chosen based on the average 5-year return of the NSE:NIFTY Index, which stands at approximately 12.39%. By dividing this return into three parts, we obtain a structured approach to capturing potential upside at varying levels of market retracement, providing a logical basis for the selected default values.
Users have the flexibility to modify these parameters, tailoring the indicator to fit their unique approach and market outlook.
🔶 How Levels Are Calculated
Discount levels are calculated using the formula: Discount Price = Reference Price * (1 - Discount %) . This succinct approach establishes specific entry points below the chosen reference, such as an all-time high or the year's start price.
🔶 How Are the Buy Labels Generated
Buy signals are generated when the market price(Low of the candle) crosses under any of the defined discount levels. Each level has a corresponding buy label ('Buy 1', 'Buy 2', 'Buy 3'), which is activated upon the price crossing below the specified discount level and is only reset at the beginning of a new year or upon reaching a new reference high, ensuring signals are not repetitive for the same price level.
🔶 Other Features
Alerts: The indicator provides alerts for each buy signal, notifying potential entry points at their defined discount levels. The alert triggers only once per candle.
Year Marker: A vertical line with an accompanying label marks the start of each trading year on the chart. This feature aids in visualizing the temporal context of buy signals and reference price adjustments.
Range PercentageRange Percentage is a simple indicator utility to clearly display and dynamically alert on where a chosen series falls between two bounds, either series themselves or constant values.
To set up, select between series or value for upper and lower bounds. Only the chosen options will be used by the indicator, though you may enter the non-selected option. Configure the thresholds if you wish to use them for visual display or alerting. If you only care about the background color, disable both thresholds and the percentage line and move the indicator into the main pane.
Some sample use cases:
Coloring background on a zoomed-in chart to show to show price change relative to the entire value of an asset, not just the range selected on the y-axis
Get alerts which adjust dynamically as price approaches another series or dynamic value
Determine at a glance where a price falls between your identified support/resistance lines, no matter where you zoom or scroll
Compare relative gain of two assets
Identify trends of a price closing closer to low or high over time
This indicator is often most useful in conjunction with other indicators which produce a plotted series output and can save a lot of time thinking or interpreting. Its usefulness to a trader depends entirely on the rationale for choosing a lower/upper bound and sample series that are meaningful to that trader.

Kalman Filter by TenozenAnother useful indicator is here! Kalman Filter is a quantitative tool created by Rudolf E. Kalman. In the case of trading, it can help smooth out the price data that traders observe, making it easier to identify underlying trends. The Kalman Filter is particularly useful for handling price data that is noisy and unpredictable. As an adaptive-based algorithm, it can easily adjust to new data, which makes it a handy tool for traders operating in markets that are prone to change quickly.
Many people may assume that the Kalman Filter is the same as a Moving Average, but that is not the case. While both tools aim to smooth data and find trends, they serve different purposes and have their own sets of advantages and disadvantages. The Kalman Filter provides a more dynamic and adaptive approach, making it suitable for real-time analysis and predictive capabilities, but it is also more complex. On the other hand, Moving Averages offer a simpler and more intuitive way to visualize trends, which makes them a popular choice among traders for technical analysis. However, the Moving Average is a lagging indicator and less adaptive to market change, if it's adjusted it may result in overfitting. In this case, the Kalman Filter would be a better choice for smoothing the price up.
I hope you find this indicator useful! It's been an exciting and extensive journey since I began diving into the world of finance and trading. I'll keep you all updated on any new indicators I discover that could benefit the community in the future. Until then, take care, and happy trading! Ciao.

MTF TREND-PANEL-(AS)
0). INTRODUCTION: "MTF TREND-PANEL-(AS)" is a technical tool for traders who often perform multi-timeframe analysis.
This simple tool is meant for traders who wish to monitor and keep track of trend directions simultaneously on various timeframes, ranging from 1MIN to 3MONTHS (or other - 'DIFF')
script enhances decision-making efficiency and provides a clearer picture of market condition by integrating multiple timeframe analysis into a single panel.
1). WARNING!:
-script doesn't make any calculations on its own really but is more of a tool for traders to remember what is happening on other time frames
- use tooltips to navigate settings easier
2). MAIN OPTIONS:
- Keeps track of up to 7 timeframes. (NUMBER of TimeFrames setting, from 1-7)
- Customizable Display: Choose to display nothing, upward/downward arrows, or a range indication for each timeframe.
- timeframe options: '1-MIN','5-MIN','15-MIN','30-MIN','1H','4H','1D','1W','1M','3M','DIFF'
- Color Coding: Define your preferred colors for each timeframe
- set position of the table and size of text (Position/text)
- Personal Touch: Add your own trading maxim or motto for inspiration to show up when SHOW TEXT is turned on
3. )OPTIONS:
-NUMBER of TimeFrames setting: from 1-7 - how many rows to show
-SHOW TABLE: Toggle to display or hide the trend table panel.
-SHOW TEXT: Show or hide your personalized trading maxim.
-SHOW TREND: Enable to display trend direction arrows.
-SHOW_CLRS: Turn on to activate color coding for each timeframe.
-position/text size for table
-settings for each timeframe:color,time,trend
-place to type ur own text
5). How to Use the Script:
-After adding the script to your chart, use the 'NUMBER of TimeFrames' setting to select how many timeframes you want to track (1 to 7).
-Customize the appearance of each timeframe row using the color and arrow options.
-For trend analysis, the script offers arrows to indicate upward, downward, or ranging markets.
-decide what trend dominates particular TF (using other tools - script does not calculate trend on its own )
- mark trends on panel to keep track of all TF
-Enable or disable various features like the table panel, trader maxim, and color coding using the ON/OFF options.
6). just in case:
- ask me anything about the code
-don't be shy to report any bugs or offer improvements of any kind.
- originally created for @ict_whiz and made public at his request
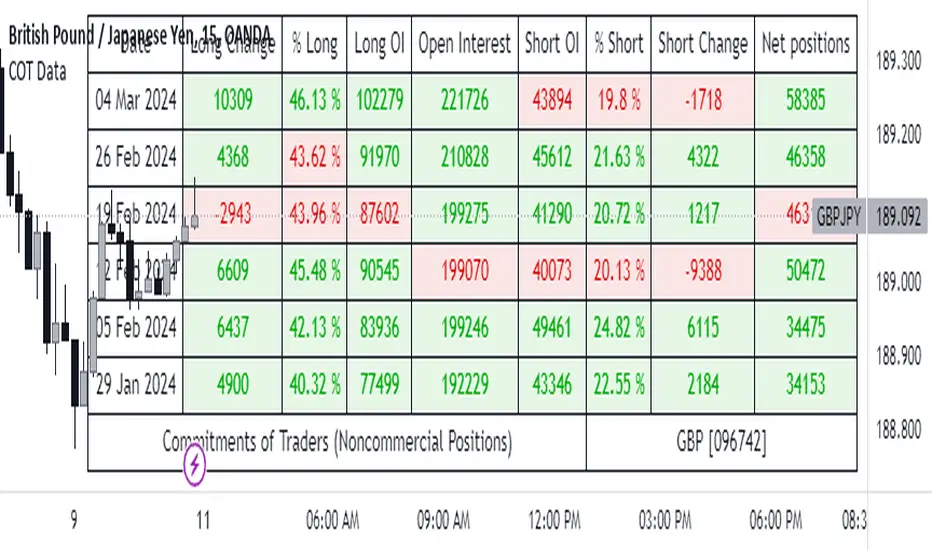
Commitments of Traders Report [Advanced]This indicator displays the Commitment of Traders (COT) report data in a clear, table format similar to an Excel spreadsheet, with additional functionalities to analyze open interest and position changes. The COT report, published weekly by the Commodity Futures Trading Commission (CFTC), provides valuable insights into market sentiment by revealing the positioning of various trader categories.
Display:
Release Date: When the data was released.
Open Interest: Shows the total number of open contracts for the underlying instrument held by selected trader category.
Net Contracts: Shows the difference between long and short positions for selected trader category.
Long/Short OI: Displays the long and short positions held by selected trader category.
Change in Long/Short OI: Displays the change in long and short positions since the previous reporting period. This can highlight buying or selling pressure.
Long & Short Percentage: Displays the percentage of total long and short positions held by each category.
Trader Categories (Configurable)
Commercials: Hedgers who use futures contracts to manage risk associated with their underlying business (e.g., producers, consumers).
Non-Commercials (Large Speculators): Speculative traders with large positions who aim to profit from price movements (e.g., hedge funds, investment banks).
Non-Reportable (Small Speculators/Retail Traders): Smaller traders with positions below the CFTC reporting thresholds.
CFTC Code: If the indicator fails to retrieve data, you can manually enter the CFTC code for the specific instrument. The code for instrument can be found on CFTC's website.
Using the Indicator Effectively
Market Sentiment Gauge: Analyze the positioning of each trader category to gauge overall market sentiment.
High net longs by commercials might indicate a bullish outlook, while high net shorts could suggest bearish sentiment.
Changes in open interest and long/short positions can provide additional insights into buying and selling pressure.
Trend Confirmation: Don't rely solely on COT data for trade signals. Use it alongside price action and other technical indicators for confirmation.
Identify Potential Turning Points: Extreme readings in COT data, combined with significant changes in open interest or positioning, might precede trend reversals, but exercise caution and combine with other analysis tools.
Disclaimer
Remember, the COT report is just one piece of the puzzle. It should not be used for making isolated trading decisions. Consider incorporating it into a comprehensive trading strategy that factors in other technical and fundamental analysis.
Credit
A big shoutout to Nick from Transparent FX ! His expertise and thoughtful analysis have been a major inspiration in developing this COT Report indicator. To know more about this indicator and how to use it, be sure to check out his work.
Genuine Liquidation Delta [Mxwll] - No EstimatesTHANK YOU TradingView for allowing us to upload custom data!!!
As a result, Mxwll Capital is providing an indicator that shows REAL liquidation delta for over 100 cryptocurrencies sourced directly from a popular crypto exchange!
Features
Crypto exchange sourced liquidation delta
Crypto exchange sourced long liquidation daily count
Crypto exchange sourced short liquidation daily count
All provided data extends back 2 years!!
Various aesthetic components to illustrate data
Liquidation delta data (sourced from a popular exchange) is provided for:
1000shib
aave
ada
algo
alice
arb
audio
alpha
ankr
ape
apt
atom
avax
axs
bal
band
bat
bch
bel
blz
blur
bnb
bnx
btc
chr
chz
comp
coti
crv
ctk
dash
defi
doge
dot
dydx
edu
egld
enj
ens
eos
etc
eth
fil
flm
ftm
fxs
gala
gmx
grt
hbar
hnt
icx
id
inj
iost
iota
joe
kava
knc
ksm
ldo
lina
link
lit
lrc
ltc
mana
mask
matic
mkr
near
neo
ocean
omg
one
ont
op
people
qtum
reef
ren
rndr
rose
rlc
rsr
rune
rvn
sand
sfp
skl
snx
sol
stmx
storj
sui
sushi
sxp
theta
tomo
trb
trx
unfi
uni
vet
waves
xem
xlm
xmr
xrp
xtz
yfi
zec
zen
zil
zrx
How-To
The image above shows the indicator with default settings.
The image above shows the start point of our data!
Over 2-years of data, allowing for plentiful analysis!
The image above explains the primary plot.
Filled blue columns reflect liquidation delta exceeding the long side. When the liquidation delta plot is aqua and exceeds 0 to the upside, longs were liquidated more than shorts for the
day.
Filled red columns reflect liquidation delta exceeding the short side. When the liquidation delta plot is red and exceeds 0 to the downside, shorts were liquidated more than longs for the day.
The image above explains the solid line (polyline) plot and its intentions!
Filled, solid, blue line reflects the total number of long liquidation events for the period.
Filled, solid, red line reflects the total number of short liquidation events for the period.
Keep in mind that the total number of liquidation events is normalized to plot alongside the total liquidation delta for the day. So, there aren't "millions" of liquidation events taking place, the total liquidation count for the long and short side is simply normalized to fit atop total liquidation delta.
The image above explains the liquidation count meter the indicator provides!
The left (blue columns) reflect the intensity of long liquidation events for the day. The right (red columns) reflect the intensity of short liquidation events for the day.
The "Max" numbers at the top show the maximum number of long liquidation events, or short liquidation events, for their respective columns.
Therefore, if the number of long liquidation events were "1.241k", as stated for this cryptocurrency in the table, the blue meter would be full. Similar logic applies to the red meter.
Once more, THANK YOU @TradingView and @PineCoders for allowing us to upload custom data! This project wouldn't be possible without it!

Semaphore PlotThe Semaphore Plot V2, crafted by OmegaTools for the TradingView platform, is a sophisticated technical analysis tool designed to offer traders nuanced insights into market dynamics. This closed-source script embodies a novel approach by synthesizing multiple technical analysis methodologies into a coherent analytical framework. This detailed description aims to demystify the operational essence of the Semaphore Plot V2 and elucidate its application in trading scenarios without overstepping into claims of infallibility or price prediction accuracy.
Analytical Foundations and Integration:
At its core, the Semaphore Plot V2 is founded on the integration of several analytical dimensions, each contributing to a comprehensive market overview:
1. Dynamic Trend Analysis: Unlike conventional trend indicators that might rely solely on moving averages, the Semaphore Plot V2 examines the market's direction through a more complex lens. It assesses momentum, utilizing derivatives of price movements to understand the velocity and acceleration of trends. This analysis is deepened by examining the rate of change (ROC), providing a multi-tiered view of how swiftly market conditions are evolving.
2. Volatility Insights: Recognizing volatility as a pivotal component of market behavior, the script incorporates volatility metrics to analyze market conditions. By evaluating historical price ranges and applying statistical models, it aims to gauge the potential for future price fluctuations, thus offering insights into market stability or turbulence without predicting specific movements.
3. Linear Regression and Predictive Analysis: The script utilizes linear regression to analyze price data points over a specified period, offering a statistical basis to understand the trajectory of market trends. This regression analysis is complemented by market momentum indicators, forming a predictive model that suggests potential areas where market activity might concentrate. It's important to note that these "predictions" are not certainties but rather statistically derived zones of interest based on historical data.
4. Market Sentiment and Risk Evaluation: Incorporating an evaluation of market sentiment, the script analyzes trends in trading volume and price action to deduce the prevailing market mood. Risk assessment tools, such as the analysis of statistical deviations and Value at Risk (VaR), are also applied to offer a perspective on the risk associated with current market conditions.
Operational Mechanism:
- By processing the integrated analysis, the script generates semaphore signals which are plotted on the trading chart. These signals are not direct buy or sell signals but are designed to highlight areas where, based on the script’s complex analysis, market activity might see significant developments.
- Additionally, the Semaphore Plot V2 features an information table that provides a retrospective analysis of the signals' alignment with market movements, offering traders a tool to assess the script's historical context.
Application and Utility:
- Traders can leverage the Semaphore Plot V2 by applying it to their TradingView charts and adjusting input settings such as lookback periods and sensitivity according to their preferences.
- The semaphore signals serve as markers for areas of potential interest. Traders are encouraged to interpret these signals within the context of their overall market analysis, incorporating other fundamental and technical analysis tools as necessary.
- The informational table serves as a resource for evaluating the historical context of the signals, providing an additional layer of insight for informed decision-making.
The Essence of Originality:
The Semaphore Plot V2 distinguishes itself through the innovative melding of traditional technical analysis components into a unique analytical concoction. This originality lies not in the creation of new technical indicators but in the novel integration and application of existing methodologies to offer a holistic view of market conditions.
Responsible Usage Disclaimer:
The financial markets are characterized by uncertainty, and the Semaphore Plot V2 is intended to serve as an analytical tool within a trader's arsenal, not a standalone solution for trading decisions. It is critical for users to understand that the script does not guarantee trading success nor does it claim to predict exact price movements. Traders should employ the Semaphore Plot V2 alongside comprehensive market analysis and sound risk management practices, acknowledging that past performance is not indicative of future results and that trading involves the risk of loss.
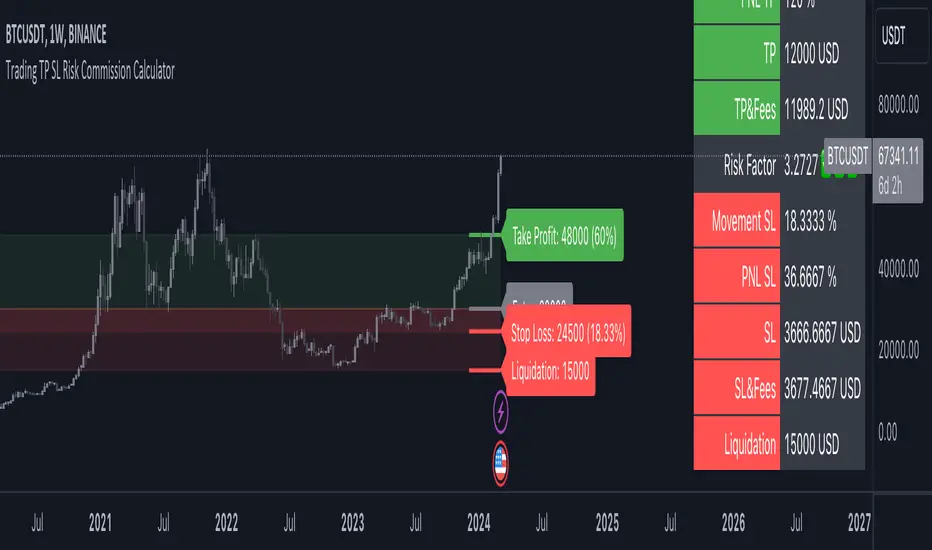
Trading TP SL Risk Commission Calculator🎉 Introducing Your Trading TP SL Risk Commission Calculator! 🎉
Hey there, savvy trader! 🚀 Are you looking to enhance your trading game? Meet the Trading TP SL Risk Commission Calculator! This handy tool is here to guide you through the complexities of trading, providing insights into your potential risks and rewards. Let's walk through how you can leverage it for smarter trading decisions!
Setting Up 🛠
Let's get your calculator ready for action:
Lines and Labels Visibility: Flip this switch on to see your Entry, Take Profit (TP), Stop Loss (SL), and Liquidation points displayed on your chart. It's a great way to get a visual summary of your strategy.
Input Your Trade Details: Enter your Entry Price, Take Profit Price, and Stop Loss Price. These figures are crucial for mapping out your trade.
Order Info: Specify your Order Size in USD, the amount of Leverage you're using, and your platform's Commission Rate. This customizes the calculator to fit your unique trading setup.
Customizing Your View 🎨
Table Placement & Size: Pick the location and size for your results table to appear on your screen. Tailor it to your liking, whether you prefer it out of the way or front and center.
Deciphering Your Results 📊
With your inputs in place, the calculator springs into action. Here's what you'll find:
Risk Assessment (with Emojis!): Quickly gauge your risk level with our intuitive emoji system, ranging from "⛔️⛔️⛔️" (very high risk) to "✅✅✅" (very low risk).
Profit and Loss Insights: Understand your potential take-profit gains and stop-loss implications, both as percentages and in USD. We also factor in fees to give you a clear picture.
Liquidation Alert: For those using leverage, the liquidation price calculation is crucial to avoid unpleasant surprises.
Expert Tips 💡
Stay Flexible: Market conditions evolve, so should your strategy. Revisit and adjust your inputs regularly to stay aligned with your trading goals.
Risk Emoji Check: Keep an eye on your risk level emojis. A sea of "⛔️" might signal it's time to reassess your approach.
Use Visual Guides: The on-chart lines and labels offer a quick visual reference to how your current trade measures up against your TP, SL, and liquidation thresholds.
Dive In and Trade Smart! 🚦
This calculator isn't just about making calculations; it's about empowering you to make informed trading decisions. With this tool in your arsenal, you're equipped to navigate the trading waters with confidence and clarity.
Risk Management Chart█ OVERVIEW
Risk Management Chart allows you to calculate and visualize equity and risk depend on your risk-reward statistics which you can set at the settings.
This script generates random trades and variants of each trade based on your settings of win/loss percent and shows it on the chart as different polyline and also shows thick line which is average of all trades.
It allows you to visualize and possible to analyze probability of your risk management. Be using different settings you can adjust and change your risk management for better profit in future.
It uses compound interest for each trade.
Each variant of trade is shown as a polyline with color from gradient depended on it last profit.
Also I made blurred lines for better visualization with function :
poly(_arr, _col, _t, _tr) =>
for t = 1 to _t
polyline.new(_arr, false, false, xloc.bar_index, color.new(_col, 0 + t * _tr), line_width = t)
█ HOW TO USE
Just add it to the cart and expand the window.
█ SETTINGS
Start Equity $ - Amount of money to start with (your equity for trades)
Win Probability % - Percent of your win / loss trades
Risk/Reward Ratio - How many profit you will get for each risk(depends on risk per trade %)
Number of Trades - How many trades will be generated for each variant of random trading
Number of variants(lines) - How many variants will be generated for each trade
Risk per Trade % -risk % of current equity for each trade
If you have any ask it at comments.
Hope it will be useful.

Aroon and ASH strategy - ETHERIUM [IkkeOmar]Intro:
This post introduces a Pine Script strategy, as an example if anyone needs a push to get started. This example is a strategy on ETH, obviously it isn't a good strategy, and I wouldn't share my own good strategies because of alpha decay. This strategy combines two technical indicators: Aroon and Absolute Strength Histogram (ASH).
Overview:
The strategy employs the Aroon indicator alongside the Absolute Strength Histogram (ASH) to determine market trends and potential trade setups. Aroon helps identify the strength and direction of a trend, while ASH provides insights into the strength of momentum. By combining these indicators, the strategy aims to capture profitable trading opportunities in Ethereum markets. Normally when developing strats using indicators, you want to find some good indicators, but you NEED to understand their strengths and weaknesses, other indicators can be incorporated to minimize the downs of another indicator. Try to look for synergy in your indicators!
Indicator settings:
Aroon Indicator:
- Two sets of parameters are used for the Aroon indicator:
- For Long Positions: Aroon periods are set to 56 (upper) and 20 (lower).
- For Short Positions: Aroon periods are set to 17 (upper) and 55 (lower).
Absolute Strength Histogram (ASH):
ASH is calculated with a length of 9 bars using the closing price as the data source.
Trading Conditions:
The strategy incorporates specific conditions to initiate and exit trades:
Start Date:
Traders can specify the start date for backtesting purposes.
Trade Direction:
Traders can select the desired trade direction: Long, Short, or Both.
Entry and Exit Conditions:
1. Long Position Entry: A long position is initiated when the Aroon indicator crosses over (crossover) the lower Aroon threshold, indicating a potential uptrend.
2. Long Position Exit: A long position is closed when the Aroon indicator crosses under (crossunder) the lower Aroon threshold.
3. Short Position Entry: A short position is initiated when the Aroon indicator crosses under (crossunder) the upper Aroon threshold, signaling a potential downtrend.
4. Short Position Exit: A short position is closed when the Aroon indicator crosses over (crossover) the upper Aroon threshold.
Disclaimer:
THIS ISN'T AN OPTIMAL STRATEGY AT ALL! It was just an old project from when I started learning pine script!
The backtest doesn't promise the same results in the future, always do both in-sample and out-of-sample testing when backtesting a strategy. And make sure you forward test it as well before implementing it!