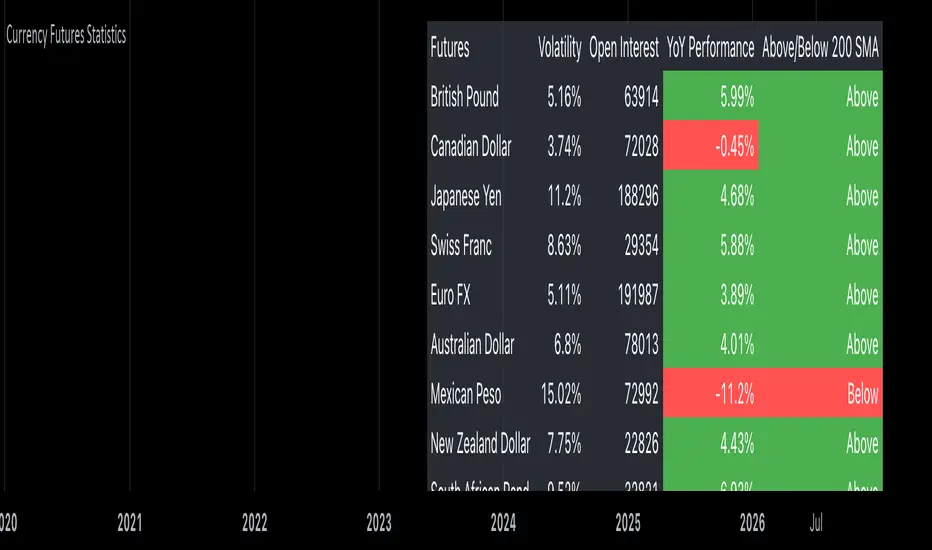
Currency Futures StatisticsThe "Currency Futures Statistics" indicator provides comprehensive insights into the performance and characteristics of various currency futures. This indicator is crucial for portfolio management as it combines multiple metrics that are instrumental in evaluating currency futures' risk and return profiles.
Metrics Included:
Historical Volatility:
Definition: Historical volatility measures the standard deviation of returns over a specified period, scaled to an annual basis.
Importance: High volatility indicates greater price fluctuations, which translates to higher risk. Investors and portfolio managers use volatility to gauge the stability of a currency future and to make informed decisions about risk management and position sizing (Hull, J. C. (2017). Options, Futures, and Other Derivatives).
Open Interest:
Definition: Open interest represents the total number of outstanding futures contracts that are held by market participants.
Importance: High open interest often signifies liquidity in the market, meaning that entering and exiting positions is less likely to impact the price significantly. It also reflects market sentiment and the degree of participation in the futures market (Black, F., & Scholes, M. (1973). The Pricing of Options and Corporate Liabilities).
Year-over-Year (YoY) Performance:
Definition: YoY performance calculates the percentage change in the futures contract's price compared to the same week from the previous year.
Importance: This metric provides insight into the long-term trend and relative performance of a currency future. Positive YoY performance suggests strengthening trends, while negative values indicate weakening trends (Fama, E. F. (1991). Efficient Capital Markets: II).
200-Day Simple Moving Average (SMA) Position:
Definition: This metric indicates whether the current price of the currency future is above or below its 200-day simple moving average.
Importance: The 200-day SMA is a widely used trend indicator. If the price is above the SMA, it suggests a bullish trend, while being below indicates a bearish trend. This information is vital for trend-following strategies and can help in making buy or sell decisions (Bollinger, J. (2001). Bollinger on Bollinger Bands).
Why These Metrics are Important for Portfolio Management:
Risk Assessment: Historical volatility and open interest provide essential information for assessing the risk associated with currency futures. Understanding the volatility helps in estimating potential price swings, which is crucial for managing risk and setting appropriate stop-loss levels.
Liquidity and Market Participation: Open interest is a critical indicator of market liquidity. Higher open interest usually means tighter bid-ask spreads and better liquidity, which facilitates smoother trading and better execution of trades.
Trend Analysis: YoY performance and the SMA position help in analyzing long-term trends. This analysis is crucial for making strategic investment decisions and adjusting the portfolio based on changing market conditions.
Informed Decision-Making: Combining these metrics allows for a holistic view of the currency futures market. This comprehensive view helps in making informed decisions, balancing risks and returns, and optimizing the portfolio to align with investment goals.
In summary, the "Currency Futures Statistics" indicator equips investors and portfolio managers with valuable data points that are essential for effective risk management, liquidity assessment, trend analysis, and overall portfolio optimization.
Statistics
Larry Conners Vix Reversal II Strategy (approx.)This Pine Script™ strategy is a modified version of the original Larry Connors VIX Reversal II Strategy, designed for short-term trading in market indices like the S&P 500. The strategy utilizes the Relative Strength Index (RSI) of the VIX (Volatility Index) to identify potential overbought or oversold market conditions. The logic is based on the assumption that extreme levels of market volatility often precede reversals in price.
How the Strategy Works
The strategy calculates the RSI of the VIX using a 25-period lookback window. The RSI is a momentum oscillator that measures the speed and change of price movements. It ranges from 0 to 100 and is often used to identify overbought and oversold conditions in assets.
Overbought Signal: When the RSI of the VIX rises above 61, it signals a potential overbought condition in the market. The strategy looks for a RSI downtick (i.e., when RSI starts to fall after reaching this level) as a trigger to enter a long position.
Oversold Signal: Conversely, when the RSI of the VIX drops below 42, the market is considered oversold. A RSI uptick (i.e., when RSI starts to rise after hitting this level) serves as a signal to enter a short position.
The strategy holds the position for a minimum of 7 days and a maximum of 12 days, after which it exits automatically.
Larry Connors: Background
Larry Connors is a prominent figure in quantitative trading, specializing in short-term market strategies. He is the co-author of several influential books on trading, such as Street Smarts (1995), co-written with Linda Raschke, and How Markets Really Work. Connors' work focuses on developing rules-based systems using volatility indicators like the VIX and oscillators such as RSI to exploit mean-reversion patterns in financial markets.
Risks of the Strategy
While the Larry Connors VIX Reversal II Strategy can capture reversals in volatile market environments, it also carries significant risks:
Over-Optimization: This modified version adjusts RSI levels and holding periods to fit recent market data. If market conditions change, the strategy might no longer be effective, leading to false signals.
Drawdowns in Trending Markets: This is a mean-reversion strategy, designed to profit when markets return to a previous mean. However, in strongly trending markets, especially during extended bull or bear phases, the strategy might generate losses due to early entries or exits.
Volatility Risk: Since this strategy is linked to the VIX, an instrument that reflects market volatility, large spikes in volatility can lead to unexpected, fast-moving market conditions, potentially leading to larger-than-expected losses.
Scientific Literature and Supporting Research
The use of RSI and VIX in trading strategies has been widely discussed in academic research. RSI is one of the most studied momentum oscillators, and numerous studies show that it can capture mean-reversion effects in various markets, including equities and derivatives.
Wong et al. (2003) investigated the effectiveness of technical trading rules such as RSI, finding that it has predictive power in certain market conditions, particularly in mean-reverting markets .
The VIX, often referred to as the “fear index,” reflects market expectations of volatility and has been a focal point in research exploring volatility-based strategies. Whaley (2000) extensively reviewed the predictive power of VIX, noting that extreme VIX readings often correlate with turning points in the stock market .
Modified Version of Original Strategy
This script is a modified version of Larry Connors' original VIX Reversal II strategy. The key differences include:
Adjusted RSI period to 25 (instead of 2 or 4 commonly used in Connors’ other work).
Overbought and oversold levels modified to 61 and 42, respectively.
Specific holding period (7 to 12 days) is predefined to reduce holding risk.
These modifications aim to adapt the strategy to different market environments, potentially enhancing performance under specific volatility conditions. However, as with any system, constant evaluation and testing in live markets are crucial.
References
Wong, W. K., Manzur, M., & Chew, B. K. (2003). How rewarding is technical analysis? Evidence from Singapore stock market. Applied Financial Economics, 13(7), 543-551.
Whaley, R. E. (2000). The investor fear gauge. Journal of Portfolio Management, 26(3), 12-17.

Global Liquidity Index and DEMA1001. Global Liquidity Index:
The code calculates global liquidity from economic data from multiple countries and regions. Specifically, it aggregates money supply data from major economies such as the United States, Europe, China, and Japan, and sums and adjusts them to get a global liquidity index.
This index is calculated by summing data from different sources and subtracting the impact of some financial instruments (such as reverse repurchase agreements, etc.), and then converting the result into a number in trillions. This can help analyze the liquidity conditions in global money markets.
2. ROC SMA (Simple Moving Average of Rate of Change):
The code calculates the rate of change (ROC) of the global liquidity index, which is a way to measure the speed of change of the index.
Then, a simple moving average (SMA) is applied to the rate of change, which helps smooth the data and identify trends.
The ROC SMA curve is displayed in yellow to help users observe the trend of liquidity changes.
3. DEMA (Double Exponential Moving Average):
DEMA is a more complex moving average that attempts to reduce the lag of the moving average and provide a more sensitive trend response.
The calculation method is to first calculate a standard exponential moving average (EMA), then calculate the EMA of this EMA, and use these two results to calculate DEMA.
The code allows users to set the period length of DEMA (default is 100), which can adjust the speed of DEMA's response to price changes.
The DEMA curve is displayed in blue, helping users to more accurately capture the trends and changes of global liquidity indicators.
Korean Exchange Relative Volume BarchartKorean Exchange Relative Volume Barchart
The Korean Exchange Relative Volume Barchart indicator compares the trading volume of a cryptocurrency on any symbol with the combined volumes of major Korean exchanges, Upbit and Bithumb. This tool helps traders understand regional trading activities, offering insights into market sentiment influenced by Korean markets.
For example 0.5 would indicate that the Korean exchanges are doing 50% of the volume of the selected symbol.
Features:
Exchange Selection: Include or exclude Upbit and Bithumb in the comparison.
Automatic Symbol Mapping: Automatically maps the current chart's symbol to equivalent symbols on Upbit and Bithumb.
Stacked Bar Chart Visualization: Plots a stacked bar chart showing the relative volume contributions of Binance, Upbit, and Bithumb.
Usage:
Add the Indicator: Apply it to a cryptocurrency chart on TradingView.
Configure Settings: Toggle inclusion of Upbit and Bithumb in the settings.
Interpret the Chart: The stacked bar chart displays the proportion of trading volumes from each exchange.
Notes:
Symbol Compatibility: Ensure the cryptocurrency is listed on the Korean exchanges for accurate comparison.
Data Accuracy: Volumes are compared in the same base currency (e.g., BTC), so no exchange rate conversion is necessary.
Enhance your trading analysis by understanding the influence of Korean exchanges on cryptocurrency volumes with the Korean Exchange Volume Comparison indicator.

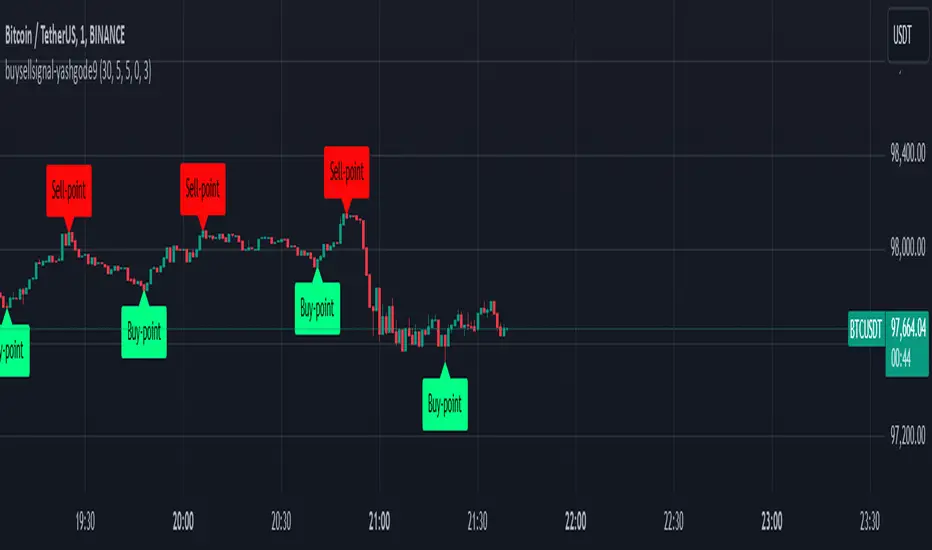
buysellsignal-yashgode9The "buysellsignal-yashgode9" indicator utilizes a signal library to generate buy and sell signals based on price action, allowing traders to make informed decisions in their trading strategies.
Overview of the Indicator
The "buysellsignal-yashgode9" indicator is a technical analysis tool that identifies potential buying and selling points in the market. It does this by leveraging a signal library imported from `yashgode9/signalLib/2`, which contains predefined algorithms for analyzing market trends based on specified parameters.
Key Features
1.Input Parameters: The indicator allows users to customize several parameters:
- Depth: Determines the number of bars to look back for price analysis (default is 150).
- Deviation: Sets the threshold for price movement (default is 120).
- Backstep: Defines how many bars to step back when evaluating signals (default is 100).
- Label Transparency: Adjusts the transparency of labels displayed on the chart.
- Color Customization: Users can specify colors for buy and sell signals.
2.Signal Generation: The core functionality is driven by the `signalLib.signalLib` function, which analyzes the low and high prices over the specified depth and deviation. It returns a direction indicator along with price points (`zee1` and `zee2`) that are used to determine whether to issue a buy or sell signal.
3. Labeling and Visualization:
- The indicator creates labels on the chart to indicate buy and sell points based on the direction of the signal.
- Labels are color-coded according to user-defined settings, enhancing visual clarity.
- The indicator also manages the deletion of previous labels and lines to avoid clutter on the chart.
4. Repainting Logic: The script includes a repainting option, allowing it to update signals in real-time as new price data comes in. This can be beneficial for traders who want to see the most current signals but may also lead to misleading signals if not used cautiously.
Conclusion:-
The "buysellsignal-yashgode9" indicator is a versatile tool for traders looking to enhance their decision-making process by identifying key market entry and exit points. By allowing customization of parameters and colors, it caters to individual trading preferences while providing clear visual signals based on price action analysis. This indicator is particularly useful for those who rely on technical analysis in their trading strategies, as it combines automated signal generation with user-friendly visual cues.
Benefits and Applications:
1.Intraday Trading: The "buysellsignal-yashgode9" indicator is particularly well-suited for intraday trading, as it provides accurate and timely buy and sell signals based on the current market dynamics.
2.Trend-following Strategies: Traders who employ trend-following strategies can leverage the indicator's ability to identify the overall market direction, allowing them to align their trades with the dominant trend.
3.Swing Trading: The dynamic price tracking and signal generation capabilities of the indicator can be beneficial for swing traders, who aim to capture medium-term price movements.
Security Measures:
1. The code includes a security notice at the beginning, indicating that it is subject to the Mozilla Public License 2.0, which is a reputable open-source license.
2. The code does not appear to contain any obvious security vulnerabilities or malicious content that could compromise user data or accounts.
NOTE:- This indicator is provided under the Mozilla Public License 2.0 and is subject to its terms and conditions.
Disclaimer: The usage of "buysellsignal-yashgode9" indicator might or might not contribute to your trading capital(money) profits and losses and the author is not responsible for the same.
IMPORTANT NOTICE:
While the indicator aims to provide reliable buy and sell signals, it is crucial to understand that the market can be influenced by unpredictable events, such as natural disasters, political unrest, changes in monetary policies, or economic crises. These unforeseen situations may occasionally lead to false signals generated by the "buysellsignal-yashgode9" indicator.
Users should exercise caution and diligence when relying on the indicator's signals, as the market's behavior can be unpredictable, and external factors may impact the accuracy of the signals. It is recommended to thoroughly backtest the indicator's performance in various market conditions and to use it as one of the many tools in a comprehensive trading strategy, rather than solely relying on its output.
Ultimately, the success of the "buysellsignal-yashgode9" indicator will depend on the user's ability to adapt it to their specific trading style, market conditions, and risk management approach. Continuous monitoring, analysis, and adjustment of the indicator's settings may be necessary to maintain its effectiveness in the ever-evolving financial markets.
Author:- yashgode9
PineScript-version:- 5
This indicator aims to enhance trading decision-making by combining DEPTH, DEVIATION, BACKSTEP with custom signal generation, offering a comprehensive tool for traders seeking clear buy and sell signals on the TradingView platform.
Stationarity Test: Dickey-Fuller & KPSS [Pinescriptlabs]
📊 Kwiatkowski-Phillips-Schmidt-Shin Model Indicator & Dickey-Fuller Test 📈
This algorithm performs two statistical tests on the price spread between two selected instruments: the first from the current chart and the second determined in the settings. The purpose is to determine if their relationship is stationary. It then uses this information to generate **visual signals** based on how far the current relationship deviates from its historical average.
⚙️ Key Components:
• 🧪 ADF Test (Augmented Dickey-Fuller):** Checks if the spread between the two instruments is stationary.
• 🔬 KPSS Test (Kwiatkowski-Phillips-Schmidt-Shin):** Another test for stationarity, complementing the ADF test.
• 📏 Z-Score Calculation:** Measures how many standard deviations the current spread is from its historical mean.
• 📊 Dynamic Threshold:** Adjusts the trading signal threshold based on recent market volatility.
🔍 What the Values Mean:
The indicator displays several key values in a table:
• 📈 ADF Stationarity:** Shows "Stationary" or "Non-Stationary" based on the ADF test result.
• 📉 KPSS Stationarity:** Shows "Stationary" or "Non-Stationary" based on the KPSS test result.
• 📏 Current Z-Score:** The current Z-score of the spread.
• 🔗 Hedge Ratio:** The relationship coefficient between the two instruments.
• 🌐 Market State:** Describes the current market condition based on the Z-score.
📊 How to Interpret the Chart:
• The main chart displays the Z-score of the spread over time.
• The green and red lines represent the upper and lower thresholds for trading signals.
• The area between the **Z-score** and the thresholds is filled when a trading signal is active.
• Additional charts show the **statistics of the ADF and KPSS tests** and their critical values.
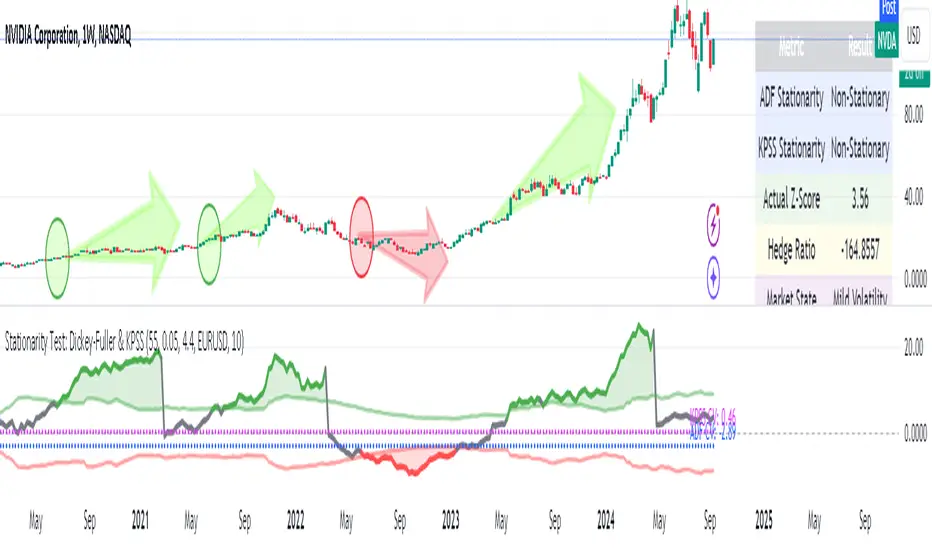
**📉 Practical Example: NVIDIA Corporation (NVDA)**
Looking at the chart for **NVIDIA Corporation (NVDA)**, we can see how the indicator applies in a real case:
1. **Main Chart (Top):**
• Shows the **historical price** of NVIDIA on a weekly scale.
• A general **uptrend** is observed with periods of consolidation.
2. **KPSS & ADF Indicator (Bottom):**
• The lower chart shows the KPSS & ADF Model indicator applied to NVIDIA.
• The **green line** represents the Z-score of the spread.
• The **green shaded areas** indicate periods where the Z-score exceeded the thresholds, generating trading signals.
3. **📋 Current Values in the Table:**
• **ADF Stationarity:** Non-Stationary
• **KPSS Stationarity:** Non-Stationary
• **Current Z-Score:** 3.45
• **Hedge Ratio:** -164.8557
• **Market State:** Moderate Volatility
4. **🔍 Interpretation:**
• A Z-score of **3.45** suggests that NVIDIA’s price is significantly above its historical average relative to **EURUSD**.
• Both the **ADF** and **KPSS** tests indicate **non-stationarity**, suggesting **caution** when using mean reversion signals at this moment.
• The market state "Moderate Volatility" indicates noticeable deviation, but not extreme.
---
**💡 Usage:**
• **When Both Tests Show Stationarity:**
• **🔼 If Z-score > Upper Threshold:** Consider **buying the first instrument** and **selling the second**.
• **🔽 If Z-score < Lower Threshold:** Consider **selling the first instrument** and **buying the second**.
• **When Either Test Shows Non-Stationarity:**
• Wait for the relationship to become **stationary** before trading.
• **Market State:**
• Use this information to evaluate **general market conditions** and adjust your trading strategy accordingly.
**Mirror Comparison of the Same as Symbol 2 🔄📊**
**📊 Table Values:**
• **Extreme Volatility Threshold:** This value is displayed when the **Z-score** exceeds **100%**, indicating **extreme deviation**. It signals a potential **trading opportunity**, as the spread has reached unusually high or low levels, suggesting a **reversion or correction** in the market.
• **Mean Reversion Threshold:** Appears when the **Z-score** begins returning towards the mean after a period of **high or extreme volatility**. It indicates that the spread between the assets is returning to normal levels, suggesting a phase of **stabilization**.
• **Neutral Zone:** Displayed when the **Z-score** is near **zero**, signaling that the spread between assets is within expected limits. This indicates a **balanced market** with no significant volatility or clear trading opportunities.
• **Low Volatility Threshold:** Appears when the **Z-score** is below **70%** of the dynamic threshold, reflecting a period of **low volatility** and market stability, indicating fewer trading opportunities.
Español:
📊 Indicador del Modelo Kwiatkowski-Phillips-Schmidt-Shin & Prueba de Dickey-Fuller 📈
Este algoritmo realiza dos pruebas estadísticas sobre la diferencia de precios (spread) entre dos instrumentos seleccionados: el primero en el gráfico actual y el segundo determinado en la configuración. El objetivo es determinar si su relación es estacionaria. Luego utiliza esta información para generar señales visuales basadas en cuánto se desvía la relación actual de su promedio histórico.
⚙️ Componentes Clave:
• 🧪 Prueba ADF (Dickey-Fuller Aumentada): Verifica si el spread entre los dos instrumentos es estacionario.
• 🔬 Prueba KPSS (Kwiatkowski-Phillips-Schmidt-Shin): Otra prueba para la estacionariedad, complementando la prueba ADF.
• 📏 Cálculo del Z-Score: Mide cuántas desviaciones estándar se encuentra el spread actual de su media histórica.
• 📊 Umbral Dinámico: Ajusta el umbral de la señal de trading en función de la volatilidad reciente del mercado.
🔍 Qué Significan los Valores:
El indicador muestra varios valores clave en una tabla:
• 📈 Estacionariedad ADF: Muestra "Estacionario" o "No Estacionario" basado en el resultado de la prueba ADF.
• 📉 Estacionariedad KPSS: Muestra "Estacionario" o "No Estacionario" basado en el resultado de la prueba KPSS.
• 📏 Z-Score Actual: El Z-score actual del spread.
• 🔗 Ratio de Cobertura: El coeficiente de relación entre los dos instrumentos.
• 🌐 Estado del Mercado: Describe la condición actual del mercado basado en el Z-score.
📊 Cómo Interpretar el Gráfico:
• El gráfico principal muestra el Z-score del spread a lo largo del tiempo.
• Las líneas verdes y rojas representan los umbrales superior e inferior para las señales de trading.
• El área entre el Z-score y los umbrales se llena cuando una señal de trading está activa.
• Los gráficos adicionales muestran las estadísticas de las pruebas ADF y KPSS y sus valores críticos.
📉 Ejemplo Práctico: NVIDIA Corporation (NVDA)
Observando el gráfico para NVIDIA Corporation (NVDA), podemos ver cómo se aplica el indicador en un caso real:
Gráfico Principal (Superior): • Muestra el precio histórico de NVIDIA en escala semanal. • Se observa una tendencia alcista general con períodos de consolidación.
Indicador KPSS & ADF (Inferior): • El gráfico inferior muestra el indicador Modelo KPSS & ADF aplicado a NVIDIA. • La línea verde representa el Z-score del spread. • Las áreas sombreadas en verde indican períodos donde el Z-score superó los umbrales, generando señales de trading.
📋 Valores Actuales en la Tabla: • Estacionariedad ADF: No Estacionario • Estacionariedad KPSS: No Estacionario • Z-Score Actual: 3.45 • Ratio de Cobertura: -164.8557 • Estado del Mercado: Volatilidad Moderada
🔍 Interpretación: • Un Z-score de 3.45 sugiere que el precio de NVIDIA está significativamente por encima de su promedio histórico en relación con EURUSD. • Tanto la prueba ADF como la KPSS indican no estacionariedad, lo que sugiere precaución al usar señales de reversión a la media en este momento. • El estado del mercado "Volatilidad Moderada" indica una desviación notable, pero no extrema.
💡 Uso:
• Cuando Ambas Pruebas Muestran Estacionariedad:
• 🔼 Si Z-score > Umbral Superior: Considera comprar el primer instrumento y vender el segundo.
• 🔽 Si Z-score < Umbral Inferior: Considera vender el primer instrumento y comprar el segundo.
• Cuando Alguna Prueba Muestra No Estacionariedad:
• Espera a que la relación se vuelva estacionaria antes de operar.
• Estado del Mercado:
• Usa esta información para evaluar las condiciones generales del mercado y ajustar tu estrategia de trading en consecuencia.
Comparativo en Espejo del Mismo Como Símbolo 2 🔄📊
📊 Valores de la Tabla:
• Umbral de Volatilidad Extrema: Este valor se muestra cuando el Z-score supera el 100%, indicando desviación extrema. Señala una posible oportunidad de trading, ya que el spread entre los activos ha alcanzado niveles inusualmente altos o bajos, lo que podría indicar una reversión o corrección en el mercado.
• Umbral de Reversión a la Media: Aparece cuando el Z-score comienza a volver hacia la media tras un período de alta o extrema volatilidad. Indica que el spread entre los activos está regresando a niveles normales, sugiriendo una fase de estabilización.
• Zona Neutral: Se muestra cuando el Z-score está cerca de cero, señalando que el spread entre activos está dentro de lo esperado. Esto indica un mercado equilibrado con ninguna volatilidad significativa ni oportunidades claras de trading.
• Umbral de Baja Volatilidad: Aparece cuando el Z-score está por debajo del 70% del umbral dinámico, reflejando un período de baja volatilidad y estabilidad del mercado, indicando menos oportunidades de trading.
Correlation with AveragesThe "Correlation with Averages" indicator is designed to visualize and analyze the correlation between a selected asset's price and a base symbol's price, such as the S&P 500 (SPY). This indicator allows users to evaluate how closely an asset’s price movements align with those of the base symbol over various time periods, providing insights into market trends and potential portfolio adjustments.
Key Features:
Base Symbol and Correlation Period:
Users can specify the base symbol (default is SPY) and the period for correlation measurement (default is 252 trading days, approximating one year).
Correlation Calculation:
The indicator computes the correlation between the asset’s closing price and the base symbol’s closing price for the defined period.
Visualization:
The correlation value is plotted on the chart, with conditional background colors indicating the strength and direction of the correlation:
Red for negative correlation (below -0.5)
Green for positive correlation (above 0.5)
Yellow for neutral correlation (between -0.5 and 0.5)
Average Correlation Over Time:
Average correlations are calculated and displayed for various periods: one week, one month, one year, and five years.
A table on the chart provides dynamic updates of these average values with color-coded backgrounds to indicate correlation strength.
The Role of Correlation in Portfolio Management
Correlation is a crucial concept in portfolio management because it measures the degree to which two securities move in relation to each other. Understanding correlation helps investors construct diversified portfolios that balance risk and return. Here's why correlation is important:
Diversification:
By including assets with low or negative correlation in a portfolio, investors can reduce overall portfolio volatility and risk. For instance, if one asset is negatively correlated with another, when one performs poorly, the other may perform well, thus smoothing the overall returns.
Risk Management:
Correlation analysis helps in identifying the potential impact of one asset’s performance on the entire portfolio. Assets with high correlation can lead to concentrated risk, while those with low correlation offer better risk management.
Performance Analysis:
Correlation measures the degree to which asset returns move together. This can inform strategic decisions, such as whether to adjust positions based on expected market conditions.
Scientific References
Markowitz, H. M. (1952). "Portfolio Selection." Journal of Finance, 7(1), 77-91.
This foundational paper introduced Modern Portfolio Theory, highlighting the importance of diversification and correlation in reducing portfolio risk.
Jorion, P. (2007). Financial Risk Manager Handbook. Wiley.
This handbook provides an in-depth exploration of risk management techniques, including the use of correlation in portfolio management.
Elton, E. J., Gruber, M. J., Brown, S. J., & Goetzmann, W. N. (2014). Modern Portfolio Theory and Investment Analysis. Wiley.
This book elaborates on the concepts of correlation and diversification, offering practical insights into portfolio construction and risk management.
By utilizing the "Correlation with Averages" indicator, traders and portfolio managers can make informed decisions based on the relationship between asset prices and the base symbol, ultimately enhancing their investment strategies.

Bull/Bear Ratio By Month Table [MsF]Japanese below / 日本語説明は英文の後にあります。
-------------------------
This is an indicator that shows monthly bull-bear ratio in a table.
By specifying the start year and end year, the ratio will be calculated and showed based on the number of bullish and bearish lines in the monthly bar. It allows you to analyze the trend of each symbol and month (bullish / bearish). Up to 10 symbols can be specified.
You can take monthly bull-bear ratio for the past 10 or 20 years on the web, but with this indicator, you can narrow it down to the period in which you want to see the symbols you want to see. It is very convenient because you can take statistics at will.
Furthermore, if the specified ratio is exceeded, the font color can be changed to any color, making it very easy to read.
=== Parameter description ===
- From … Year of start of aggregation
- To … Year of end of aggregation
- Row Background Color … Row title background color
- Col Background Color … Column title background color
- Base Text Color … Text color
- Background Color … Background Color
- Border Color … Border Color
- Location … Location
- Text Size … Text Size
- Highlight Threshold … Ratio threshold, and color
- Display in counter? … Check if you want to show the number of times instead of the ratio
-------------------------
月別陰陽確率をテーブル表示するインジケータです。
開始年から終了年を指定することで、月足における陽線数および陰線数を元に確率を計算して表示します。
この機能により各シンボルおよび各月の特徴(買われやすい/売られやすい)を認識することができアノマリー分析が可能です。
シンボルは10個まで指定可能です。
過去10年、20年の月別陰陽確率は、Web上でよく見かけますが、このインジケータでは見たいシンボルを見たい期間に絞って、
自由自在に統計を取ることができるため大変便利です。
なお、指定した確率を上回った場合、文字色を任意の色に変更することができるため、大変見やすくなっています。
=== パラメータの説明 ===
- From … 集計開始年
- To … 集計終了年
- Row Background Color … 行タイトルの背景色
- Col Background Color … 列タイトルの背景色
- Base Text Color … テキストカラー
- Background Color … 背景色
- Border Color … 区切り線の色
- Location … 配置
- Text Size … テキストサイズ
- Highlight Threshold … 色変更する確率の閾値、および色
- Display in counter? … 確率ではなく回数表示する場合はチェックする

Solar System in 3D [Astro Tool w/ Zodiac]Hello Traders and Developers,
I am excited to announce my latest Open Source indicator. At the core, this is a demonstration of PineScript’s capabilities in Rendering 3D Animations, while at the same time being a practical tool for Financial Astrologists.
This 3D Engine dynamically renders all the major celestial bodies with their individual orbits, rotation speeds, polar inclinations and astrological aspects, all while maintaining accurate spatial relationships and perspective.
This is a Geocentric model of the solar system (viewed from the perspective of Earth), since that is what most Astrologists use. Thanks to the AstroLib Library created by @BarefootJoey, this model uses the real coordinates of cosmic bodies for every timestamp.
This script truly comes to life when using the “Bar Replay” mode in TradingView, as you can observe the relationships between planets and price action as time progresses, with the full animation capabilities as mentioned above.
In addition to what I have described, this indicator also displays the orbital trajectories for each cosmic body, and has labels for everything. I have also added the ability to hover on all the labels, and see a short description of what they imply in Astrology.
Optional Planetary Aspect Computation
This indicator supports all the Major Planetary Aspects, with an accuracy defined by the user (1° by default).
Conjunction: 0° Alignment. This draws a RED line starting from the center, and going through both planets.
Sextile: 60° Alignment. This draws three YELLOW lines, connecting the planets to each other and to the center.
Square: 90° Alignment. This draws three BLUE lines, connecting the planets to each other and to the center.
Trine: 120° Alignment. This draws three PURPLE lines, connecting the planets to each other and to the center.
Opposition: 180° Alignment. This draws a GREEN line starting from one planet, passing through the center and ending on the second planet.
The below image depicts a Top-Down view of the system, with the Moon in Opposition to Venus and with Mars in Square with Neptune .
Retrograde Computation
This indicator also displays when a planet enters Retrograde (Apparent Backward Motion) by making its orbital trajectory dashed and the planet name getting a red background.
The image below displays an example of Jupiter, Saturn, Neptune and Pluto in Retrograde Motion, from the camera perspective of a 65 degree inclination.
Optional Zodiac Computation (Tropical and Sidereal)
Zodiac represents the relatively stationary star formations that rest along the ecliptic plane, with planets transitioning from one to the next, each with a 30° separation (making 12 in total). I have implemented the option to switch between Tropical mode (where these stars were 2,000 years ago) and Sidereal (where these stars are today).
The image below displays the Zodiac labels with clear lines denoting where each planet falls into.
While this indicator is deployed in a separate pane, it is trivial to transfer it onto your price chart, just by clicking and dragging the graphics. After that, you can adjust the visuals by dragging the scale on the side, or optimizing model settings. You can also drag the model above or below the price, as shown in the following image:
Of course, there are a lot of options to customize this planetary model to your tastes and analytical needs. Aside from visual changes for the labels, colors or resolution you can also disable certain planets that don’t meet your needs as shown below:
Once can also infer the current lunar phases using the Aspects between the Sun and Moon. When the Moon is Opposite the Sun that is a Full Moon, while when they are Conjunct that is a New Moon (and sometimes Eclipse).
—---------------------------------------------------------------------------
I have made this indicator open source to help PineScript programmers understand how to approach 3D graphics rendering, enabling them to develop ever more capable scripts and continuously push the boundaries of what's possible on TradingView.
The code is well documented with comments and has a clear naming convention for functions and variables, to aid developers understand how everything operates.
For financial astrologists, this indicator offers a new way to visualize and correlate planetary movements, adding depth and ease to astrological market analysis.
Regards,
Hawk

[ALGOA+] Markov Chains Library by @metacamaleoLibrary "MarkovChains"
Markov Chains library by @metacamaleo. Created in 09/08/2024.
This library provides tools to calculate and visualize Markov Chain-based transition matrices and probabilities. This library supports two primary algorithms: a rolling window Markov Chain and a conditional Markov Chain (which operates based on specified conditions). The key concepts used include Markov Chain states, transition matrices, and future state probabilities based on past market conditions or indicators.
Key functions:
- `mc_rw()`: Builds a transition matrix using a rolling window Markov Chain, calculating probabilities based on a fixed length of historical data.
- `mc_cond()`: Builds a conditional Markov Chain transition matrix, calculating probabilities based on the current market condition or indicator state.
Basically, you will just need to use the above functions on your script to default outputs and displays.
Exported UDTs include:
- s_map: An UDT variable used to store a map with dummy states, i.e., if possible states are bullish, bearish, and neutral, and current is bullish, it will be stored
in a map with following keys and values: "bullish", 1; "bearish", 0; and "neutral", 0. You will only use it to customize your own script, otherwise, it´s only for internal use.
- mc_states: This UDT variable stores user inputs, calculations and MC outputs. As the above, you don´t need to use it, but you may get features to customize your own script.
For example, you may use mc.tm to get the transition matrix, or the prob map to customize the display. As you see, functions are all based on mc_states UDT. The s_map UDT is used within mc_states´s s array.
Optional exported functions include:
- `mc_table()`: Displays the transition matrix in a table format on the chart for easy visualization of the probabilities.
- `display_list()`: Displays a map (or array) of string and float/int values in a table format, used for showing transition counts or probabilities.
- `mc_prob()`: Calculates and displays probabilities for a given number of future bars based on the current state in the Markov Chain.
- `mc_all_states_prob()`: Calculates probabilities for all states for future bars, considering all possible transitions.
The above functions may be used to customize your outputs. Use the returned variable mc_states from mc_rw() and mc_cond() to display each of its matrix, maps or arrays using mc_table() (for matrices) and display_list() (for maps and arrays) if you desire to debug or track the calculation process.
See the examples in the end of this script.
Have good trading days!
Best regards,
@metacamaleo
-----------------------------
KEY FUNCTIONS
mc_rw(state, length, states, pred_length, show_table, show_prob, table_position, prob_position, font_size)
Builds the transition matrix for a rolling window Markov Chain.
Parameters:
state (string) : The current state of the market or system.
length (int) : The rolling window size.
states (array) : Array of strings representing the possible states in the Markov Chain.
pred_length (int) : The number of bars to predict into the future.
show_table (bool) : Boolean to show or hide the transition matrix table.
show_prob (bool) : Boolean to show or hide the probability table.
table_position (string) : Position of the transition matrix table on the chart.
prob_position (string) : Position of the probability list on the chart.
font_size (string) : Size of the table font.
Returns: The transition matrix and probabilities for future states.
mc_cond(state, condition, states, pred_length, show_table, show_prob, table_position, prob_position, font_size)
Builds the transition matrix for conditional Markov Chains.
Parameters:
state (string) : The current state of the market or system.
condition (string) : A string representing the condition.
states (array) : Array of strings representing the possible states in the Markov Chain.
pred_length (int) : The number of bars to predict into the future.
show_table (bool) : Boolean to show or hide the transition matrix table.
show_prob (bool) : Boolean to show or hide the probability table.
table_position (string) : Position of the transition matrix table on the chart.
prob_position (string) : Position of the probability list on the chart.
font_size (string) : Size of the table font.
Returns: The transition matrix and probabilities for future states based on the HMM.

Ema Z-score | viResearchEma Z-score | viResearch
Conceptual Foundation and Innovation
The "Ema Z-score" indicator introduces a novel method of analyzing price deviations from the mean by combining the Exponential Moving Average (EMA) with a Z-score calculation. The Z-score is a statistical measure that quantifies how far a value deviates from the mean in terms of standard deviations. By applying the Z-score to an EMA, this indicator provides traders with insights into the strength and momentum of price movements relative to a smoothed average. This enables better detection of overbought and oversold conditions, as well as potential trend reversals.
The use of the Z-score helps filter out noise and provides more robust signals by highlighting extreme deviations from the mean, allowing traders to make more informed decisions in both trending and ranging markets.
Technical Composition and Calculation
The "Ema Z-score" script consists of two main components: the Exponential Moving Average (EMA) and the Z-score calculation. The EMA is calculated over a user-defined length, smoothing price movements to provide a clearer trend line. The Z-score is then derived by measuring the deviation of the current EMA value from the mean of the EMA over a lookback period, divided by the standard deviation of the EMA during that same period.
For the Z-score calculation, the script first computes the mean EMA over the lookback period using the ta.ema function. It then calculates the standard deviation of the EMA over the same period using the ta.stdev function. The Z-score is determined by subtracting the mean EMA from the current EMA value and dividing by the standard deviation, producing a normalized measure of deviation from the average.
Features and User Inputs
The "Ema Z-score" script offers several customizable inputs that allow traders to adjust the indicator according to their strategies. The EMA Length controls the smoothing period of the EMA, while the Lookback Period defines how far back the script looks when calculating the mean and standard deviation for the Z-score. Customizable thresholds allow traders to define when the Z-score signals potential uptrends or downtrends, based on their chosen levels of deviation.
Practical Applications
The "Ema Z-score" indicator is designed for traders who want to better understand price deviations from the mean and use those insights to identify potential trading opportunities. This tool is particularly effective for:
Identifying Overbought and Oversold Conditions: The Z-score provides a quantitative measure of how far the price has deviated from the mean, helping traders spot extreme conditions that could lead to reversals. Detecting Trend Reversals: By monitoring when the Z-score crosses certain thresholds, traders can identify potential trend reversals early and adjust their positions accordingly. Confirming Trend Strength: The Z-score can help confirm whether a price move is backed by momentum or is likely to revert to the mean, providing additional context for trade entries and exits.
Advantages and Strategic Value
The "Ema Z-score" script offers a significant advantage by combining the smoothing effect of the EMA with the precision of Z-score analysis. This approach reduces the impact of market noise while highlighting meaningful deviations from the norm. The ability to quantify deviations in terms of standard deviations gives traders a statistical edge in identifying overbought or oversold conditions and potential trend shifts. This makes the "Ema Z-score" an effective tool for both trend-following and contrarian strategies.
Alerts and Visual Cues
The script includes alert conditions to notify traders of key Z-score threshold crossings. The "Ema Z-score Long" alert is triggered when the Z-score exceeds the upper threshold, signaling a potential upward trend. Conversely, the "Ema Z-score Short" alert signals a possible downward trend when the Z-score falls below the lower threshold. Visual cues such as color changes in the bar chart and Z-score plot help traders easily identify these conditions on the chart.
Summary and Usage Tips
The "Ema Z-score | viResearch" indicator offers a unique combination of EMA smoothing and Z-score analysis, giving traders a statistical measure of price deviations and improving their ability to detect overbought or oversold conditions, trend reversals, and trend confirmations. By incorporating this script into your trading strategy, you can better quantify price extremes and make more informed decisions in both volatile and stable markets. Whether you're focused on spotting early reversals or confirming ongoing trends, the "Ema Z-score" provides a reliable and customizable solution.
Note: Backtests are based on past results and are not indicative of future performance.
Forex Macro Metrics [MacroGlide]"Forex Macro Metrics " is a powerful tool for analyzing macroeconomic metrics, designed to help traders make more informed decisions in the forex market. This indicator displays key economic indicators such as interest rates, money supply (M1 and M2), unemployment rate, and government debt for various currencies and their pairs, allowing users to assess the macroeconomic differences between the base and quote currencies.
Key Features:
• Interest Rates Display: Includes interest rates for major world currencies with the ability to show the differential between the base and quote currencies.
• Money Supply Analysis (M1 and M2): Displays the money supply for both the base and quote currencies, including differential calculations.
• Unemployment Rate: Compares the unemployment rates between currencies, showing the differences on the chart.
• Government Debt: Shows government debt levels for the base and quote currencies with differential calculations.
• Customizable Options: Enable/disable specific metrics and adjust colors for better visual clarity.
How to Use:
• Select a Currency Pair: Apply the indicator to your chart and choose the desired currency pair. The indicator will automatically load the relevant data for the base and quote currencies.
• Adjust Display Settings: Use the indicator settings to enable or disable specific metrics and their differentials.
• Analyze the Data: Compare the economic conditions of the two currencies through the charts and identify potential trading opportunities based on macroeconomic differences.
Methodology:
The indicator uses economic data available through TradingView tickers to calculate the values of the base and quote currencies. Differentials are calculated by subtracting the values of the quote currency from the base currency, allowing for a visual assessment of their differences. The displayed data includes historical changes, helping to identify trends and potential reversal points.
Originality and Usefulness:
"Forex Macro Metrics " is a unique tool that combines several key macroeconomic indicators into one comprehensive indicator. This simplifies the analysis process for traders looking to understand the fundamental differences between currencies. Using this approach provides an advantage in assessing long-term trends and potential shifts in currency pairs driven by changes in macroeconomic conditions.
Charts:
The indicator displays data in the form of lines and areas on the chart, with interest rates shown as lines for the base and quote currencies, accompanied by an area representing the differential. For money supply (M1 and M2), lines are drawn for each currency, with areas highlighting the differences. Similarly, the unemployment rate and government debt are displayed with clear visual separation of the data and their differentials, making it easy to compare and analyze the macroeconomic conditions of the currencies involved.
Enjoy the game!

Kalman PSaR [BackQuant]Kalman PSaR
Overview and Innovation
The Kalman PSaR combines the well-known Parabolic SAR (PSaR) with the advanced smoothing capabilities of the Kalman Filter . This innovative tool aims to enhance the traditional PSaR by integrating Kalman filtering, which reduces noise and improves trend detection. The Kalman PSaR adapts dynamically to price movements, making it a highly effective indicator for spotting trend shifts while minimizing the impact of false signals caused by market volatility.
Please Find the Basic Kalman Here:
Kalman Filter Dynamics
The Kalman Filter is a powerful algorithm for estimating the true value of a system amidst noisy data. In the Kalman PSaR, this filter is applied to the high, low, and closing prices, resulting in a smoother and more accurate representation of price action. The filter’s parameters—process noise and measurement noise—are customizable, allowing traders to fine-tune the sensitivity of the indicator to market conditions. By reducing the impact of noise, the Kalman-filtered PSaR offers clearer signals for identifying trend reversals and continuations.
Enhanced PSaR Calculation
The traditional Parabolic SAR is a popular trend-following indicator that highlights potential entry and exit points based on price acceleration. In the Kalman PSaR, this calculation is enhanced by the Kalman-filtered prices, providing a smoother and more reliable signal. The indicator continuously updates based on the acceleration factor and max step values, while the Kalman filter ensures that sudden price spikes or market noise do not trigger false signals.
Min Step and Max Step: These settings control the sensitivity of the PSaR. The Min Step sets the initial acceleration factor, while the Max Step limits how fast the PSaR adapts to price changes, helping traders fine-tune the indicator’s responsiveness.
Optional Smoothing Techniques To further enhance the signal clarity, the Kalman PSaR includes an optional smoothing feature. Traders can choose from various smoothing methods, such as SMA, Hull, EMA, WMA, TEMA, and more, to reduce short-term fluctuations and emphasize the underlying trend. The smoothing period is customizable, allowing traders to adjust the indicator’s behavior according to their preferred trading style and timeframe.
Color-Coded Candle Painting The Kalman PSaR features color-coded candles that change according to the trend direction. When the price is above the PSaR, candles are painted green to indicate a long trend, and when the price is below the PSaR, candles are painted red to signal a short trend. This visual representation makes it easy to interpret market sentiment at a glance, improving decision-making speed during fast-moving markets.
Key Features and Customization
Kalman Filter Customization: The process noise and measurement noise parameters allow traders to adjust how aggressively the filter adapts to price changes, making it suitable for both volatile and stable markets.
Smoothing Options: A variety of moving average types, such as SMA, Hull, EMA, and more, can be applied to smooth the PSaR values, ensuring that the signal remains clear even in choppy markets.
Dynamic Trend Detection: The Kalman PSaR dynamically updates based on price movements, helping traders spot trend reversals early while filtering out false signals caused by short-term volatility.
Bar Coloring and PSaR Plotting: Traders can choose to color candles based on trend direction or plot the PSaR directly on the chart for additional visual clarity.
Practical Applications
Trend-Following Strategies: The Kalman PSaR excels in trend-following strategies by providing timely signals of trend changes. The dynamic nature of the indicator allows traders to capture significant price movements while avoiding market noise.
Reversal Identification: The indicator’s ability to filter out noise and provide smoother signals makes it ideal for identifying reversals in volatile markets.
Risk Management: By plotting clear stop levels based on the PSaR, traders can use this indicator to effectively manage risk, placing stop-loss orders at key points based on the trend direction.
Conclusion
The Kalman PSaR is a fusion of the classic Parabolic SAR and the Kalman filter, offering enhanced trend detection with reduced noise. Its customizable filtering and smoothing options, combined with dynamic trend-following capabilities, make it a versatile tool for traders seeking to improve their timing and signal accuracy. The adaptive nature of the Kalman filter, combined with the robust PSaR logic, helps traders stay on the right side of the market and manage risk more effectively.
Black-Scholes option price model & delta hedge strategyBlack-Scholes Option Pricing Model Strategy
The strategy is based on the Black-Scholes option pricing model and allows the calculation of option prices, various option metrics (the Greeks), and the creation of synthetic positions through delta hedging.
ATTENTION!
Trading derivative financial instruments involves high risks. The author of the strategy is not responsible for your financial results! The strategy is not self-sufficient for generating profit! It is created exclusively for constructing a synthetic derivative financial instrument. Also, there might be errors in the script, so use it at your own risk! I would appreciate it if you point out any mistakes in the comments! I would be even more grateful if you send the corrected code!
Application Scope
This strategy can be used for delta hedging short positions in sold options. For example, suppose you sold a call option on Bitcoin on the Deribit exchange with a strike price of $60,000 and an expiration date of September 27, 2024. Using this script, you can create a delta hedge to protect against the risk of loss in the option position if the price of Bitcoin rises.
Another example: Suppose you use staking of altcoins in your strategies, for which options are not available. By using this strategy, you can hedge the risk of a price drop (Put option). In this case, you won't lose money if the underlying asset price increases, unlike with a short futures position.
Another example: You received an airdrop, but your tokens will not be fully unlocked soon. Using this script, you can fully hedge your position and preserve their dollar value by the time the tokens are fully unlocked. And you won't fear the underlying asset price increasing, as the loss in the event of a price rise is limited to the option premium you will pay if you rebalance the portfolio.
Of course, this script can also be used for simple directional trading of momentum and mean reversion strategies!
Key Features and Input Parameters
1. Option settings:
- Style of option: "European vanilla", "Binary", "Asian geometric".
- Type of option: "Call" (bet on the rise) or "Put" (bet on the fall).
- Strike price: the option contract price.
- Expiration: the expiry date and time of the option contract.
2. Market statistic settings:
- Type of price source: open, high, low, close, hl2, hlc3, ohlc4, hlcc4 (using hl2, hlc3, ohlc4, hlcc4 allows smoothing the price in more volatile series).
- Risk-free return symbol: the risk-free rate for the market where the underlying asset is traded. For the cryptocurrency market, the return on the funding rate arbitrage strategy is accepted (a special function is written for its calculation based on the Premium Price).
- Volatility calculation model: realized (standard deviation over a moving period), implied (e.g., DVOL or VIX), or custom (you can specify a specific number in the field below). For the cryptocurrency market, the calculation of implied volatility is implemented based on the product of the realized volatility ratio of the considered asset and Bitcoin to the Bitcoin implied volatility index.
- User implied volatility: fixed implied volatility (used if "Custom" is selected in the "Volatility Calculation Method").
3. Display settings:
- Choose metric: what to display on the indicator scale – the price of the underlying asset, the option price, volatility, or Greeks (all are available).
- Measure: bps (basis points), percent. This parameter allows choosing the unit of measurement for the displayed metric (for all except the Greeks).
4. Trading settings:
- Hedge model: None (do not trade, default), Simple (just open a position for the full volume when the strike price is crossed), Synthetic option (creating a synthetic option based on the Black-Scholes model).
- Position side: Long, Short.
- Position size: the number of units of the underlying asset needed to create the option.
- Strategy start time: the moment in time after which the strategy will start working to create a synthetic option.
- Delta hedge interval: the interval in minutes for rebalancing the portfolio. For example, a value of 5 corresponds to rebalancing the portfolio every 5 minutes.
Post scriptum
My strategy based on the SegaRKO model. Many thanks to the author! Unfortunately, I don't have enough reputation points to include a link to the author in the description. You can find the original model via the link in the code, as well as through the search indicators on the charts by entering the name: "Black-Scholes Option Pricing Model". I have significantly improved the model: the calculation of volatility, risk-free rate and time value of the option have been reworked. The code performance has also been significantly optimized. And the most significant change is the execution, with which you can now trade using this script.

TradeTracker v33 - Interactive Journal [AR33_]TradeTracker v33 - Interactive Journal is a unique tool designed to enhance your trading experience by integrating an interactive journal directly onto your charts. Unlike traditional trading journals that require manual entries outside of TradingView, this script allows traders to document, track, and review their trades in real-time, right where the action happens.
What sets TradeTracker v33 apart from existing tools is its seamless blend of note-taking, task management, and performance tracking—all within a single, intuitive interface. With features like customizable checklists, due dates, and color-coded status indicators, this script provides a powerful and practical solution for traders who want to stay organized and disciplined.
2. Description
. TradeTracker v33 - Interactive Journal is designed to keep traders on track by allowing them to record trade-related notes, set tasks, and mark progress directly on their charts.
Here’s how it works:
• Purpose: The script serves as an all-in-one journal and task manager, helping traders document their trading strategies, track ongoing tasks, and review completed actions. It’s particularly useful for maintaining discipline and ensuring that every trade is executed according to a well-thought-out plan.
• How It Works:
• Interactive Notes and Tasks: Users can create and manage notes and tasks directly on their charts. Each note can be customized with a title, description, due date, and completion status.
• Status Indicators: Tasks are color-coded based on their status—green for completed, red for overdue, and default colors for pending tasks—allowing traders to quickly assess their progress.
• Dynamic Display: Notes are displayed in a clean, organized table on the chart, making it easy to review multiple tasks without cluttering the trading interface.
• Usage:
• Adding Notes: Simply fill in the note title, content, and optional due date within the script’s input settings, and the note will appear on your chart.
• Tracking Progress: Mark tasks as completed with a simple toggle, and the script will update their status in real-time.
• Customizing Your Workflow: Adjust the position, size, and visibility of notes to fit your trading style, ensuring that your journal supports rather than distracts from your trading activities.
3. Chart Presentation
To provide a clear and focused user experience, TradeTracker v33 - Interactive Journal is designed to be the sole feature on your chart when published. This ensures that users can easily identify and interact with their notes and tasks without any unnecessary distractions.
• Clean and Focused Display: The chart will exclusively display the interactive journal, showcasing how tasks and notes appear and update in real-time as you manage them.
• Useful Annotations: Annotations such as checkboxes and status indicators are clearly explained within the script’s description and are vital to understanding the functionality of the tool.
• Minimal Distractions: Only elements directly related to the script’s functionality are included on the chart, ensuring that users can easily follow along and implement the script in their own trading setup.

Enhanced Local Polynomial Regression [Yosiet]Local Polynomial Regression (LPR) is an advanced statistical method that offers a flexible approach to estimating the underlying trend in financial time series data.
The Mathematical Explanation
The core idea of LPR is to fit a polynomial of degree p at each point x using weighted least squares. The weight of each data point decreases with its distance from x, controlled by a kernel function and a bandwidth parameter.
The general form of the local polynomial estimator is:
β̂(x) = argmin Σ K((Xi - x) / h) (Yi - β0 - β1(Xi - x) - ... - βp(Xi - x)^p)^2
Where:
β̂(x) is the vector of estimated coefficients
K is the kernel function
h is the bandwidth
Xi and Yi are the predictor and response variables
p is the degree of the polynomial
Our implementation uses the Epanechnikov kernel:
K(u) = 3/4 * (1 - u^2) for |u| ≤ 1, 0 otherwise
The Implementation
This script implements LPR for the easier way to interpret its values with the following key components:
Input Parameters: Can adjust the lookback period, bandwidth, and polynomial degree.
Kernel Function: The Epanechnikov kernel is used for weighting.
LPR Function: Implements the core algorithm using matrix operations.
Signal Generation: Generates buy/sell signals based on crossovers of smoothed price and LPR results.
How to Use
Apply the indicator to your chart in TradingView.
Adjust the input parameters:
Lookback Period: Controls how many past bars are considered.
Bandwidth: Affects the smoothness of the regression line.
Polynomial Degree: Determines the complexity of the local fit.
Signal Smoothing Length: Adjusts the responsiveness of buy/sell signals.
Monitor buy/sell signals for potential trade entries.
Limitations
Sensitivity to Parameters: The choice of bandwidth and polynomial degree significantly impacts the results.
Lag: Like all trend-following indicators, LPR may lag behind rapid price movements.
Edge Effects: The indicator may be less reliable at the edges of the data (recent bars).
Recommendations
Parameter Optimization: Experiment with different lookback periods, bandwidths, and polynomial degrees to find the best fit for your trading style and timeframe.
Combine with Other Indicators: Use LPR in conjunction with momentum oscillators or volume indicators for confirmation.
Multiple Timeframes: Apply LPR on different timeframes to gain a more comprehensive view of the trend.
Avoid Overfitting: Be cautious of using high polynomial degrees, as they may lead to overfitting on historical data.
Consider Market Conditions: LPR works best in trending markets; be aware of its limitations in ranging or highly volatile conditions.
Backtest Thoroughly: Always backtest strategies based on LPR across different market conditions before live trading.
Conclusion
Local Polynomial Regression offers a sophisticated approach to trend analysis in financial markets. By providing a flexible, adaptive trend line, it can help traders identify potential entry and exit points with greater precision than traditional moving averages. However, like all technical indicators, it should be used as part of a comprehensive trading strategy that includes proper risk management and consideration of fundamental factors.
if you have an strategy or idea and need to make it real through an indicator or trading bot, you can DM or comment
Honey Badger and Dip and Rip Days**Definitions**
A Honey Badger Day is defined as a day where the market dips below a certain threshold but then closes above it. Specifically:
- The day's low is less than or equal to the lower of either the opening price or the previous day's closing price.
- The day's closing price is greater than or equal to this same lower threshold.
Dip and Rip Day:A Dip and Rip Day is characterized by a more pronounced dip followed by a stronger recovery. The criteria are:
- The day's low is below 0.11% of the lower of the day's opening price or the previous day's closing price.
- The day's closing price is at least 0.405% higher than its opening price.
- The day's closing price is at least 0.792% higher than its low.
- The day's closing price is at least 0.405% higher than the previous day's closing price.
Both patterns indicate a day where the market experiences a dip but then recovers, with the Dip and Rip pattern showing a more dramatic movement in both directions.
Buy script for stocks mathematical calculation chart. it is totally based on the square root calculation of previous day + 66.66% of Square root. ( last dat sqrt+66.66% of Sqrt). buy above the value. best for stock in intraday

VWAP SlopePublishing one of the simplest yet one of my favorite concepts. Had to publish since I didn't really find any script for this on TV.
VWAP slope.
This is nothing fancy because it's just calculating "slope" with a very basic level formula
vwap_slope = (vwap - vwap ) / length
Above zero line, it's positive zone.
Below zero line, it's a negative zone.
The idea is to avoid choppy conditions and stay true to larger readings, sometimes when we have vwap directly on chart and when price interacts with it, we tend to take the lot of bad trades.
The intention here is to avoid just that.
This is also good at tracking failure of change in sentiments, this failure is very important, because one's failure occurs there is significant movement in the opposite direction of the failure.
Since there isn't much alteration to this idea, there is not much to talk about tbh.
Just remember, this is an educational idea and not assurance of future performance.
Regards.

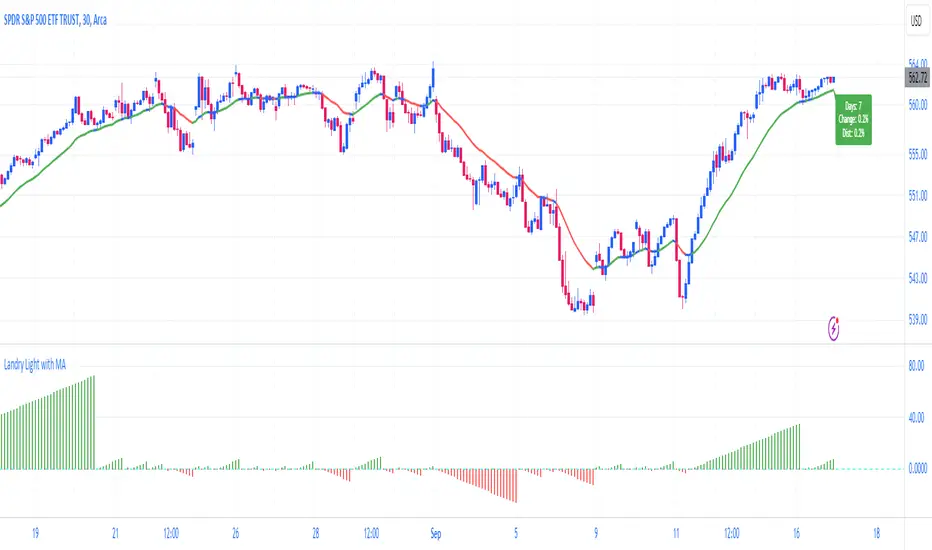
Landry Light with Moving AverageLandry Light with Moving Average
Overview:
This Pine Script, titled "Landry Light with Moving Average", visualizes the relationship between price action and a chosen moving average (MA) over time. It helps users easily identify periods where the price stays consistently above or below the moving average, which can be a useful indicator of bullish or bearish trends.
Key Features:
Moving Average Type Selection:
The script allows users to choose between two types of moving averages:
Exponential Moving Average (EMA)
Simple Moving Average (SMA)
This is done via a user input option, enabling traders to tailor the indicator to their preferred analysis method.
Moving Average Length:
Users can set the length of the moving average (default is 21 periods). This allows customization based on the trader's time frame, whether short-term or long-term analysis.
Dynamic Moving Average Color:
The moving average line changes color based on the relationship between the price and the MA:
Green: Price is consistently above the MA (bullish condition).
Red: Price is consistently below the MA (bearish condition).
Blue: Price is crossing or close to the MA (neutral or indecisive condition).
Cumulative Days Above/Below MA:
The script tracks and displays the number of consecutive days the price remains above or below the moving average:
Cumulative Days Above: Shown as a green histogram above the zero line.
Cumulative Days Below: Shown as a red histogram below the zero line.
This feature helps users identify sustained trends or potential reversals.
Real-time Labels:
The script generates dynamic labels that display the count of cumulative days the price has stayed above or below the moving average.
These labels are positioned near the moving average on the chart, providing an easy reference for traders.
How Users Can Benefit:
Trend Identification:
By visually representing how long the price stays above or below a key moving average, traders can identify strong bullish or bearish trends. This can inform entry and exit points.
Visualizing Market Sentiment:
The colored moving average line and histogram help traders quickly assess market sentiment. A prolonged green MA line suggests a strong uptrend, while a prolonged red line indicates a downtrend.
Adaptability:
With customizable moving average types and lengths, the indicator can be tailored to fit various trading strategies, whether for day trading, swing trading, or long-term investing.
Reversal Signals:
A shift from cumulative days above to cumulative days below (or vice versa) can serve as an early signal of a potential market reversal, allowing traders to adjust their positions accordingly.
Simplified Decision-Making:
The combination of visual cues (colors, histograms, and labels) simplifies decision-making, allowing traders to focus on trend strength rather than complex calculations.
Usage:
To use this script:
Add the Indicator to Your Chart:
Select the desired moving average type and length.
The script will plot the moving average, colored by the trend, and display cumulative days above or below it.
Interpret the Signals:
Use the histogram and labels to gauge the strength of the trend.
Monitor color changes in the moving average for potential trend reversals.
Incorporate into Your Strategy:
Combine this indicator with other tools (e.g., volume analysis, RSI) to confirm signals and refine your trading strategy.
This indicator is particularly useful for traders who follow the "Landry Light" concept, emphasizing the importance of price staying above or below a moving average to determine trend strength.
lib_no_delayLibrary "lib_no_delay"
This library contains modifications to standard functions that return na before reaching the bar of their 'length' parameter.
That is because they do not compromise speed at current time for correct results in the past. This is good for live trading in short timeframes but killing applications on Monthly / Weekly timeframes if instruments, like in crypto, do not have extensive history (why would you even trade the monthly on a meme coin ... not my decision).
Also, some functions rely on source (value at previous bar), which is not available on bar 1 and therefore cascading to a na value up to the last bar ... which in turn leads to a non displaying indicator and waste of time debugging this)
Anyway ... there you go, let me know if I should add more functions.
sma(source, length)
Parameters:
source (float) : Series of values to process.
length (simple int) : Number of bars (length).
Returns: Simple moving average of source for length bars back.
ema(source, length)
Parameters:
source (float) : Series of values to process.
length (simple int) : Number of bars (length).
Returns: (float) The exponentially weighted moving average of the source.
rma(source, length)
Parameters:
source (float) : Series of values to process.
length (simple int) : Number of bars (length).
Returns: Exponential moving average of source with alpha = 1 / length.
atr(length)
Function atr (average true range) returns the RMA of true range. True range is max(high - low, abs(high - close ), abs(low - close )). This adapted version extends ta.atr to start without delay at first bar and deliver usable data instead of na by averaging ta.tr(true) via manual SMA.
Parameters:
length (simple int) : Number of bars back (length).
Returns: Average true range.
rsi(source, length)
Relative strength index. It is calculated using the ta.rma() of upward and downward changes of source over the last length bars. This adapted version extends ta.rsi to start without delay at first bar and deliver usable data instead of na.
Parameters:
source (float) : Series of values to process.
length (simple int) : Number of bars back (length).
Returns: Relative Strength Index.
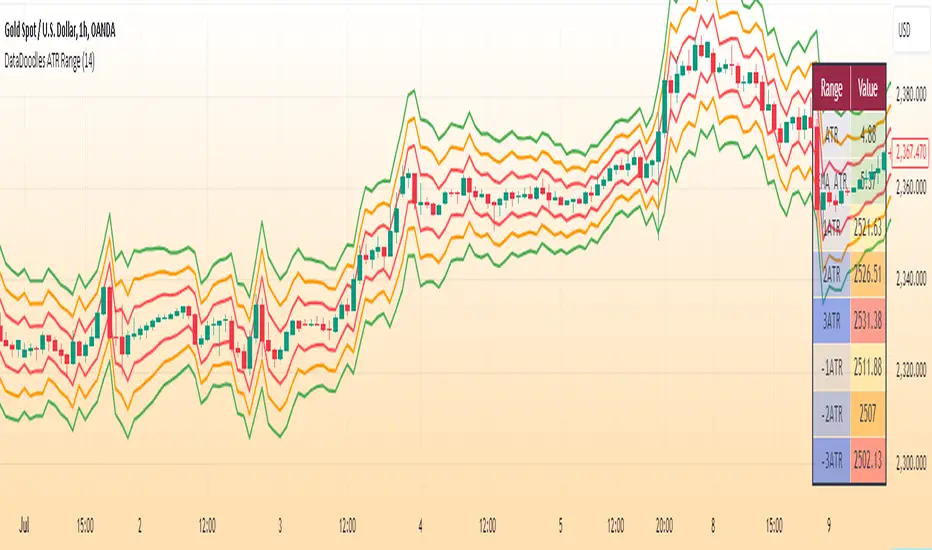
DataDoodles ATR RangeThe "DataDoodles ATR Range" indicator provides a comprehensive visual representation of the Average True Range (ATR) levels based on the previous bar's close price . It includes both the raw ATR and an Exponential Moving Average (EMA) of the ATR to offer a smoother view of the range volatility. This indicator is ideal for traders who want to quickly assess potential price movements relative to recent volatility.
Key Features:
ATR Levels Above and Below Close: The indicator calculates and displays three levels of ATR-based ranges above and below the previous close price. These levels are visualized on the chart using distinct colors:
- 1ATR Above/Below
- 2ATR Above/Below
- 3ATR Above/Below
EMA of ATR
Includes the EMA of ATR to provide a smoother trend of the ATR values, helping traders identify long-term volatility trends.
Color-Coded Ranges: The plotted ranges are color-coded for easy identification, with warm gradient tones applied to the corresponding data table for quick reference.
Customizable Table: A data table is displayed at the bottom right corner of the chart, providing real-time values for ATR, EMA ATR, and the various ATR ranges.
Usage
This indicator is useful for traders who rely on volatility analysis to set stop losses, take profit levels, or simply understand the current market conditions. By visualizing ATR ranges directly on the chart, traders can better anticipate potential price movements and adjust their strategies accordingly.
Customization
ATR Length: The default ATR length is set to 14 but can be customized to fit your trading strategy.
Table Positioning: The data table is placed in the bottom right corner by default but can be moved as needed.
How to Use
Add the "DataDoodles ATR Range" indicator to your chart.
Observe the plotted lines for potential support and resistance levels based on recent volatility.
Use the data table for quick reference to ATR values and range levels.
Disclaimer: This indicator is a tool for analysis and should be used in conjunction with other indicators and analysis methods. Always practice proper risk management and consider market conditions before making trading decisions.
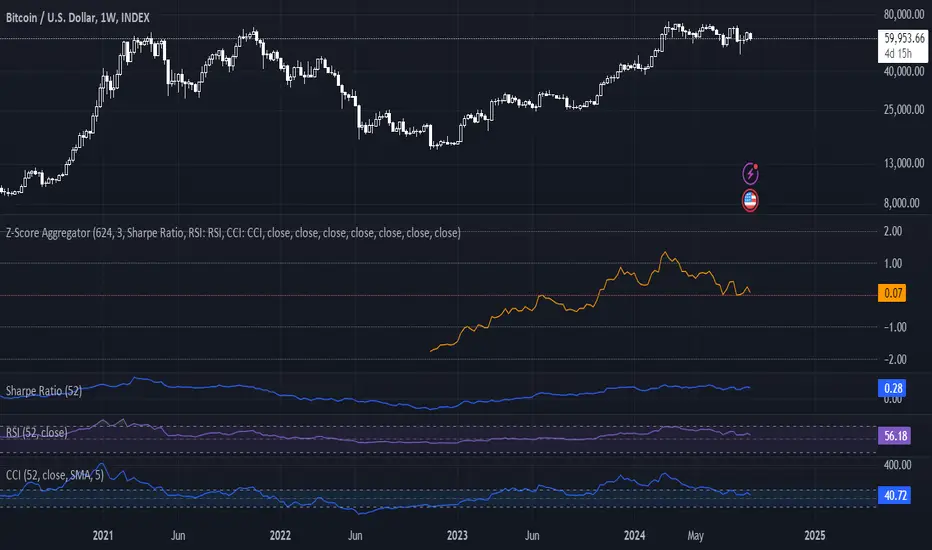
Z-Score AggregatorOverview:
This indicator is designed to take multiple other indicators as inputs, calculate their respective Z-scores, and then aggregate these Z-scores to provide a comprehensive measure. By transforming the inputs into Z-scores, this indicator standardizes the data, enabling a more accurate comparison across different indicators, each of which may have different scales and distributions.
This indicator is beneficial for Mean-Reversion style trading and investing as it standardizes indicators and lets them work together in one system.
The Z-score, which represents how many standard deviations an element is from the mean, is a crucial statistical tool in this process. It allows the indicator to normalize the varying data points, ensuring that each indicator's contribution to the aggregate score is proportional to its deviation from the average performance.
Inputs:
Z-score length: How far Back it will take into account the inputs
Number Of Sources: This is to set the number of inputs the indicator uses so it calculates them properly and uses only the number of indicators you want.
Source Inputs: 1-10 inputs (no need to use them all as long as you set the number of used indicators beforehand).
Note:
There are three indicators used in this example which are CCI, RSI and Sharpe Ratio. The indicator calculates their individual Z-scores and takes an average. Because Number Of Sources is set to 3 it only uses the first 3 indicators in use.