PA-Adaptive Hull Parabolic [Loxx]The PA-Adaptive Hull Parabolic is not your typical trading indicator. It synthesizes the computational brilliance of two famed technicians: John Ehlers and John Hull. Let's demystify its sophistication.
█ Ehlers' Phase Accumulation
John Ehlers is well-known in the trading community for his digital signal processing approach to market data. One of his standout techniques is phase accumulation. This method identifies the dominant cycle in the market by accumulating the phases of individual cycles. By doing so, it "adapts" to real-time market conditions.
Here's the brilliance of phase accumulation in this code
The indicator doesn't merely use a static look-back period. Instead, it dynamically determines the dominant market cycle through phase accumulation.
The calcComp function, rooted in Ehlers' methodology, provides a complex computation using a digital signal processing approach to filter out market noise and pinpoint the current cycle's frequency.
By measuring and adapting to the instantaneous period of the market, it ensures that the indicator remains relevant, especially in non-stationary market conditions.
Hull's Moving Average
John Hull introduced the Hull Moving Average (HMA) aiming to reduce lag and improve smoothing. The HMA's essence lies in its weighted average computation, prioritizing more recent prices.
This code takes an adaptive twist on the HMA
Instead of a fixed period, the HMA uses the dominant cycle length derived from Ehlers' phase accumulation. This makes the HMA not just fast and smooth, but also adaptive to the dominant market rhythm.
The intricate iLwmp function in the script provides this adaptive HMA computation. It's a weighted moving average, but its length isn't static; it's based on the previously determined dominant market cycle.
█ Trading Insights
The indicator paints the bars to represent the immediate trend: green for bullish and red for bearish.
Entry points, both long ("L") and short ("S"), are presented visually. These are derived from crossovers of the adaptive HMA, a clear indication of a potential shift in the trend.
Additionally, alert conditions are set, ready to notify a trader when these crossovers occur, ensuring real-time actionable insights.
█ Conclusion
The PA-Adaptive Hull Parabolic is a masterclass in advanced technical indicator design. By marrying John Ehlers' adaptive phase accumulation with John Hull's HMA, it creates a dynamic, responsive, and precise tool for traders. It's not just about capturing the trend; it's about understanding the very rhythm of the market.
Loxx

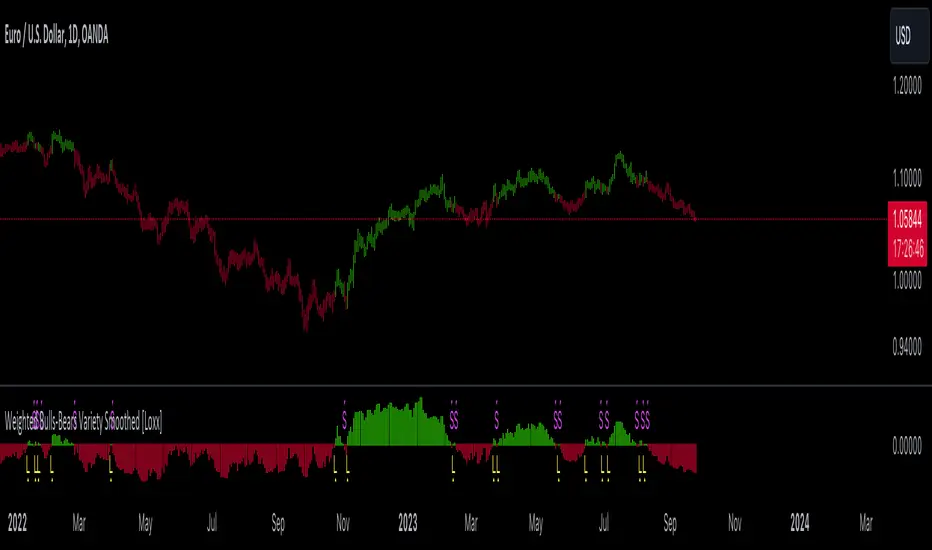
Weighted Bulls-Bears Variety Smoothed [Loxx]Weighted Bulls-Bears Variety Smoothed highlights potential buy and sell moments in the market. Users can customize the data source and select their preferred type of moving average for calculations. The resulting visualization is a column-style plot that changes color based on bullish or bearish market conditions. Additionally, the script can color chart bars and provide visual markers to indicate buying ("Long") or selling ("Short") opportunities. Alerts can also be set for these trading signals.
█ Inputs:
Users can choose the source for calculations (e.g., closing price).
They can set periods for calculations and smoothing.
They can select the type of moving average they prefer for smoothing: EMA, FEMA, LWMA, SMA, or SMMA.
█ Weighted Bulls-Bears Calculation:
It determines the highest and lowest prices over a user-defined period.
Then, it calculates the 'bull' and 'bear' values based on these highest and lowest prices. These values are weighted based on their distance from the current price.
█ Extras
Alerts
Signals
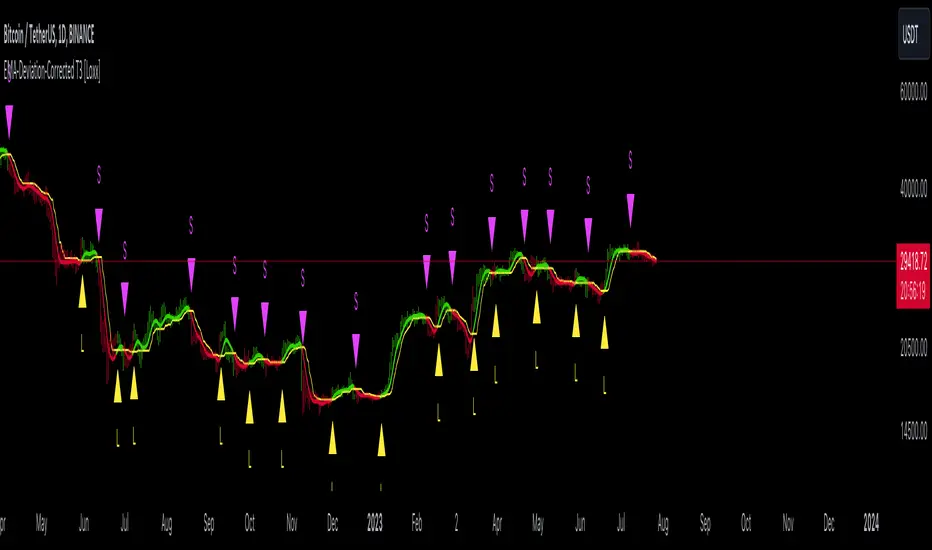
EMA-Deviation-Corrected T3 [Loxx]EMA-Deviation-Corrected T3 is a T3 moving average that uses EMA deviation correcting to produce signals. This comes via the beloved genius Mladen.
The origin of the correcting algorithm can be attributed to Dr. Alexander Uhl, who developed a method to filter the moving average and identify signals. Originally, this method utilized standard deviation as a measure to correct the average values.
However, the current indicator in question employs a modified version of the correcting method. Instead of using standard deviation for calculation, it uses EMA deviation, which stands for Exponential Moving Average deviation. The idea behind using EMA deviation is two-fold:
Efficiency: EMA deviation can be calculated faster than standard deviation, resulting in more efficient code execution.
Signal Reduction: Surprisingly, this modified "correcting" approach generates fewer signals compared to using standard deviation. This is because EMA deviation is more responsive to price changes, making the correcting process less sensitive to whipsaws or false signals.
What is T3?
The T3 moving average, short for "Tim Tillson's Triple Exponential Moving Average," is a technical indicator used in financial markets and technical analysis to smooth out price data over a specific period. It was developed by Tim Tillson, a software project manager at Hewlett-Packard, with expertise in Mathematics and Computer Science.
The T3 moving average is an enhancement of the traditional Exponential Moving Average (EMA) and aims to overcome some of its limitations. The primary goal of the T3 moving average is to provide a smoother representation of price trends while minimizing lag compared to other moving averages like Simple Moving Average (SMA), Weighted Moving Average (WMA), or EMA.
To compute the T3 moving average, it involves a triple smoothing process using exponential moving averages. Here's how it works:
Calculate the first exponential moving average (EMA1) of the price data over a specific period 'n.'
Calculate the second exponential moving average (EMA2) of EMA1 using the same period 'n.'
Calculate the third exponential moving average (EMA3) of EMA2 using the same period 'n.'
The formula for the T3 moving average is as follows:
T3 = 3 * (EMA1) - 3 * (EMA2) + (EMA3)
By applying this triple smoothing process, the T3 moving average is intended to offer reduced noise and improved responsiveness to price trends. It achieves this by incorporating multiple time frames of the exponential moving averages, resulting in a more accurate representation of the underlying price action.
Included
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
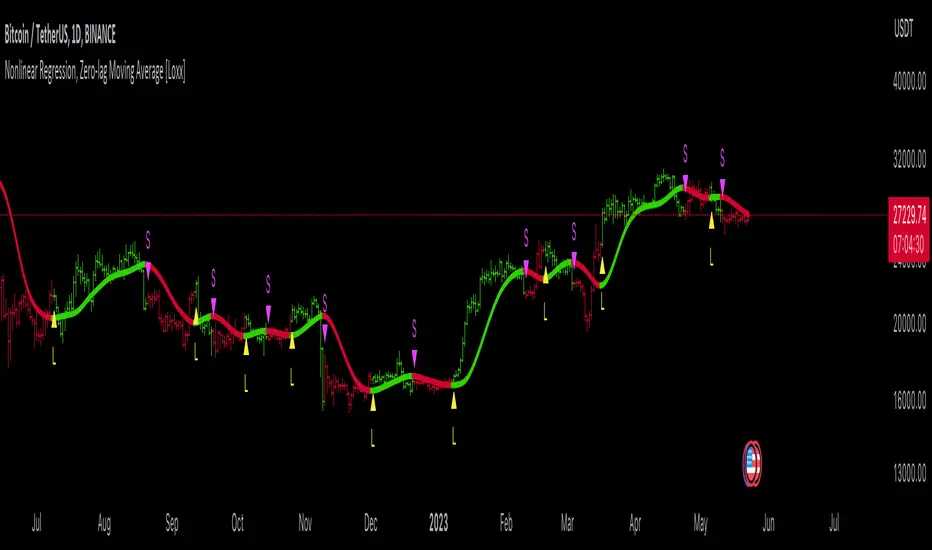
Nonlinear Regression, Zero-lag Moving Average [Loxx]Nonlinear Regression and Zero-lag Moving Average
Technical indicators are widely used in financial markets to analyze price data and make informed trading decisions. This indicator presents an implementation of two popular indicators: Nonlinear Regression and Zero-lag Moving Average (ZLMA). Let's explore the functioning of these indicators and discuss their significance in technical analysis.
Nonlinear Regression
The Nonlinear Regression indicator aims to fit a nonlinear curve to a given set of data points. It calculates the best-fit curve by minimizing the sum of squared errors between the actual data points and the predicted values on the curve. The curve is determined by solving a system of equations derived from the data points.
We define a function "nonLinearRegression" that takes two parameters: "src" (the input data series) and "per" (the period over which the regression is calculated). It calculates the coefficients of the nonlinear curve using the least squares method and returns the predicted value for the current period. The nonlinear regression curve provides insights into the overall trend and potential reversals in the price data.
Zero-lag Moving Average (ZLMA)
Moving averages are widely used to smoothen price data and identify trend directions. However, traditional moving averages introduce a lag due to the inclusion of past data. The Zero-lag Moving Average (ZLMA) overcomes this lag by dynamically adjusting the weights of past values, resulting in a more responsive moving average.
We create a function named "zlma" that calculates the ZLMA. It takes two parameters: "src" (the input data series) and "per" (the period over which the ZLMA is calculated). The ZLMA is computed by first calculating a weighted moving average (LWMA) using a linearly decreasing weight scheme. The LWMA is then used to calculate the ZLMA by applying the same weight scheme again. The ZLMA provides a smoother representation of the price data while reducing lag.
Combining Nonlinear Regression and ZLMA
The ZLMA is applied to the input data series using the function "zlma(src, zlmaper)". The ZLMA values are then passed as input to the "nonLinearRegression" function, along with the specified period for nonlinear regression. The output of the nonlinear regression is stored in the variable "out".
To enhance the visual representation of the indicator, colors are assigned based on the relationship between the nonlinear regression value and a signal value (sig) calculated from the previous period's nonlinear regression value. If the current "out" value is greater than the previous "sig" value, the color is set to green; otherwise, it is set to red.
The indicator also includes optional features such as coloring the bars based on the indicator's values and displaying signals for potential long and short positions. The signals are generated based on the crossover and crossunder of the "out" and "sig" values.
Wrapping Up
This indicator combines two important concepts: Nonlinear Regression and Zero-lag Moving Average indicators, which are valuable tools for technical analysis in financial markets. These indicators help traders identify trends, potential reversals, and generate trading signals. By combining the nonlinear regression curve with the zero-lag moving average, this indicator provides a comprehensive view of the price dynamics. Traders can customize the indicator's settings and use it in conjunction with other analysis techniques to make well-informed trading decisions.
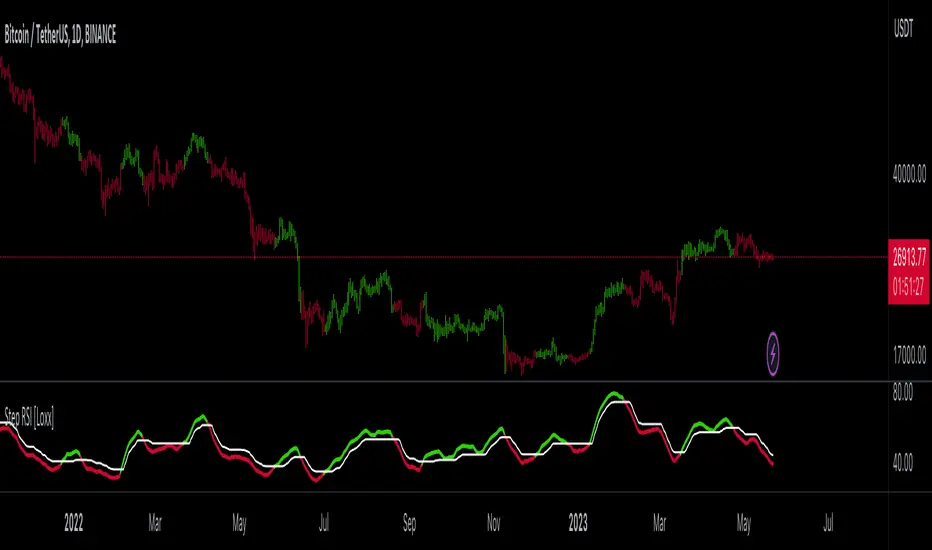
Step RSI [Loxx]Enhanced Moving Average Calculation with Stepped Moving Average and the Advantages over Regular RSI
Technical analysis plays a crucial role in understanding and predicting market trends. One popular indicator used by traders and analysts is the Relative Strength Index (RSI). However, an enhanced approach called Stepped Moving Average, in combination with the Slow RSI function, offers several advantages over regular RSI calculations.
Stepped Moving Average and Moving Averages:
The Stepped Moving Average function serves as a crucial component in the calculation of moving averages. Moving averages smooth out price data over a specific period to identify trends and potential trading signals. By employing the Stepped Moving Average function, traders can enhance the accuracy of moving averages and make more informed decisions.
Stepped Moving Average takes two parameters: the current RSI value and a size parameter. It computes the next step in the moving average calculation by determining the upper and lower bounds of the moving average range. It accomplishes this by adjusting the values of smax and smin based on the given RSI and size.
Furthermore, Stepped Moving Average introduces the concept of a trend variable. By comparing the previous trend value with the current RSI and the previous upper and lower bounds, it updates the trend accordingly. This feature enables traders to identify potential shifts in market sentiment and make timely adjustments to their trading strategies.
Advantages over Regular RSI:
Enhanced Range Boundaries:
The inclusion of size parameters in Stepped Moving Average allows for more precise determination of the upper and lower bounds of the moving average range. This feature provides traders with a clearer understanding of the potential price levels that can influence market behavior. Consequently, it aids in setting more effective entry and exit points for trades.
Improved Trend Identification:
The trend variable in Stepped Moving Average helps traders identify changes in market trends more accurately. By considering the previous trend value and comparing it to the current RSI and previous bounds, Stepped Moving Average captures trend reversals with greater precision. This capability empowers traders to respond swiftly to market shifts and potentially capture more profitable trading opportunities.
Smoother Moving Averages:
Stepped Moving Average's ability to adjust the moving average range bounds based on trend changes and size parameters results in smoother moving averages. Regular RSI calculations may produce jagged or erratic results due to abrupt market movements. Stepped Moving Average mitigates this issue by dynamically adapting the range boundaries, thereby providing traders with more reliable and consistent moving average signals.
Complementary Functionality with Slow RSI:
Stepped Moving Average and Slow RSI function in harmony to provide a comprehensive trading analysis toolkit. While Stepped Moving Average refines the moving average calculation process, Slow RSI offers a more accurate representation of market strength. The combination of these two functions facilitates a deeper understanding of market dynamics and assists traders in making better-informed decisions.
Extras
-Alerts
-Signals
Endpointed SSA of Price [Loxx]The Endpointed SSA of Price: A Comprehensive Tool for Market Analysis and Decision-Making
The financial markets present sophisticated challenges for traders and investors as they navigate the complexities of market behavior. To effectively interpret and capitalize on these complexities, it is crucial to employ powerful analytical tools that can reveal hidden patterns and trends. One such tool is the Endpointed SSA of Price, which combines the strengths of Caterpillar Singular Spectrum Analysis, a sophisticated time series decomposition method, with insights from the fields of economics, artificial intelligence, and machine learning.
The Endpointed SSA of Price has its roots in the interdisciplinary fusion of mathematical techniques, economic understanding, and advancements in artificial intelligence. This unique combination allows for a versatile and reliable tool that can aid traders and investors in making informed decisions based on comprehensive market analysis.
The Endpointed SSA of Price is not only valuable for experienced traders but also serves as a useful resource for those new to the financial markets. By providing a deeper understanding of market forces, this innovative indicator equips users with the knowledge and confidence to better assess risks and opportunities in their financial pursuits.
█ Exploring Caterpillar SSA: Applications in AI, Machine Learning, and Finance
Caterpillar SSA (Singular Spectrum Analysis) is a non-parametric method for time series analysis and signal processing. It is based on a combination of principles from classical time series analysis, multivariate statistics, and the theory of random processes. The method was initially developed in the early 1990s by a group of Russian mathematicians, including Golyandina, Nekrutkin, and Zhigljavsky.
Background Information:
SSA is an advanced technique for decomposing time series data into a sum of interpretable components, such as trend, seasonality, and noise. This decomposition allows for a better understanding of the underlying structure of the data and facilitates forecasting, smoothing, and anomaly detection. Caterpillar SSA is a particular implementation of SSA that has proven to be computationally efficient and effective for handling large datasets.
Uses in AI and Machine Learning:
In recent years, Caterpillar SSA has found applications in various fields of artificial intelligence (AI) and machine learning. Some of these applications include:
1. Feature extraction: Caterpillar SSA can be used to extract meaningful features from time series data, which can then serve as inputs for machine learning models. These features can help improve the performance of various models, such as regression, classification, and clustering algorithms.
2. Dimensionality reduction: Caterpillar SSA can be employed as a dimensionality reduction technique, similar to Principal Component Analysis (PCA). It helps identify the most significant components of a high-dimensional dataset, reducing the computational complexity and mitigating the "curse of dimensionality" in machine learning tasks.
3. Anomaly detection: The decomposition of a time series into interpretable components through Caterpillar SSA can help in identifying unusual patterns or outliers in the data. Machine learning models trained on these decomposed components can detect anomalies more effectively, as the noise component is separated from the signal.
4. Forecasting: Caterpillar SSA has been used in combination with machine learning techniques, such as neural networks, to improve forecasting accuracy. By decomposing a time series into its underlying components, machine learning models can better capture the trends and seasonality in the data, resulting in more accurate predictions.
Application in Financial Markets and Economics:
Caterpillar SSA has been employed in various domains within financial markets and economics. Some notable applications include:
1. Stock price analysis: Caterpillar SSA can be used to analyze and forecast stock prices by decomposing them into trend, seasonal, and noise components. This decomposition can help traders and investors better understand market dynamics, detect potential turning points, and make more informed decisions.
2. Economic indicators: Caterpillar SSA has been used to analyze and forecast economic indicators, such as GDP, inflation, and unemployment rates. By decomposing these time series, researchers can better understand the underlying factors driving economic fluctuations and develop more accurate forecasting models.
3. Portfolio optimization: By applying Caterpillar SSA to financial time series data, portfolio managers can better understand the relationships between different assets and make more informed decisions regarding asset allocation and risk management.
Application in the Indicator:
In the given indicator, Caterpillar SSA is applied to a financial time series (price data) to smooth the series and detect significant trends or turning points. The method is used to decompose the price data into a set number of components, which are then combined to generate a smoothed signal. This signal can help traders and investors identify potential entry and exit points for their trades.
The indicator applies the Caterpillar SSA method by first constructing the trajectory matrix using the price data, then computing the singular value decomposition (SVD) of the matrix, and finally reconstructing the time series using a selected number of components. The reconstructed series serves as a smoothed version of the original price data, highlighting significant trends and turning points. The indicator can be customized by adjusting the lag, number of computations, and number of components used in the reconstruction process. By fine-tuning these parameters, traders and investors can optimize the indicator to better match their specific trading style and risk tolerance.
Caterpillar SSA is versatile and can be applied to various types of financial instruments, such as stocks, bonds, commodities, and currencies. It can also be combined with other technical analysis tools or indicators to create a comprehensive trading system. For example, a trader might use Caterpillar SSA to identify the primary trend in a market and then employ additional indicators, such as moving averages or RSI, to confirm the trend and generate trading signals.
In summary, Caterpillar SSA is a powerful time series analysis technique that has found applications in AI and machine learning, as well as financial markets and economics. By decomposing a time series into interpretable components, Caterpillar SSA enables better understanding of the underlying structure of the data, facilitating forecasting, smoothing, and anomaly detection. In the context of financial trading, the technique is used to analyze price data, detect significant trends or turning points, and inform trading decisions.
█ Input Parameters
This indicator takes several inputs that affect its signal output. These inputs can be classified into three categories: Basic Settings, UI Options, and Computation Parameters.
Source: This input represents the source of price data, which is typically the closing price of an asset. The user can select other price data, such as opening price, high price, or low price. The selected price data is then utilized in the Caterpillar SSA calculation process.
Lag: The lag input determines the window size used for the time series decomposition. A higher lag value implies that the SSA algorithm will consider a longer range of historical data when extracting the underlying trend and components. This parameter is crucial, as it directly impacts the resulting smoothed series and the quality of extracted components.
Number of Computations: This input, denoted as 'ncomp,' specifies the number of eigencomponents to be considered in the reconstruction of the time series. A smaller value results in a smoother output signal, while a higher value retains more details in the series, potentially capturing short-term fluctuations.
SSA Period Normalization: This input is used to normalize the SSA period, which adjusts the significance of each eigencomponent to the overall signal. It helps in making the algorithm adaptive to different timeframes and market conditions.
Number of Bars: This input specifies the number of bars to be processed by the algorithm. It controls the range of data used for calculations and directly affects the computation time and the output signal.
Number of Bars to Render: This input sets the number of bars to be plotted on the chart. A higher value slows down the computation but provides a more comprehensive view of the indicator's performance over a longer period. This value controls how far back the indicator is rendered.
Color bars: This boolean input determines whether the bars should be colored according to the signal's direction. If set to true, the bars are colored using the defined colors, which visually indicate the trend direction.
Show signals: This boolean input controls the display of buy and sell signals on the chart. If set to true, the indicator plots shapes (triangles) to represent long and short trade signals.
Static Computation Parameters:
The indicator also includes several internal parameters that affect the Caterpillar SSA algorithm, such as Maxncomp, MaxLag, and MaxArrayLength. These parameters set the maximum allowed values for the number of computations, the lag, and the array length, ensuring that the calculations remain within reasonable limits and do not consume excessive computational resources.
█ A Note on Endpionted, Non-repainting Indicators
An endpointed indicator is one that does not recalculate or repaint its past values based on new incoming data. In other words, the indicator's previous signals remain the same even as new price data is added. This is an important feature because it ensures that the signals generated by the indicator are reliable and accurate, even after the fact.
When an indicator is non-repainting or endpointed, it means that the trader can have confidence in the signals being generated, knowing that they will not change as new data comes in. This allows traders to make informed decisions based on historical signals, without the fear of the signals being invalidated in the future.
In the case of the Endpointed SSA of Price, this non-repainting property is particularly valuable because it allows traders to identify trend changes and reversals with a high degree of accuracy, which can be used to inform trading decisions. This can be especially important in volatile markets where quick decisions need to be made.

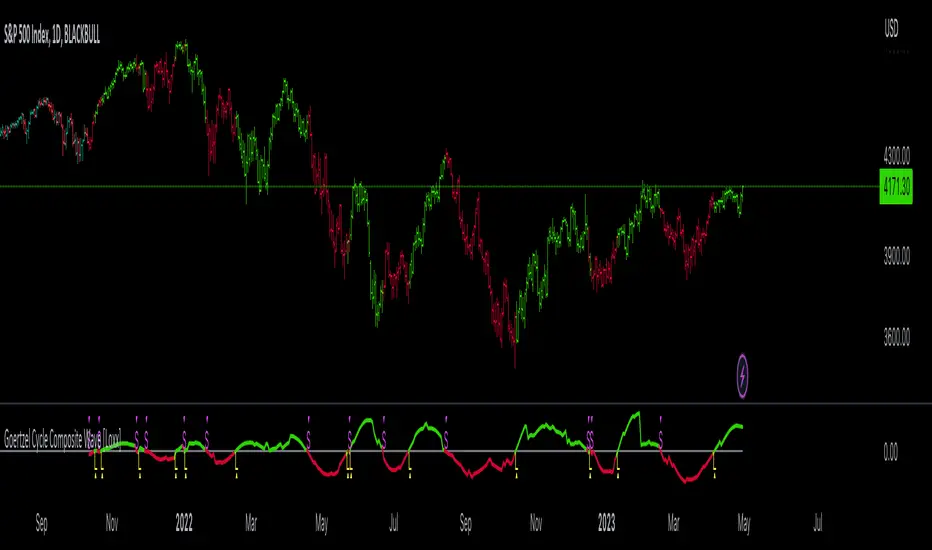
Goertzel Cycle Composite Wave [Loxx]As the financial markets become increasingly complex and data-driven, traders and analysts must leverage powerful tools to gain insights and make informed decisions. One such tool is the Goertzel Cycle Composite Wave indicator, a sophisticated technical analysis indicator that helps identify cyclical patterns in financial data. This powerful tool is capable of detecting cyclical patterns in financial data, helping traders to make better predictions and optimize their trading strategies. With its unique combination of mathematical algorithms and advanced charting capabilities, this indicator has the potential to revolutionize the way we approach financial modeling and trading.
*** To decrease the load time of this indicator, only XX many bars back will render to the chart. You can control this value with the setting "Number of Bars to Render". This doesn't have anything to do with repainting or the indicator being endpointed***
█ Brief Overview of the Goertzel Cycle Composite Wave
The Goertzel Cycle Composite Wave is a sophisticated technical analysis tool that utilizes the Goertzel algorithm to analyze and visualize cyclical components within a financial time series. By identifying these cycles and their characteristics, the indicator aims to provide valuable insights into the market's underlying price movements, which could potentially be used for making informed trading decisions.
The Goertzel Cycle Composite Wave is considered a non-repainting and endpointed indicator. This means that once a value has been calculated for a specific bar, that value will not change in subsequent bars, and the indicator is designed to have a clear start and end point. This is an important characteristic for indicators used in technical analysis, as it allows traders to make informed decisions based on historical data without the risk of hindsight bias or future changes in the indicator's values. This means traders can use this indicator trading purposes.
The repainting version of this indicator with forecasting, cycle selection/elimination options, and data output table can be found here:
Goertzel Browser
The primary purpose of this indicator is to:
1. Detect and analyze the dominant cycles present in the price data.
2. Reconstruct and visualize the composite wave based on the detected cycles.
To achieve this, the indicator performs several tasks:
1. Detrending the price data: The indicator preprocesses the price data using various detrending techniques, such as Hodrick-Prescott filters, zero-lag moving averages, and linear regression, to remove the underlying trend and focus on the cyclical components.
2. Applying the Goertzel algorithm: The indicator applies the Goertzel algorithm to the detrended price data, identifying the dominant cycles and their characteristics, such as amplitude, phase, and cycle strength.
3. Constructing the composite wave: The indicator reconstructs the composite wave by combining the detected cycles, either by using a user-defined list of cycles or by selecting the top N cycles based on their amplitude or cycle strength.
4. Visualizing the composite wave: The indicator plots the composite wave, using solid lines for the cycles. The color of the lines indicates whether the wave is increasing or decreasing.
This indicator is a powerful tool that employs the Goertzel algorithm to analyze and visualize the cyclical components within a financial time series. By providing insights into the underlying price movements, the indicator aims to assist traders in making more informed decisions.
█ What is the Goertzel Algorithm?
The Goertzel algorithm, named after Gerald Goertzel, is a digital signal processing technique that is used to efficiently compute individual terms of the Discrete Fourier Transform (DFT). It was first introduced in 1958, and since then, it has found various applications in the fields of engineering, mathematics, and physics.
The Goertzel algorithm is primarily used to detect specific frequency components within a digital signal, making it particularly useful in applications where only a few frequency components are of interest. The algorithm is computationally efficient, as it requires fewer calculations than the Fast Fourier Transform (FFT) when detecting a small number of frequency components. This efficiency makes the Goertzel algorithm a popular choice in applications such as:
1. Telecommunications: The Goertzel algorithm is used for decoding Dual-Tone Multi-Frequency (DTMF) signals, which are the tones generated when pressing buttons on a telephone keypad. By identifying specific frequency components, the algorithm can accurately determine which button has been pressed.
2. Audio processing: The algorithm can be used to detect specific pitches or harmonics in an audio signal, making it useful in applications like pitch detection and tuning musical instruments.
3. Vibration analysis: In the field of mechanical engineering, the Goertzel algorithm can be applied to analyze vibrations in rotating machinery, helping to identify faulty components or signs of wear.
4. Power system analysis: The algorithm can be used to measure harmonic content in power systems, allowing engineers to assess power quality and detect potential issues.
The Goertzel algorithm is used in these applications because it offers several advantages over other methods, such as the FFT:
1. Computational efficiency: The Goertzel algorithm requires fewer calculations when detecting a small number of frequency components, making it more computationally efficient than the FFT in these cases.
2. Real-time analysis: The algorithm can be implemented in a streaming fashion, allowing for real-time analysis of signals, which is crucial in applications like telecommunications and audio processing.
3. Memory efficiency: The Goertzel algorithm requires less memory than the FFT, as it only computes the frequency components of interest.
4. Precision: The algorithm is less susceptible to numerical errors compared to the FFT, ensuring more accurate results in applications where precision is essential.
The Goertzel algorithm is an efficient digital signal processing technique that is primarily used to detect specific frequency components within a signal. Its computational efficiency, real-time capabilities, and precision make it an attractive choice for various applications, including telecommunications, audio processing, vibration analysis, and power system analysis. The algorithm has been widely adopted since its introduction in 1958 and continues to be an essential tool in the fields of engineering, mathematics, and physics.
█ Goertzel Algorithm in Quantitative Finance: In-Depth Analysis and Applications
The Goertzel algorithm, initially designed for signal processing in telecommunications, has gained significant traction in the financial industry due to its efficient frequency detection capabilities. In quantitative finance, the Goertzel algorithm has been utilized for uncovering hidden market cycles, developing data-driven trading strategies, and optimizing risk management. This section delves deeper into the applications of the Goertzel algorithm in finance, particularly within the context of quantitative trading and analysis.
Unveiling Hidden Market Cycles:
Market cycles are prevalent in financial markets and arise from various factors, such as economic conditions, investor psychology, and market participant behavior. The Goertzel algorithm's ability to detect and isolate specific frequencies in price data helps trader analysts identify hidden market cycles that may otherwise go unnoticed. By examining the amplitude, phase, and periodicity of each cycle, traders can better understand the underlying market structure and dynamics, enabling them to develop more informed and effective trading strategies.
Developing Quantitative Trading Strategies:
The Goertzel algorithm's versatility allows traders to incorporate its insights into a wide range of trading strategies. By identifying the dominant market cycles in a financial instrument's price data, traders can create data-driven strategies that capitalize on the cyclical nature of markets.
For instance, a trader may develop a mean-reversion strategy that takes advantage of the identified cycles. By establishing positions when the price deviates from the predicted cycle, the trader can profit from the subsequent reversion to the cycle's mean. Similarly, a momentum-based strategy could be designed to exploit the persistence of a dominant cycle by entering positions that align with the cycle's direction.
Enhancing Risk Management:
The Goertzel algorithm plays a vital role in risk management for quantitative strategies. By analyzing the cyclical components of a financial instrument's price data, traders can gain insights into the potential risks associated with their trading strategies.
By monitoring the amplitude and phase of dominant cycles, a trader can detect changes in market dynamics that may pose risks to their positions. For example, a sudden increase in amplitude may indicate heightened volatility, prompting the trader to adjust position sizing or employ hedging techniques to protect their portfolio. Additionally, changes in phase alignment could signal a potential shift in market sentiment, necessitating adjustments to the trading strategy.
Expanding Quantitative Toolkits:
Traders can augment the Goertzel algorithm's insights by combining it with other quantitative techniques, creating a more comprehensive and sophisticated analysis framework. For example, machine learning algorithms, such as neural networks or support vector machines, could be trained on features extracted from the Goertzel algorithm to predict future price movements more accurately.
Furthermore, the Goertzel algorithm can be integrated with other technical analysis tools, such as moving averages or oscillators, to enhance their effectiveness. By applying these tools to the identified cycles, traders can generate more robust and reliable trading signals.
The Goertzel algorithm offers invaluable benefits to quantitative finance practitioners by uncovering hidden market cycles, aiding in the development of data-driven trading strategies, and improving risk management. By leveraging the insights provided by the Goertzel algorithm and integrating it with other quantitative techniques, traders can gain a deeper understanding of market dynamics and devise more effective trading strategies.
█ Indicator Inputs
src: This is the source data for the analysis, typically the closing price of the financial instrument.
detrendornot: This input determines the method used for detrending the source data. Detrending is the process of removing the underlying trend from the data to focus on the cyclical components.
The available options are:
hpsmthdt: Detrend using Hodrick-Prescott filter centered moving average.
zlagsmthdt: Detrend using zero-lag moving average centered moving average.
logZlagRegression: Detrend using logarithmic zero-lag linear regression.
hpsmth: Detrend using Hodrick-Prescott filter.
zlagsmth: Detrend using zero-lag moving average.
DT_HPper1 and DT_HPper2: These inputs define the period range for the Hodrick-Prescott filter centered moving average when detrendornot is set to hpsmthdt.
DT_ZLper1 and DT_ZLper2: These inputs define the period range for the zero-lag moving average centered moving average when detrendornot is set to zlagsmthdt.
DT_RegZLsmoothPer: This input defines the period for the zero-lag moving average used in logarithmic zero-lag linear regression when detrendornot is set to logZlagRegression.
HPsmoothPer: This input defines the period for the Hodrick-Prescott filter when detrendornot is set to hpsmth.
ZLMAsmoothPer: This input defines the period for the zero-lag moving average when detrendornot is set to zlagsmth.
MaxPer: This input sets the maximum period for the Goertzel algorithm to search for cycles.
squaredAmp: This boolean input determines whether the amplitude should be squared in the Goertzel algorithm.
useAddition: This boolean input determines whether the Goertzel algorithm should use addition for combining the cycles.
useCosine: This boolean input determines whether the Goertzel algorithm should use cosine waves instead of sine waves.
UseCycleStrength: This boolean input determines whether the Goertzel algorithm should compute the cycle strength, which is a normalized measure of the cycle's amplitude.
WindowSizePast: These inputs define the window size for the composite wave.
FilterBartels: This boolean input determines whether Bartel's test should be applied to filter out non-significant cycles.
BartNoCycles: This input sets the number of cycles to be used in Bartel's test.
BartSmoothPer: This input sets the period for the moving average used in Bartel's test.
BartSigLimit: This input sets the significance limit for Bartel's test, below which cycles are considered insignificant.
SortBartels: This boolean input determines whether the cycles should be sorted by their Bartel's test results.
StartAtCycle: This input determines the starting index for selecting the top N cycles when UseCycleList is set to false. This allows you to skip a certain number of cycles from the top before selecting the desired number of cycles.
UseTopCycles: This input sets the number of top cycles to use for constructing the composite wave when UseCycleList is set to false. The cycles are ranked based on their amplitudes or cycle strengths, depending on the UseCycleStrength input.
SubtractNoise: This boolean input determines whether to subtract the noise (remaining cycles) from the composite wave. If set to true, the composite wave will only include the top N cycles specified by UseTopCycles.
█ Exploring Auxiliary Functions
The following functions demonstrate advanced techniques for analyzing financial markets, including zero-lag moving averages, Bartels probability, detrending, and Hodrick-Prescott filtering. This section examines each function in detail, explaining their purpose, methodology, and applications in finance. We will examine how each function contributes to the overall performance and effectiveness of the indicator and how they work together to create a powerful analytical tool.
Zero-Lag Moving Average:
The zero-lag moving average function is designed to minimize the lag typically associated with moving averages. This is achieved through a two-step weighted linear regression process that emphasizes more recent data points. The function calculates a linearly weighted moving average (LWMA) on the input data and then applies another LWMA on the result. By doing this, the function creates a moving average that closely follows the price action, reducing the lag and improving the responsiveness of the indicator.
The zero-lag moving average function is used in the indicator to provide a responsive, low-lag smoothing of the input data. This function helps reduce the noise and fluctuations in the data, making it easier to identify and analyze underlying trends and patterns. By minimizing the lag associated with traditional moving averages, this function allows the indicator to react more quickly to changes in market conditions, providing timely signals and improving the overall effectiveness of the indicator.
Bartels Probability:
The Bartels probability function calculates the probability of a given cycle being significant in a time series. It uses a mathematical test called the Bartels test to assess the significance of cycles detected in the data. The function calculates coefficients for each detected cycle and computes an average amplitude and an expected amplitude. By comparing these values, the Bartels probability is derived, indicating the likelihood of a cycle's significance. This information can help in identifying and analyzing dominant cycles in financial markets.
The Bartels probability function is incorporated into the indicator to assess the significance of detected cycles in the input data. By calculating the Bartels probability for each cycle, the indicator can prioritize the most significant cycles and focus on the market dynamics that are most relevant to the current trading environment. This function enhances the indicator's ability to identify dominant market cycles, improving its predictive power and aiding in the development of effective trading strategies.
Detrend Logarithmic Zero-Lag Regression:
The detrend logarithmic zero-lag regression function is used for detrending data while minimizing lag. It combines a zero-lag moving average with a linear regression detrending method. The function first calculates the zero-lag moving average of the logarithm of input data and then applies a linear regression to remove the trend. By detrending the data, the function isolates the cyclical components, making it easier to analyze and interpret the underlying market dynamics.
The detrend logarithmic zero-lag regression function is used in the indicator to isolate the cyclical components of the input data. By detrending the data, the function enables the indicator to focus on the cyclical movements in the market, making it easier to analyze and interpret market dynamics. This function is essential for identifying cyclical patterns and understanding the interactions between different market cycles, which can inform trading decisions and enhance overall market understanding.
Bartels Cycle Significance Test:
The Bartels cycle significance test is a function that combines the Bartels probability function and the detrend logarithmic zero-lag regression function to assess the significance of detected cycles. The function calculates the Bartels probability for each cycle and stores the results in an array. By analyzing the probability values, traders and analysts can identify the most significant cycles in the data, which can be used to develop trading strategies and improve market understanding.
The Bartels cycle significance test function is integrated into the indicator to provide a comprehensive analysis of the significance of detected cycles. By combining the Bartels probability function and the detrend logarithmic zero-lag regression function, this test evaluates the significance of each cycle and stores the results in an array. The indicator can then use this information to prioritize the most significant cycles and focus on the most relevant market dynamics. This function enhances the indicator's ability to identify and analyze dominant market cycles, providing valuable insights for trading and market analysis.
Hodrick-Prescott Filter:
The Hodrick-Prescott filter is a popular technique used to separate the trend and cyclical components of a time series. The function applies a smoothing parameter to the input data and calculates a smoothed series using a two-sided filter. This smoothed series represents the trend component, which can be subtracted from the original data to obtain the cyclical component. The Hodrick-Prescott filter is commonly used in economics and finance to analyze economic data and financial market trends.
The Hodrick-Prescott filter is incorporated into the indicator to separate the trend and cyclical components of the input data. By applying the filter to the data, the indicator can isolate the trend component, which can be used to analyze long-term market trends and inform trading decisions. Additionally, the cyclical component can be used to identify shorter-term market dynamics and provide insights into potential trading opportunities. The inclusion of the Hodrick-Prescott filter adds another layer of analysis to the indicator, making it more versatile and comprehensive.
Detrending Options: Detrend Centered Moving Average:
The detrend centered moving average function provides different detrending methods, including the Hodrick-Prescott filter and the zero-lag moving average, based on the selected detrending method. The function calculates two sets of smoothed values using the chosen method and subtracts one set from the other to obtain a detrended series. By offering multiple detrending options, this function allows traders and analysts to select the most appropriate method for their specific needs and preferences.
The detrend centered moving average function is integrated into the indicator to provide users with multiple detrending options, including the Hodrick-Prescott filter and the zero-lag moving average. By offering multiple detrending methods, the indicator allows users to customize the analysis to their specific needs and preferences, enhancing the indicator's overall utility and adaptability. This function ensures that the indicator can cater to a wide range of trading styles and objectives, making it a valuable tool for a diverse group of market participants.
The auxiliary functions functions discussed in this section demonstrate the power and versatility of mathematical techniques in analyzing financial markets. By understanding and implementing these functions, traders and analysts can gain valuable insights into market dynamics, improve their trading strategies, and make more informed decisions. The combination of zero-lag moving averages, Bartels probability, detrending methods, and the Hodrick-Prescott filter provides a comprehensive toolkit for analyzing and interpreting financial data. The integration of advanced functions in a financial indicator creates a powerful and versatile analytical tool that can provide valuable insights into financial markets. By combining the zero-lag moving average,
█ In-Depth Analysis of the Goertzel Cycle Composite Wave Code
The Goertzel Cycle Composite Wave code is an implementation of the Goertzel Algorithm, an efficient technique to perform spectral analysis on a signal. The code is designed to detect and analyze dominant cycles within a given financial market data set. This section will provide an extremely detailed explanation of the code, its structure, functions, and intended purpose.
Function signature and input parameters:
The Goertzel Cycle Composite Wave function accepts numerous input parameters for customization, including source data (src), the current bar (forBar), sample size (samplesize), period (per), squared amplitude flag (squaredAmp), addition flag (useAddition), cosine flag (useCosine), cycle strength flag (UseCycleStrength), past sizes (WindowSizePast), Bartels filter flag (FilterBartels), Bartels-related parameters (BartNoCycles, BartSmoothPer, BartSigLimit), sorting flag (SortBartels), and output buffers (goeWorkPast, cyclebuffer, amplitudebuffer, phasebuffer, cycleBartelsBuffer).
Initializing variables and arrays:
The code initializes several float arrays (goeWork1, goeWork2, goeWork3, goeWork4) with the same length as twice the period (2 * per). These arrays store intermediate results during the execution of the algorithm.
Preprocessing input data:
The input data (src) undergoes preprocessing to remove linear trends. This step enhances the algorithm's ability to focus on cyclical components in the data. The linear trend is calculated by finding the slope between the first and last values of the input data within the sample.
Iterative calculation of Goertzel coefficients:
The core of the Goertzel Cycle Composite Wave algorithm lies in the iterative calculation of Goertzel coefficients for each frequency bin. These coefficients represent the spectral content of the input data at different frequencies. The code iterates through the range of frequencies, calculating the Goertzel coefficients using a nested loop structure.
Cycle strength computation:
The code calculates the cycle strength based on the Goertzel coefficients. This is an optional step, controlled by the UseCycleStrength flag. The cycle strength provides information on the relative influence of each cycle on the data per bar, considering both amplitude and cycle length. The algorithm computes the cycle strength either by squaring the amplitude (controlled by squaredAmp flag) or using the actual amplitude values.
Phase calculation:
The Goertzel Cycle Composite Wave code computes the phase of each cycle, which represents the position of the cycle within the input data. The phase is calculated using the arctangent function (math.atan) based on the ratio of the imaginary and real components of the Goertzel coefficients.
Peak detection and cycle extraction:
The algorithm performs peak detection on the computed amplitudes or cycle strengths to identify dominant cycles. It stores the detected cycles in the cyclebuffer array, along with their corresponding amplitudes and phases in the amplitudebuffer and phasebuffer arrays, respectively.
Sorting cycles by amplitude or cycle strength:
The code sorts the detected cycles based on their amplitude or cycle strength in descending order. This allows the algorithm to prioritize cycles with the most significant impact on the input data.
Bartels cycle significance test:
If the FilterBartels flag is set, the code performs a Bartels cycle significance test on the detected cycles. This test determines the statistical significance of each cycle and filters out the insignificant cycles. The significant cycles are stored in the cycleBartelsBuffer array. If the SortBartels flag is set, the code sorts the significant cycles based on their Bartels significance values.
Waveform calculation:
The Goertzel Cycle Composite Wave code calculates the waveform of the significant cycles for specified time windows. The windows are defined by the WindowSizePast parameters, respectively. The algorithm uses either cosine or sine functions (controlled by the useCosine flag) to calculate the waveforms for each cycle. The useAddition flag determines whether the waveforms should be added or subtracted.
Storing waveforms in a matrix:
The calculated waveforms for the cycle is stored in the matrix - goeWorkPast. This matrix holds the waveforms for the specified time windows. Each row in the matrix represents a time window position, and each column corresponds to a cycle.
Returning the number of cycles:
The Goertzel Cycle Composite Wave function returns the total number of detected cycles (number_of_cycles) after processing the input data. This information can be used to further analyze the results or to visualize the detected cycles.
The Goertzel Cycle Composite Wave code is a comprehensive implementation of the Goertzel Algorithm, specifically designed for detecting and analyzing dominant cycles within financial market data. The code offers a high level of customization, allowing users to fine-tune the algorithm based on their specific needs. The Goertzel Cycle Composite Wave's combination of preprocessing, iterative calculations, cycle extraction, sorting, significance testing, and waveform calculation makes it a powerful tool for understanding cyclical components in financial data.
█ Generating and Visualizing Composite Waveform
The indicator calculates and visualizes the composite waveform for specified time windows based on the detected cycles. Here's a detailed explanation of this process:
Updating WindowSizePast:
The WindowSizePast is updated to ensure they are at least twice the MaxPer (maximum period).
Initializing matrices and arrays:
The matrix goeWorkPast is initialized to store the Goertzel results for specified time windows. Multiple arrays are also initialized to store cycle, amplitude, phase, and Bartels information.
Preparing the source data (srcVal) array:
The source data is copied into an array, srcVal, and detrended using one of the selected methods (hpsmthdt, zlagsmthdt, logZlagRegression, hpsmth, or zlagsmth).
Goertzel function call:
The Goertzel function is called to analyze the detrended source data and extract cycle information. The output, number_of_cycles, contains the number of detected cycles.
Initializing arrays for waveforms:
The goertzel array is initialized to store the endpoint Goertzel.
Calculating composite waveform (goertzel array):
The composite waveform is calculated by summing the selected cycles (either from the user-defined cycle list or the top cycles) and optionally subtracting the noise component.
Drawing composite waveform (pvlines):
The composite waveform is drawn on the chart using solid lines. The color of the lines is determined by the direction of the waveform (green for upward, red for downward).
To summarize, this indicator generates a composite waveform based on the detected cycles in the financial data. It calculates the composite waveforms and visualizes them on the chart using colored lines.
█ Enhancing the Goertzel Algorithm-Based Script for Financial Modeling and Trading
The Goertzel algorithm-based script for detecting dominant cycles in financial data is a powerful tool for financial modeling and trading. It provides valuable insights into the past behavior of these cycles. However, as with any algorithm, there is always room for improvement. This section discusses potential enhancements to the existing script to make it even more robust and versatile for financial modeling, general trading, advanced trading, and high-frequency finance trading.
Enhancements for Financial Modeling
Data preprocessing: One way to improve the script's performance for financial modeling is to introduce more advanced data preprocessing techniques. This could include removing outliers, handling missing data, and normalizing the data to ensure consistent and accurate results.
Additional detrending and smoothing methods: Incorporating more sophisticated detrending and smoothing techniques, such as wavelet transform or empirical mode decomposition, can help improve the script's ability to accurately identify cycles and trends in the data.
Machine learning integration: Integrating machine learning techniques, such as artificial neural networks or support vector machines, can help enhance the script's predictive capabilities, leading to more accurate financial models.
Enhancements for General and Advanced Trading
Customizable indicator integration: Allowing users to integrate their own technical indicators can help improve the script's effectiveness for both general and advanced trading. By enabling the combination of the dominant cycle information with other technical analysis tools, traders can develop more comprehensive trading strategies.
Risk management and position sizing: Incorporating risk management and position sizing functionality into the script can help traders better manage their trades and control potential losses. This can be achieved by calculating the optimal position size based on the user's risk tolerance and account size.
Multi-timeframe analysis: Enhancing the script to perform multi-timeframe analysis can provide traders with a more holistic view of market trends and cycles. By identifying dominant cycles on different timeframes, traders can gain insights into the potential confluence of cycles and make better-informed trading decisions.
Enhancements for High-Frequency Finance Trading
Algorithm optimization: To ensure the script's suitability for high-frequency finance trading, optimizing the algorithm for faster execution is crucial. This can be achieved by employing efficient data structures and refining the calculation methods to minimize computational complexity.
Real-time data streaming: Integrating real-time data streaming capabilities into the script can help high-frequency traders react to market changes more quickly. By continuously updating the cycle information based on real-time market data, traders can adapt their strategies accordingly and capitalize on short-term market fluctuations.
Order execution and trade management: To fully leverage the script's capabilities for high-frequency trading, implementing functionality for automated order execution and trade management is essential. This can include features such as stop-loss and take-profit orders, trailing stops, and automated trade exit strategies.
While the existing Goertzel algorithm-based script is a valuable tool for detecting dominant cycles in financial data, there are several potential enhancements that can make it even more powerful for financial modeling, general trading, advanced trading, and high-frequency finance trading. By incorporating these improvements, the script can become a more versatile and effective tool for traders and financial analysts alike.
█ Understanding the Limitations of the Goertzel Algorithm
While the Goertzel algorithm-based script for detecting dominant cycles in financial data provides valuable insights, it is important to be aware of its limitations and drawbacks. Some of the key drawbacks of this indicator are:
Lagging nature:
As with many other technical indicators, the Goertzel algorithm-based script can suffer from lagging effects, meaning that it may not immediately react to real-time market changes. This lag can lead to late entries and exits, potentially resulting in reduced profitability or increased losses.
Parameter sensitivity:
The performance of the script can be sensitive to the chosen parameters, such as the detrending methods, smoothing techniques, and cycle detection settings. Improper parameter selection may lead to inaccurate cycle detection or increased false signals, which can negatively impact trading performance.
Complexity:
The Goertzel algorithm itself is relatively complex, making it difficult for novice traders or those unfamiliar with the concept of cycle analysis to fully understand and effectively utilize the script. This complexity can also make it challenging to optimize the script for specific trading styles or market conditions.
Overfitting risk:
As with any data-driven approach, there is a risk of overfitting when using the Goertzel algorithm-based script. Overfitting occurs when a model becomes too specific to the historical data it was trained on, leading to poor performance on new, unseen data. This can result in misleading signals and reduced trading performance.
Limited applicability:
The Goertzel algorithm-based script may not be suitable for all markets, trading styles, or timeframes. Its effectiveness in detecting cycles may be limited in certain market conditions, such as during periods of extreme volatility or low liquidity.
While the Goertzel algorithm-based script offers valuable insights into dominant cycles in financial data, it is essential to consider its drawbacks and limitations when incorporating it into a trading strategy. Traders should always use the script in conjunction with other technical and fundamental analysis tools, as well as proper risk management, to make well-informed trading decisions.
█ Interpreting Results
The Goertzel Cycle Composite Wave indicator can be interpreted by analyzing the plotted lines. The indicator plots two lines: composite waves. The composite wave represents the composite wave of the price data.
The composite wave line displays a solid line, with green indicating a bullish trend and red indicating a bearish trend.
Interpreting the Goertzel Cycle Composite Wave indicator involves identifying the trend of the composite wave lines and matching them with the corresponding bullish or bearish color.
█ Conclusion
The Goertzel Cycle Composite Wave indicator is a powerful tool for identifying and analyzing cyclical patterns in financial markets. Its ability to detect multiple cycles of varying frequencies and strengths make it a valuable addition to any trader's technical analysis toolkit. However, it is important to keep in mind that the Goertzel Cycle Composite Wave indicator should be used in conjunction with other technical analysis tools and fundamental analysis to achieve the best results. With continued refinement and development, the Goertzel Cycle Composite Wave indicator has the potential to become a highly effective tool for financial modeling, general trading, advanced trading, and high-frequency finance trading. Its accuracy and versatility make it a promising candidate for further research and development.
█ Footnotes
What is the Bartels Test for Cycle Significance?
The Bartels Cycle Significance Test is a statistical method that determines whether the peaks and troughs of a time series are statistically significant. The test is named after its inventor, George Bartels, who developed it in the mid-20th century.
The Bartels test is designed to analyze the cyclical components of a time series, which can help traders and analysts identify trends and cycles in financial markets. The test calculates a Bartels statistic, which measures the degree of non-randomness or autocorrelation in the time series.
The Bartels statistic is calculated by first splitting the time series into two halves and calculating the range of the peaks and troughs in each half. The test then compares these ranges using a t-test, which measures the significance of the difference between the two ranges.
If the Bartels statistic is greater than a critical value, it indicates that the peaks and troughs in the time series are non-random and that there is a significant cyclical component to the data. Conversely, if the Bartels statistic is less than the critical value, it suggests that the peaks and troughs are random and that there is no significant cyclical component.
The Bartels Cycle Significance Test is particularly useful in financial analysis because it can help traders and analysts identify significant cycles in asset prices, which can in turn inform investment decisions. However, it is important to note that the test is not perfect and can produce false signals in certain situations, particularly in noisy or volatile markets. Therefore, it is always recommended to use the test in conjunction with other technical and fundamental indicators to confirm trends and cycles.
Deep-dive into the Hodrick-Prescott Fitler
The Hodrick-Prescott (HP) filter is a statistical tool used in economics and finance to separate a time series into two components: a trend component and a cyclical component. It is a powerful tool for identifying long-term trends in economic and financial data and is widely used by economists, central banks, and financial institutions around the world.
The HP filter was first introduced in the 1990s by economists Robert Hodrick and Edward Prescott. It is a simple, two-parameter filter that separates a time series into a trend component and a cyclical component. The trend component represents the long-term behavior of the data, while the cyclical component captures the shorter-term fluctuations around the trend.
The HP filter works by minimizing the following objective function:
Minimize: (Sum of Squared Deviations) + λ (Sum of Squared Second Differences)
Where:
1. The first term represents the deviation of the data from the trend.
2. The second term represents the smoothness of the trend.
3. λ is a smoothing parameter that determines the degree of smoothness of the trend.
The smoothing parameter λ is typically set to a value between 100 and 1600, depending on the frequency of the data. Higher values of λ lead to a smoother trend, while lower values lead to a more volatile trend.
The HP filter has several advantages over other smoothing techniques. It is a non-parametric method, meaning that it does not make any assumptions about the underlying distribution of the data. It also allows for easy comparison of trends across different time series and can be used with data of any frequency.
However, the HP filter also has some limitations. It assumes that the trend is a smooth function, which may not be the case in some situations. It can also be sensitive to changes in the smoothing parameter λ, which may result in different trends for the same data. Additionally, the filter may produce unrealistic trends for very short time series.
Despite these limitations, the HP filter remains a valuable tool for analyzing economic and financial data. It is widely used by central banks and financial institutions to monitor long-term trends in the economy, and it can be used to identify turning points in the business cycle. The filter can also be used to analyze asset prices, exchange rates, and other financial variables.
The Hodrick-Prescott filter is a powerful tool for analyzing economic and financial data. It separates a time series into a trend component and a cyclical component, allowing for easy identification of long-term trends and turning points in the business cycle. While it has some limitations, it remains a valuable tool for economists, central banks, and financial institutions around the world.
loxxfftLibrary "loxxfft"
This code is a library for performing Fast Fourier Transform (FFT) operations. FFT is an algorithm that can quickly compute the discrete Fourier transform (DFT) of a sequence. The library includes functions for performing FFTs on both real and complex data. It also includes functions for fast correlation and convolution, which are operations that can be performed efficiently using FFTs. Additionally, the library includes functions for fast sine and cosine transforms.
Reference:
www.alglib.net
fastfouriertransform(a, nn, inversefft)
Returns Fast Fourier Transform
Parameters:
a (float ) : float , An array of real and imaginary parts of the function values. The real part is stored at even indices, and the imaginary part is stored at odd indices.
nn (int) : int, The number of function values. It must be a power of two, but the algorithm does not validate this.
inversefft (bool) : bool, A boolean value that indicates the direction of the transformation. If True, it performs the inverse FFT; if False, it performs the direct FFT.
Returns: float , Modifies the input array a in-place, which means that the transformed data (the FFT result for direct transformation or the inverse FFT result for inverse transformation) will be stored in the same array a after the function execution. The transformed data will have real and imaginary parts interleaved, with the real parts at even indices and the imaginary parts at odd indices.
realfastfouriertransform(a, tnn, inversefft)
Returns Real Fast Fourier Transform
Parameters:
a (float ) : float , A float array containing the real-valued function samples.
tnn (int) : int, The number of function values (must be a power of 2, but the algorithm does not validate this condition).
inversefft (bool) : bool, A boolean flag that indicates the direction of the transformation (True for inverse, False for direct).
Returns: float , Modifies the input array a in-place, meaning that the transformed data (the FFT result for direct transformation or the inverse FFT result for inverse transformation) will be stored in the same array a after the function execution.
fastsinetransform(a, tnn, inversefst)
Returns Fast Discrete Sine Conversion
Parameters:
a (float ) : float , An array of real numbers representing the function values.
tnn (int) : int, Number of function values (must be a power of two, but the code doesn't validate this).
inversefst (bool) : bool, A boolean flag indicating the direction of the transformation. If True, it performs the inverse FST, and if False, it performs the direct FST.
Returns: float , The output is the transformed array 'a', which will contain the result of the transformation.
fastcosinetransform(a, tnn, inversefct)
Returns Fast Discrete Cosine Transform
Parameters:
a (float ) : float , This is a floating-point array representing the sequence of values (time-domain) that you want to transform. The function will perform the Fast Cosine Transform (FCT) or the inverse FCT on this input array, depending on the value of the inversefct parameter. The transformed result will also be stored in this same array, which means the function modifies the input array in-place.
tnn (int) : int, This is an integer value representing the number of data points in the input array a. It is used to determine the size of the input array and control the loops in the algorithm. Note that the size of the input array should be a power of 2 for the Fast Cosine Transform algorithm to work correctly.
inversefct (bool) : bool, This is a boolean value that controls whether the function performs the regular Fast Cosine Transform or the inverse FCT. If inversefct is set to true, the function will perform the inverse FCT, and if set to false, the regular FCT will be performed. The inverse FCT can be used to transform data back into its original form (time-domain) after the regular FCT has been applied.
Returns: float , The resulting transformed array is stored in the input array a. This means that the function modifies the input array in-place and does not return a new array.
fastconvolution(signal, signallen, response, negativelen, positivelen)
Convolution using FFT
Parameters:
signal (float ) : float , This is an array of real numbers representing the input signal that will be convolved with the response function. The elements are numbered from 0 to SignalLen-1.
signallen (int) : int, This is an integer representing the length of the input signal array. It specifies the number of elements in the signal array.
response (float ) : float , This is an array of real numbers representing the response function used for convolution. The response function consists of two parts: one corresponding to positive argument values and the other to negative argument values. Array elements with numbers from 0 to NegativeLen match the response values at points from -NegativeLen to 0, respectively. Array elements with numbers from NegativeLen+1 to NegativeLen+PositiveLen correspond to the response values in points from 1 to PositiveLen, respectively.
negativelen (int) : int, This is an integer representing the "negative length" of the response function. It indicates the number of elements in the response function array that correspond to negative argument values. Outside the range , the response function is considered zero.
positivelen (int) : int, This is an integer representing the "positive length" of the response function. It indicates the number of elements in the response function array that correspond to positive argument values. Similar to negativelen, outside the range , the response function is considered zero.
Returns: float , The resulting convolved values are stored back in the input signal array.
fastcorrelation(signal, signallen, pattern, patternlen)
Returns Correlation using FFT
Parameters:
signal (float ) : float ,This is an array of real numbers representing the signal to be correlated with the pattern. The elements are numbered from 0 to SignalLen-1.
signallen (int) : int, This is an integer representing the length of the input signal array.
pattern (float ) : float , This is an array of real numbers representing the pattern to be correlated with the signal. The elements are numbered from 0 to PatternLen-1.
patternlen (int) : int, This is an integer representing the length of the pattern array.
Returns: float , The signal array containing the correlation values at points from 0 to SignalLen-1.
tworealffts(a1, a2, a, b, tn)
Returns Fast Fourier Transform of Two Real Functions
Parameters:
a1 (float ) : float , An array of real numbers, representing the values of the first function.
a2 (float ) : float , An array of real numbers, representing the values of the second function.
a (float ) : float , An output array to store the Fourier transform of the first function.
b (float ) : float , An output array to store the Fourier transform of the second function.
tn (int) : float , An integer representing the number of function values. It must be a power of two, but the algorithm doesn't validate this condition.
Returns: float , The a and b arrays will contain the Fourier transform of the first and second functions, respectively. Note that the function overwrites the input arrays a and b.
█ Detailed explaination of each function
Fast Fourier Transform
The fastfouriertransform() function takes three input parameters:
1. a: An array of real and imaginary parts of the function values. The real part is stored at even indices, and the imaginary part is stored at odd indices.
2. nn: The number of function values. It must be a power of two, but the algorithm does not validate this.
3. inversefft: A boolean value that indicates the direction of the transformation. If True, it performs the inverse FFT; if False, it performs the direct FFT.
The function performs the FFT using the Cooley-Tukey algorithm, which is an efficient algorithm for computing the discrete Fourier transform (DFT) and its inverse. The Cooley-Tukey algorithm recursively breaks down the DFT of a sequence into smaller DFTs of subsequences, leading to a significant reduction in computational complexity. The algorithm's time complexity is O(n log n), where n is the number of samples.
The fastfouriertransform() function first initializes variables and determines the direction of the transformation based on the inversefft parameter. If inversefft is True, the isign variable is set to -1; otherwise, it is set to 1.
Next, the function performs the bit-reversal operation. This is a necessary step before calculating the FFT, as it rearranges the input data in a specific order required by the Cooley-Tukey algorithm. The bit-reversal is performed using a loop that iterates through the nn samples, swapping the data elements according to their bit-reversed index.
After the bit-reversal operation, the function iteratively computes the FFT using the Cooley-Tukey algorithm. It performs calculations in a loop that goes through different stages, doubling the size of the sub-FFT at each stage. Within each stage, the Cooley-Tukey algorithm calculates the butterfly operations, which are mathematical operations that combine the results of smaller DFTs into the final DFT. The butterfly operations involve complex number multiplication and addition, updating the input array a with the computed values.
The loop also calculates the twiddle factors, which are complex exponential factors used in the butterfly operations. The twiddle factors are calculated using trigonometric functions, such as sine and cosine, based on the angle theta. The variables wpr, wpi, wr, and wi are used to store intermediate values of the twiddle factors, which are updated in each iteration of the loop.
Finally, if the inversefft parameter is True, the function divides the result by the number of samples nn to obtain the correct inverse FFT result. This normalization step is performed using a loop that iterates through the array a and divides each element by nn.
In summary, the fastfouriertransform() function is an implementation of the Cooley-Tukey FFT algorithm, which is an efficient algorithm for computing the DFT and its inverse. This FFT library can be used for a variety of applications, such as signal processing, image processing, audio processing, and more.
Feal Fast Fourier Transform
The realfastfouriertransform() function performs a fast Fourier transform (FFT) specifically for real-valued functions. The FFT is an efficient algorithm used to compute the discrete Fourier transform (DFT) and its inverse, which are fundamental tools in signal processing, image processing, and other related fields.
This function takes three input parameters:
1. a - A float array containing the real-valued function samples.
2. tnn - The number of function values (must be a power of 2, but the algorithm does not validate this condition).
3. inversefft - A boolean flag that indicates the direction of the transformation (True for inverse, False for direct).
The function modifies the input array a in-place, meaning that the transformed data (the FFT result for direct transformation or the inverse FFT result for inverse transformation) will be stored in the same array a after the function execution.
The algorithm uses a combination of complex-to-complex FFT and additional transformations specific to real-valued data to optimize the computation. It takes into account the symmetry properties of the real-valued input data to reduce the computational complexity.
Here's a detailed walkthrough of the algorithm:
1. Depending on the inversefft flag, the initial values for ttheta, c1, and c2 are determined. These values are used for the initial data preprocessing and post-processing steps specific to the real-valued FFT.
2. The preprocessing step computes the initial real and imaginary parts of the data using a combination of sine and cosine terms with the input data. This step effectively converts the real-valued input data into complex-valued data suitable for the complex-to-complex FFT.
3. The complex-to-complex FFT is then performed on the preprocessed complex data. This involves bit-reversal reordering, followed by the Cooley-Tukey radix-2 decimation-in-time algorithm. This part of the code is similar to the fastfouriertransform() function you provided earlier.
4. After the complex-to-complex FFT, a post-processing step is performed to obtain the final real-valued output data. This involves updating the real and imaginary parts of the transformed data using sine and cosine terms, as well as the values c1 and c2.
5. Finally, if the inversefft flag is True, the output data is divided by the number of samples (nn) to obtain the inverse DFT.
The function does not return a value explicitly. Instead, the transformed data is stored in the input array a. After the function execution, you can access the transformed data in the a array, which will have the real part at even indices and the imaginary part at odd indices.
Fast Sine Transform
This code defines a function called fastsinetransform that performs a Fast Discrete Sine Transform (FST) on an array of real numbers. The function takes three input parameters:
1. a (float array): An array of real numbers representing the function values.
2. tnn (int): Number of function values (must be a power of two, but the code doesn't validate this).
3. inversefst (bool): A boolean flag indicating the direction of the transformation. If True, it performs the inverse FST, and if False, it performs the direct FST.
The output is the transformed array 'a', which will contain the result of the transformation.
The code starts by initializing several variables, including trigonometric constants for the sine transform. It then sets the first value of the array 'a' to 0 and calculates the initial values of 'y1' and 'y2', which are used to update the input array 'a' in the following loop.
The first loop (with index 'jx') iterates from 2 to (tm + 1), where 'tm' is half of the number of input samples 'tnn'. This loop is responsible for calculating the initial sine transform of the input data.
The second loop (with index 'ii') is a bit-reversal loop. It reorders the elements in the array 'a' based on the bit-reversed indices of the original order.
The third loop (with index 'ii') iterates while 'n' is greater than 'mmax', which starts at 2 and doubles each iteration. This loop performs the actual Fast Discrete Sine Transform. It calculates the sine transform using the Danielson-Lanczos lemma, which is a divide-and-conquer strategy for calculating Discrete Fourier Transforms (DFTs) efficiently.
The fourth loop (with index 'ix') is responsible for the final phase adjustments needed for the sine transform, updating the array 'a' accordingly.
The fifth loop (with index 'jj') updates the array 'a' one more time by dividing each element by 2 and calculating the sum of the even-indexed elements.
Finally, if the 'inversefst' flag is True, the code scales the transformed data by a factor of 2/tnn to get the inverse Fast Sine Transform.
In summary, the code performs a Fast Discrete Sine Transform on an input array of real numbers, either in the direct or inverse direction, and returns the transformed array. The algorithm is based on the Danielson-Lanczos lemma and uses a divide-and-conquer strategy for efficient computation.
Fast Cosine Transform
This code defines a function called fastcosinetransform that takes three parameters: a floating-point array a, an integer tnn, and a boolean inversefct. The function calculates the Fast Cosine Transform (FCT) or the inverse FCT of the input array, depending on the value of the inversefct parameter.
The Fast Cosine Transform is an algorithm that converts a sequence of values (time-domain) into a frequency domain representation. It is closely related to the Fast Fourier Transform (FFT) and can be used in various applications, such as signal processing and image compression.
Here's a detailed explanation of the code:
1. The function starts by initializing a number of variables, including counters, intermediate values, and constants.
2. The initial steps of the algorithm are performed. This includes calculating some trigonometric values and updating the input array a with the help of intermediate variables.
3. The code then enters a loop (from jx = 2 to tnn / 2). Within this loop, the algorithm computes and updates the elements of the input array a.
4. After the loop, the function prepares some variables for the next stage of the algorithm.
5. The next part of the algorithm is a series of nested loops that perform the bit-reversal permutation and apply the FCT to the input array a.
6. The code then calculates some additional trigonometric values, which are used in the next loop.
7. The following loop (from ix = 2 to tnn / 4 + 1) computes and updates the elements of the input array a using the previously calculated trigonometric values.
8. The input array a is further updated with the final calculations.
9. In the last loop (from j = 4 to tnn), the algorithm computes and updates the sum of elements in the input array a.
10. Finally, if the inversefct parameter is set to true, the function scales the input array a to obtain the inverse FCT.
The resulting transformed array is stored in the input array a. This means that the function modifies the input array in-place and does not return a new array.
Fast Convolution
This code defines a function called fastconvolution that performs the convolution of a given signal with a response function using the Fast Fourier Transform (FFT) technique. Convolution is a mathematical operation used in signal processing to combine two signals, producing a third signal representing how the shape of one signal is modified by the other.
The fastconvolution function takes the following input parameters:
1. float signal: This is an array of real numbers representing the input signal that will be convolved with the response function. The elements are numbered from 0 to SignalLen-1.
2. int signallen: This is an integer representing the length of the input signal array. It specifies the number of elements in the signal array.
3. float response: This is an array of real numbers representing the response function used for convolution. The response function consists of two parts: one corresponding to positive argument values and the other to negative argument values. Array elements with numbers from 0 to NegativeLen match the response values at points from -NegativeLen to 0, respectively. Array elements with numbers from NegativeLen+1 to NegativeLen+PositiveLen correspond to the response values in points from 1 to PositiveLen, respectively.
4. int negativelen: This is an integer representing the "negative length" of the response function. It indicates the number of elements in the response function array that correspond to negative argument values. Outside the range , the response function is considered zero.
5. int positivelen: This is an integer representing the "positive length" of the response function. It indicates the number of elements in the response function array that correspond to positive argument values. Similar to negativelen, outside the range , the response function is considered zero.
The function works by:
1. Calculating the length nl of the arrays used for FFT, ensuring it's a power of 2 and large enough to hold the signal and response.
2. Creating two new arrays, a1 and a2, of length nl and initializing them with the input signal and response function, respectively.
3. Applying the forward FFT (realfastfouriertransform) to both arrays, a1 and a2.
4. Performing element-wise multiplication of the FFT results in the frequency domain.
5. Applying the inverse FFT (realfastfouriertransform) to the multiplied results in a1.
6. Updating the original signal array with the convolution result, which is stored in the a1 array.
The result of the convolution is stored in the input signal array at the function exit.
Fast Correlation
This code defines a function called fastcorrelation that computes the correlation between a signal and a pattern using the Fast Fourier Transform (FFT) method. The function takes four input arguments and modifies the input signal array to store the correlation values.
Input arguments:
1. float signal: This is an array of real numbers representing the signal to be correlated with the pattern. The elements are numbered from 0 to SignalLen-1.
2. int signallen: This is an integer representing the length of the input signal array.
3. float pattern: This is an array of real numbers representing the pattern to be correlated with the signal. The elements are numbered from 0 to PatternLen-1.
4. int patternlen: This is an integer representing the length of the pattern array.
The function performs the following steps:
1. Calculate the required size nl for the FFT by finding the smallest power of 2 that is greater than or equal to the sum of the lengths of the signal and the pattern.
2. Create two new arrays a1 and a2 with the length nl and initialize them to 0.
3. Copy the signal array into a1 and pad it with zeros up to the length nl.
4. Copy the pattern array into a2 and pad it with zeros up to the length nl.
5. Compute the FFT of both a1 and a2.
6. Perform element-wise multiplication of the frequency-domain representation of a1 and the complex conjugate of the frequency-domain representation of a2.
7. Compute the inverse FFT of the result obtained in step 6.
8. Store the resulting correlation values in the original signal array.
At the end of the function, the signal array contains the correlation values at points from 0 to SignalLen-1.
Fast Fourier Transform of Two Real Functions
This code defines a function called tworealffts that computes the Fast Fourier Transform (FFT) of two real-valued functions (a1 and a2) using a Cooley-Tukey-based radix-2 Decimation in Time (DIT) algorithm. The FFT is a widely used algorithm for computing the discrete Fourier transform (DFT) and its inverse.
Input parameters:
1. float a1: an array of real numbers, representing the values of the first function.
2. float a2: an array of real numbers, representing the values of the second function.
3. float a: an output array to store the Fourier transform of the first function.
4. float b: an output array to store the Fourier transform of the second function.
5. int tn: an integer representing the number of function values. It must be a power of two, but the algorithm doesn't validate this condition.
The function performs the following steps:
1. Combine the two input arrays, a1 and a2, into a single array a by interleaving their elements.
2. Perform a 1D FFT on the combined array a using the radix-2 DIT algorithm.
3. Separate the FFT results of the two input functions from the combined array a and store them in output arrays a and b.
Here is a detailed breakdown of the radix-2 DIT algorithm used in this code:
1. Bit-reverse the order of the elements in the combined array a.
2. Initialize the loop variables mmax, istep, and theta.
3. Enter the main loop that iterates through different stages of the FFT.
a. Compute the sine and cosine values for the current stage using the theta variable.
b. Initialize the loop variables wr and wi for the current stage.
c. Enter the inner loop that iterates through the butterfly operations within each stage.
i. Perform the butterfly operation on the elements of array a.
ii. Update the loop variables wr and wi for the next butterfly operation.
d. Update the loop variables mmax, istep, and theta for the next stage.
4. Separate the FFT results of the two input functions from the combined array a and store them in output arrays a and b.
At the end of the function, the a and b arrays will contain the Fourier transform of the first and second functions, respectively. Note that the function overwrites the input arrays a and b.
█ Example scripts using functions contained in loxxfft
Real-Fast Fourier Transform of Price w/ Linear Regression
Real-Fast Fourier Transform of Price Oscillator
Normalized, Variety, Fast Fourier Transform Explorer
Variety RSI of Fast Discrete Cosine Transform
STD-Stepped Fast Cosine Transform Moving Average

Momentum Ratio Oscillator [Loxx]What is Momentum Ratio Oscillator?
The theory behind this indicator involves utilizing a sequence of exponential moving average (EMA) calculations to achieve a smoother value of momentum ratio, which compares the current value to the previous one. Although this results in an outcome similar to that of some pre-existing indicators (such as volume zone or price zone oscillators), the use of EMA for smoothing is what sets it apart. EMA produces a smooth step-like output when values undergo sudden changes, whereas the mathematics used for those other indicators are completely distinct. This is a concept by the beloved Mladen of FX forums.
To utilize this version of the indicator, you have the option of using either levels, middle, or signal crosses for signals. The indicator is range bound from 0 to 1.
What is an EMA?
EMA stands for Exponential Moving Average, which is a type of moving average that is commonly used in technical analysis to smooth out price data and identify trends.
In a simple moving average (SMA), each data point is given equal weight when calculating the average. For example, if you are calculating the 10-day SMA, you would add up the prices for the past 10 days and divide by 10 to get the average. In contrast, in an EMA, more weight is given to recent prices, while older prices are given less weight.
The formula for calculating an EMA involves using a smoothing factor that is multiplied by the difference between the current price and the previous EMA value, and then adding this to the previous EMA value. The smoothing factor is typically calculated based on the length of the EMA being used. For example, a 10-day EMA might use a smoothing factor of 2/(10+1) or 0.1818.
The result of using an EMA is that the line produced is more responsive to recent price changes than a simple moving average. This makes it useful for identifying short-term trends and potential trend reversals. However, it can also be more volatile and prone to whipsaws, so it is often used in combination with other indicators to confirm signals.
Overall, the EMA is a widely used and versatile tool in technical analysis, and its effectiveness depends on the specific context in which it is applied.
What is Momentum?
In technical analysis, momentum refers to the rate of change of an asset's price over a certain period of time. It is often used to identify trends and potential trend reversals in financial markets.
Momentum is calculated by subtracting the closing price of an asset X days ago from its current closing price, where X is the number of days being used for the calculation. The result is the momentum value for that particular day. A positive momentum value suggests that prices are increasing, while a negative value indicates that prices are decreasing.
Traders use momentum in a variety of ways. One common approach is to look for divergences between the momentum indicator and the price of the asset being traded. For example, if an asset's price is trending upwards but its momentum is trending downwards, this could be a sign of a potential trend reversal.
Another popular strategy is to use momentum to identify overbought and oversold conditions in the market. When an asset's price has been rising rapidly and its momentum is high, it may be considered overbought and due for a correction. Conversely, when an asset's price has been falling rapidly and its momentum is low, it may be considered oversold and due for a bounce back up.
Momentum is also often used in conjunction with other technical indicators, such as moving averages or Bollinger Bands, to confirm signals and improve the accuracy of trading decisions.
Overall, momentum is a useful tool for traders and investors to analyze price movements and identify potential trading opportunities. However, like all technical indicators, it should be used in conjunction with other forms of analysis and with consideration of the broader market context.
Extras
Alerts
Signals
Loxx's Expanded Source Types, see here for details
Super 6x: RSI, MACD, Stoch, Loxxer, CCI, & Velocity [Loxx]Super 6x: RSI , MACD , Stoch , Loxxer, CCI , & Velocity is a combination of 6 indicators into one histogram. This includes the option to allow repainting.
What is MACD?
Moving average convergence divergence ( MACD ) is a trend-following momentum indicator that shows the relationship between two moving averages of a security’s price. The MACD is calculated by subtracting the 26-period exponential moving average ( EMA ) from the 12-period EMA .
What is CCI?
The Commodity Channel Index ( CCI ) measures the current price level relative to an average price level over a given period of time. CCI is relatively high when prices are far above their average. CCI is relatively low when prices are far below their average. Using this method, CCI can be used to identify overbought and oversold levels.
What is RSI?
The relative strength index is a technical indicator used in the analysis of financial markets. It is intended to chart the current and historical strength or weakness of a stock or market based on the closing prices of a recent trading period. The indicator should not be confused with relative strength .
What is Stochastic?
The stochastic oscillator, also known as stochastic indicator, is a popular trading indicator that is useful for predicting trend reversals. It also focuses on price momentum and can be used to identify overbought and oversold levels in shares, indices, currencies and many other investment assets.
What is Loxxer?
The Loxxer indicator is a technical analysis tool that compares the most recent maximum and minimum prices to the previous period's equivalent price to measure the demand of the underlying asset.
What is Velocity?
In simple words, velocity is the speed at which something moves in a particular direction. For example as the speed of a car travelling north on a highway, or the speed a rocket travels after launching.
How to use
Long signal: All 4 indicators turn green
Short signal: All 4 indicators turn red
Included
Bar coloring
Alerts

Momentum Deviation Bands [Loxx]Momentum Deviation Bands uses a variation of standard deviation. Instead of using price to calculate standard deviation, this uses momentum. This is another type of volatility that will be used in future indicators. This indicator serves more as an educational tool, but can also be used in trading.
You can read about the included moving averages here:
Included
Bar coloring

ER-Adaptive ATR Limit Channels w/ States [Loxx]As simple as it gets, channels based on high, low and ATR distances, Shows possible short term support / resistance or can be used as a take profit/stop-loss in some trading systems. It does this by comparing high/low values of price to multiplied by a multiple of ATR to determine when the trend changes. States are included to change the sensitivity to trend changes. 1 is very sensitive, 3 is least sensitive.
This uses Loxx's Expanded Source Types. You can read about them here:
What is ER Adaptive ATR?
Average True Range (ATR) is widely used indicator in many occasions for technical analysis . It is calculated as the RMA of true range. This version adds a "twist": it uses Perry Kaufman's Efficiency Ratio to calculate adaptive true range
Possible RSI [Loxx]Possible RSI is a normalized, variety second-pass normalized, Variety RSI with Dynamic Zones and optionl High-Pass IIR digital filtering of source price input. This indicator includes 7 types of RSI.
High-Pass Fitler (optional)
The Ehlers Highpass Filter is a technical analysis tool developed by John F. Ehlers. Based on aerospace analog filters, this filter aims at reducing noise from price data. Ehlers Highpass Filter eliminates wave components with periods longer than a certain value. This reduces lag and makes the oscialltor zero mean. This turns the RSI output into something more similar to Stochasitc RSI where it repsonds to price very quickly.
First Normalization Pass
RSI (Relative Strength Index) is already normalized. Hence, making a normalized RSI seems like a nonsense... if it was not for the "flattening" property of RSI. RSI tends to be flatter and flatter as we increase the calculating period--to the extent that it becomes unusable for levels trading if we increase calculating periods anywhere over the broadly recommended period 8 for RSI. In order to make that (calculating period) have less impact to significant levels usage of RSI trading style in this version a sort of a "raw stochastic" (min/max) normalization is applied.
Second-Pass Variety Normalization Pass
There are three options to choose from:
1. Gaussian (Fisher Transform), this is the default: The Fisher Transform is a function created by John F. Ehlers that converts prices into a Gaussian normal distribution. The normaliztion helps highlights when prices have moved to an extreme, based on recent prices. This may help in spotting turning points in the price of an asset. It also helps show the trend and isolate the price waves within a trend.
2. Softmax: The softmax function, also known as softargmax: or normalized exponential function, converts a vector of K real numbers into a probability distribution of K possible outcomes. It is a generalization of the logistic function to multiple dimensions, and used in multinomial logistic regression. The softmax function is often used as the last activation function of a neural network to normalize the output of a network to a probability distribution over predicted output classes, based on Luce's choice axiom.
3. Regular Normalization (devaitions about the mean): Converts a vector of K real numbers into a probability distribution of K possible outcomes without using log sigmoidal transformation as is done with Softmax. This is basically Softmax without the last step.
Dynamic Zones
As explained in "Stocks & Commodities V15:7 (306-310): Dynamic Zones by Leo Zamansky, Ph .D., and David Stendahl"
Most indicators use a fixed zone for buy and sell signals. Here’ s a concept based on zones that are responsive to past levels of the indicator.
One approach to active investing employs the use of oscillators to exploit tradable market trends. This investing style follows a very simple form of logic: Enter the market only when an oscillator has moved far above or below traditional trading lev- els. However, these oscillator- driven systems lack the ability to evolve with the market because they use fixed buy and sell zones. Traders typically use one set of buy and sell zones for a bull market and substantially different zones for a bear market. And therein lies the problem.
Once traders begin introducing their market opinions into trading equations, by changing the zones, they negate the system’s mechanical nature. The objective is to have a system automatically define its own buy and sell zones and thereby profitably trade in any market — bull or bear. Dynamic zones offer a solution to the problem of fixed buy and sell zones for any oscillator-driven system.
An indicator’s extreme levels can be quantified using statistical methods. These extreme levels are calculated for a certain period and serve as the buy and sell zones for a trading system. The repetition of this statistical process for every value of the indicator creates values that become the dynamic zones. The zones are calculated in such a way that the probability of the indicator value rising above, or falling below, the dynamic zones is equal to a given probability input set by the trader.
To better understand dynamic zones, let's first describe them mathematically and then explain their use. The dynamic zones definition:
Find V such that:
For dynamic zone buy: P{X <= V}=P1
For dynamic zone sell: P{X >= V}=P2
where P1 and P2 are the probabilities set by the trader, X is the value of the indicator for the selected period and V represents the value of the dynamic zone.
The probability input P1 and P2 can be adjusted by the trader to encompass as much or as little data as the trader would like. The smaller the probability, the fewer data values above and below the dynamic zones. This translates into a wider range between the buy and sell zones. If a 10% probability is used for P1 and P2, only those data values that make up the top 10% and bottom 10% for an indicator are used in the construction of the zones. Of the values, 80% will fall between the two extreme levels. Because dynamic zone levels are penetrated so infrequently, when this happens, traders know that the market has truly moved into overbought or oversold territory.
Calculating the Dynamic Zones
The algorithm for the dynamic zones is a series of steps. First, decide the value of the lookback period t. Next, decide the value of the probability Pbuy for buy zone and value of the probability Psell for the sell zone.
For i=1, to the last lookback period, build the distribution f(x) of the price during the lookback period i. Then find the value Vi1 such that the probability of the price less than or equal to Vi1 during the lookback period i is equal to Pbuy. Find the value Vi2 such that the probability of the price greater or equal to Vi2 during the lookback period i is equal to Psell. The sequence of Vi1 for all periods gives the buy zone. The sequence of Vi2 for all periods gives the sell zone.
In the algorithm description, we have: Build the distribution f(x) of the price during the lookback period i. The distribution here is empirical namely, how many times a given value of x appeared during the lookback period. The problem is to find such x that the probability of a price being greater or equal to x will be equal to a probability selected by the user. Probability is the area under the distribution curve. The task is to find such value of x that the area under the distribution curve to the right of x will be equal to the probability selected by the user. That x is the dynamic zone.
7 Types of RSI
See here to understand which RSI types are included:
Included:
Bar coloring
4 signal types
Alerts
Loxx's Expanded Source Types
Loxx's Variety RSI
Loxx's Dynamic Zones
STD-Filtered, Adaptive Exponential Hull Moving Average [Loxx]STD-Filtered, Adaptive Exponential Hull Moving Average is a Kaufman Efficiency Ratio Adaptive Hull Moving Average that uses EMA instead of WMA for its computation. I've also added standard deviation stepping to further smooth the signal. Using EMA instead of WMA turns the Hull into what's called the AEHMA. You can read more about the EHMA here: eceweb1.rutgers.edu
What is the traditional Hull Moving Average?
The Hull Moving Average (HMA) attempts to minimize the lag of a traditional moving average while retaining the smoothness of the moving average line. Developed by Alan Hull in 2005, this indicator makes use of weighted moving averages to prioritize more recent values and greatly reduce lag. The resulting average is more responsive and well-suited for identifying entry points.
What is Kaufman's Efficiency Ratio?
The Efficiency Ratio (ER) was first presented by Perry Kaufman in his 1995 book ‘Smarter Trading‘. It is calculated by dividing the price change over a period by the absolute sum of the price movements that occurred to achieve that change. The resulting ratio ranges between 0 and 1 with higher values representing a more efficient or trending market.
The value of the ER ranges between 0 and 1. It has the value of 1 when prices move in the same direction for the full time over which the indicator is calculated, e.g. n bars period. It has a value of 0 when prices are unchanged over the n periods. When prices move in wide swings within the interval, the sum of the denominator becomes very large compared to the numerator and ER approaches zero.
Some uses for ER:
A qualifier for a trend following trade; a trend is considered “persistent” only when RE is above a certain value, e.g. 0.3 or 0.4 .
A filter to screen out choppy stocks/markets, where breakouts are frequently “fakeouts”.
In an adaptive trading system, helping to determine whether to apply a trend following algorithm or a mean reversion algorithm.
It is used in the calculation of Kaufman’s Adaptive Moving Average (KAMA).
How to calculate the Hull Adaptive Moving Average (HAMA)
Find Signal to Noise ratio (SNR)
Normalize SNR from 0 to 1
Calculate adaptive alphas
Apply EMAs
Included
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types

Ehlers Linear Extrapolation Predictor [Loxx]Ehlers Linear Extrapolation Predictor is a new indicator by John Ehlers. The translation of this indicator into PineScript™ is a collaborative effort between @cheatcountry and I.
The following is an excerpt from "PREDICTION" , by John Ehlers
Niels Bohr said “Prediction is very difficult, especially if it’s about the future.”. Actually, prediction is pretty easy in the context of technical analysis. All you have to do is to assume the market will behave in the immediate future just as it has behaved in the immediate past. In this article we will explore several different techniques that put the philosophy into practice.
LINEAR EXTRAPOLATION
Linear extrapolation takes the philosophical approach quite literally. Linear extrapolation simply takes the difference of the last two bars and adds that difference to the value of the last bar to form the prediction for the next bar. The prediction is extended further into the future by taking the last predicted value as real data and repeating the process of adding the most recent difference to it. The process can be repeated over and over to extend the prediction even further.
Linear extrapolation is an FIR filter, meaning it depends only on the data input rather than on a previously computed value. Since the output of an FIR filter depends only on delayed input data, the resulting lag is somewhat like the delay of water coming out the end of a hose after it supplied at the input. Linear extrapolation has a negative group delay at the longer cycle periods of the spectrum, which means water comes out the end of the hose before it is applied at the input. Of course the analogy breaks down, but it is fun to think of it that way. As shown in Figure 1, the actual group delay varies across the spectrum. For frequency components less than .167 (i.e. a period of 6 bars) the group delay is negative, meaning the filter is predictive. However, the filter has a positive group delay for cycle components whose periods are shorter than 6 bars.
Figure 1
Here’s the practical ramification of the group delay: Suppose we are projecting the prediction 5 bars into the future. This is fine as long as the market is continued to trend up in the same direction. But, when we get a reversal, the prediction continues upward for 5 bars after the reversal. That is, the prediction fails just when you need it the most. An interesting phenomenon is that, regardless of how far the extrapolation extends into the future, the prediction will always cross the signal at the same spot along the time axis. The result is that the prediction will have an overshoot. The amplitude of the overshoot is a function of how far the extrapolation has been carried into the future.
But the overshoot gives us an opportunity to make a useful prediction at the cyclic turning point of band limited signals (i.e. oscillators having a zero mean). If we reduce the overshoot by reducing the gain of the prediction, we then also move the crossing of the prediction and the original signal into the future. Since the group delay varies across the spectrum, the effect will be less effective for the shorter cycles in the data. Nonetheless, the technique is effective for both discretionary trading and automated trading in the majority of cases.
EXPLORING THE CODE
Before we predict, we need to create a band limited indicator from which to make the prediction. I have selected a “roofing filter” consisting of a High Pass Filter followed by a Low Pass Filter. The tunable parameter of the High Pass Filter is HPPeriod. Think of it as a “stone wall filter” where cycle period components longer than HPPeriod are completely rejected and cycle period components shorter than HPPeriod are passed without attenuation. If HPPeriod is set to be a large number (e.g. 250) the indicator will tend to look more like a trending indicator. If HPPeriod is set to be a smaller number (e.g. 20) the indicator will look more like a cycling indicator. The Low Pass Filter is a Hann Windowed FIR filter whose tunable parameter is LPPeriod. Think of it as a “stone wall filter” where cycle period components shorter than LPPeriod are completely rejected and cycle period components longer than LPPeriod are passed without attenuation. The purpose of the Low Pass filter is to smooth the signal. Thus, the combination of these two filters forms a “roofing filter”, named Filt, that passes spectrum components between LPPeriod and HPPeriod.
Since working into the future is not allowed in EasyLanguage variables, we need to convert the Filt variable to the data array XX . The data array is first filled with real data out to “Length”. I selected Length = 10 simply to have a convenient starting point for the prediction. The next block of code is the prediction into the future. It is easiest to understand if we consider the case where count = 0. Then, in English, the next value of the data array is equal to the current value of the data array plus the difference between the current value and the previous value. That makes the prediction one bar into the future. The process is repeated for each value of count until predictions up to 10 bars in the future are contained in the data array. Next, the selected prediction is converted from the data array to the variable “Prediction”. Filt is plotted in Red and Prediction is plotted in yellow.
The Predict Extrapolation indicator is shown above for the Emini S&P Futures contract using the default input parameters. Filt is plotted in red and Predict is plotted in yellow. The crossings of the Predict and Filt lines provide reliable buy and sell timing signals. There is some overshoot for the shorter cycle periods, for example in February and March 2021, but the only effect is a late timing signal. Further reducing the gain and/or reducing the BarsFwd inputs would provide better timing signals during this period.
ADDITIONS
Loxx's Expanded source types:
Library for expanded source types:
Explanation for expanded source types:
Three different signal types: 1) Prediction/Filter crosses; 2) Prediction middle crosses; and, 3) Filter middle crosses.
Bar coloring to color trend.
Signals, both Long and Short.
Alerts, both Long and Short.
