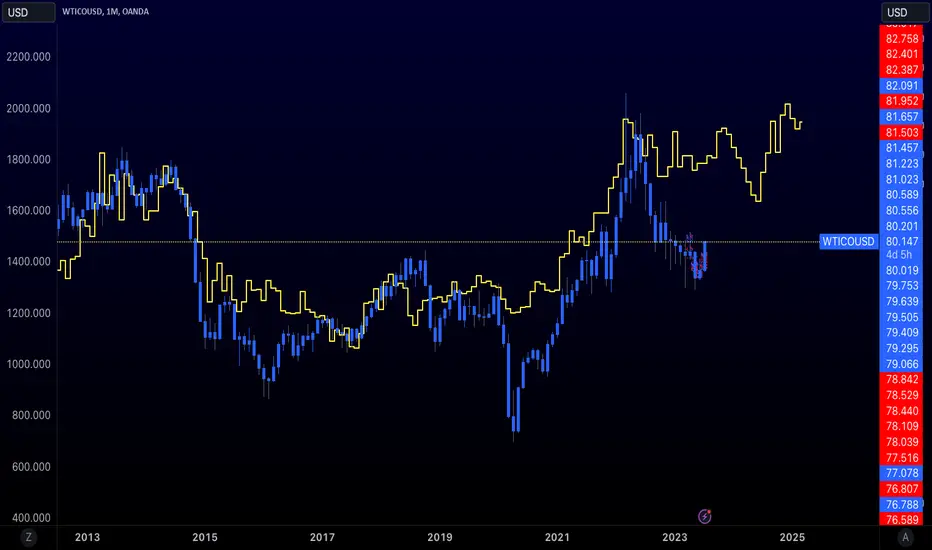
Oil Price Prediction (Highly Accurate)It's a little-known fact that gold prices move preceded oil prices by 20 months.
If you don't believe me here is a short video from Tom McClellan discussing this www.cnbc.com
This gives us one of the best and highly accurate indicators of what oil will do in the months to come.
HOW TO USE.
When adding the script to your charts it's important to make a couple of adjustments.
Click the triple dots (...), scroll down to pin to scale, and click pin to new scale.
Rght-click the new scale and click auto (fits data to screen)
Go into the indicator settings and turn off the red line.
What you'll be left with is a price projection on where oil prices will go. This becomes your 30,000-foot view. It is important for traders to know if they're coming into a bullish, bearish or consolidating market and this indicator does that.
Its important to mention this is for Monthly charts.
Happy Trading
Forecasting
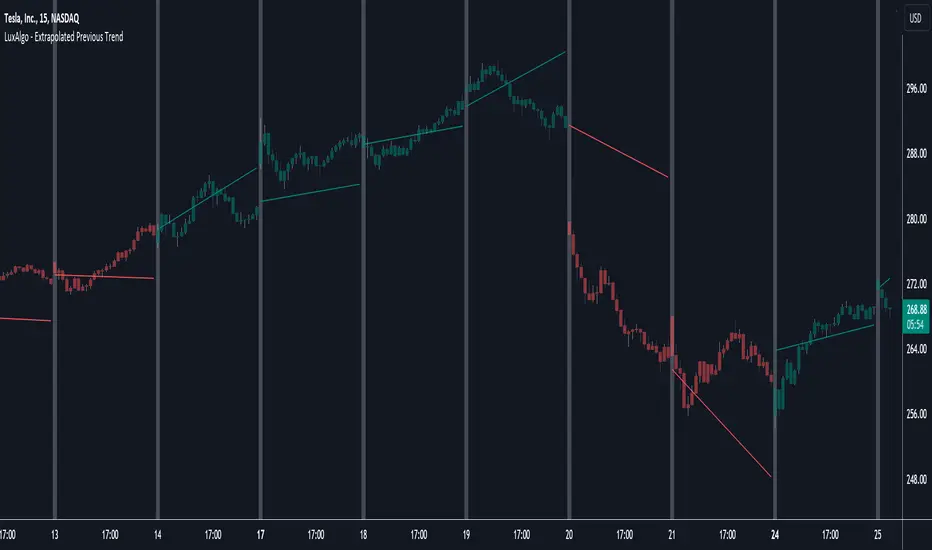
Extrapolated Previous Trend [LuxAlgo]The Extrapolated Previous Trend indicator extrapolates the estimated linear trend of the prices within a previous interval to the current interval. Intervals can be user-defined.
🔶 USAGE
Returned lines can be used to provide a forecast of trends, assuming trends are persistent in sign and slope.
Using them as support/resistance can also be an effecting usage in case the trend in a new interval does not follow the characteristic of the trend in the previous interval.
The indicator includes a dashboard showing the degree of persistence between segmented trends for uptrends and downtrends. A higher value is indicative of more persistent trend signs.
A lower value could hint at an anti-persistent behavior, with uptrends over an interval often being followed by a down-trend and vice versa. We can invert candle colors to determine future trend direction in this case.
🔶 DETAILS
This indicator can be thought of as a segmented linear model ( a(n)t + b(n) ), where n is the specific interval index. Unlike a regular segmented linear regression model, this indicator is not subject to lookahead bias, coefficients of the model are obtained on previous intervals.
The quality of the fit of the model is dependent on the variability of its coefficients a(n) and b(n) . Coefficients being less subject to change over time are more indicative of trend persistence.
🔶 SETTINGS
Timeframe: Determine the frequency at which new trends are estimated.
Quarterly Version: Sustainable Growth Rate+ (SGR+)The Sustainable Growth Rate+ (SGR+) is an advanced financial indicator designed to estimate the sustainable growth rate of a company in a more comprehensive manner than the traditional Sustainable Growth Rate (SGR). This indicator has been created to overcome certain limitations of the traditional SGR, especially its reliance on Return on Equity (ROE), which does not take into account the impact of debt on a company's growth.
Calculation:
The SGR+ is calculated using the following formula:
(Net Income - Dividends - Depreciation & Amortization) / (Shareholders' Equity + Long-Term Debt)
This formula essentially adjusts the net income by subtracting dividends and depreciation & amortization expenses. The result is then divided by the sum of shareholders' equity and long-term debt. By including long-term debt in the denominator, SGR+ accounts for the role of debt in a company's capital structure, providing a more realistic picture of its potential growth.
Logic:
The logic behind the SGR+ is to factor in both the role of debt and the recurring costs of asset maintenance/replacement (approximated by Depreciation & Amortization expenses) into the growth estimation.
By incorporating debt, we capture a company's total capital employed (equity + debt) rather than just equity, thus considering the full range of financing options used to fuel growth.
Depreciation & Amortization expenses are subtracted from net income to better reflect the amount of earnings that can be retained for growth, as these expenses indicate the necessary reinvestment for maintaining the operational efficiency of a company's assets.
History:
The original SGR was based on the Dupont Analysis developed by the Dupont Corporation in the 1920s. While it provided a useful estimate of a company's potential growth, many analysts felt that it did not fully capture the realities of modern business finance, particularly the significant role of debt and recurring asset costs. This led to the development of the SGR+, which factors in these important elements to provide a more comprehensive and realistic measure of a company's sustainable growth rate.
Usage:
While SGR+ provides a more nuanced estimate of a company's potential growth, it should not be used in isolation. It is most effective when used alongside other financial indicators, including historical growth rates, ROE, and analyst forecasts. It also requires a careful evaluation of a company's earnings consistency and volatility.
Remember, the SGR+ is still an estimation based on various assumptions, and should be used with a sufficient margin of safety. Regularly comparing the SGR+ over multiple years can provide insight into the stability or volatility of a company's growth rate, contributing to a more accurate growth prediction.
Nadaraya-Watson Envelope Strategy (Non-Repainting) Log ScaleIn the diverse world of trading strategies, the Nadaraya-Watson Envelope Strategy offers a different approach. Grounded in mathematical analysis, this strategy utilizes the Nadaraya-Watson kernel regression, a method traditionally employed for interpreting complex data patterns.
At the core of this strategy lies the concept of 'envelopes', which are essentially dynamic volatility bands formed around the price based on a custom Average True Range (ATR). These envelopes help provide guidance on potential market entry and exit points. The strategy suggests considering a buy when the price crosses the lower envelope and a sell when it crosses the upper envelope.
One distinctive characteristic of the Nadaraya-Watson Envelope Strategy is its use of a logarithmic scale, as opposed to a linear scale. The logarithmic scale can be advantageous when dealing with larger timeframes and assets with wide-ranging price movements.
The strategy is implemented using Pine Script v5, and includes several adjustable parameters such as the lookback window, relative weighting, and the regression start point, providing a level of flexibility.
However, it's important to maintain a balanced view. While the use of mathematical models like the Nadaraya-Watson kernel regression may provide insightful data analysis, no strategy can guarantee success. Thorough backtesting, understanding the mathematical principles involved, and sound risk management are always essential when applying any trading strategy.
The Nadaraya-Watson Envelope Strategy thus offers another tool for traders to consider. As with all strategies, its effectiveness will largely depend on the trader's understanding, application, and the specific market conditions.

Adaptive Price Channel (log scale)The field of technical analysis is consistently expanding, with numerous indicators used for market forecasting. Amongst them, a novel indicator dubbed the Adaptive Price Channel (log scale), inspired by the renowned Nadaraya-Watson Envelope (LuxAlgo) from LuxAlgo, is gaining traction for its distinctive features and versatility. Unlike its predecessor, the Adaptive Price Channel (log scale) is applicable on a logarithmic scale, thereby allowing it to be utilized on both smaller and larger timeframes.
1. Key Features
The Adaptive Price Channel (log scale) is founded on the trading view Pinescript language, version 5, with its primary aim to maximize the versatility and scalability of trading indicators. It allows traders to adapt it according to their preferred timeframe, thereby making it applicable for a wide range of trading strategies.
Its bandwidth can be adjusted through the input parameters, offering traders the flexibility to manipulate the indicator according to their strategic requirements. Furthermore, it provides an option for repainting smoothing. This option enables users to control the repainting effect in which the historical output of the indicator may change over time. When disabled, the indicator provides the endpoints of the calculations, ensuring consistency in historical values.
Moreover, the Adaptive Price Channel (log scale) allows for color customization, thereby improving visibility and user-friendliness. The colors of the indicator's upward and downward directions can be changed according to the user's preference.
2. Working Mechanism
The Adaptive Price Channel (log scale) uses the logarithm of the source, which is typically the closing price of a trading instrument. It leverages a Gaussian function that exponentially decreases the further the price moves away from the mean, accounting for both positive and negative values. The bandwidth of the Gaussian function can be adjusted to adapt to different market conditions.
Additionally, the Adaptive Price Channel (log scale) features an array of 500 lines for each bar, which helps in defining the boundaries or envelope for price movements. The calculations are executed using the Nadaraya-Watson estimator, which uses kernel regression for non-parametric analysis.
The calculated values for the upper and lower bounds of the envelope are then converted back from the logarithmic scale using the exponential function. This calculation process continues for each bar until the last bar in the data set.
To ensure optimal performance, the Adaptive Price Channel (log scale) uses dynamic repainting. If the repainting mode is enabled, it adjusts the smoothing of the indicator for the entire historical data, making the results more accurate.
3. Visualization and Alerts
The Adaptive Price Channel (log scale) offers an array of visual aids, including labels and plots. The upper and lower bounds of the envelope are plotted, and the indicator triggers labels at points where the closing price crosses these boundaries. These labels serve as alerts for potential trading opportunities.
4. Conclusion
The Adaptive Price Channel (log scale) is an innovative and adaptable trading indicator, drawing inspiration from its predecessor but introducing unique features to increase its versatility. By providing a repainting option, it ensures consistent historical values, thereby enhancing the reliability of the indicator. Furthermore, the capability to operate on a logarithmic scale broadens its usability for different timeframes. The Adaptive Price Channel (log scale) is a powerful tool for any trader, facilitating a better understanding of market dynamics, and enabling more informed decision-making.

Crunchster's Normalised Trend StrategyThis is a unique rules-based, systematic trading strategy - in the trend following category.
The strategy is designed for use on the daily timeframe. Specific features of this strategy are outlined below:
1. Uses a transformed price series (which I dub "real price") to generate signals rather than ticker price
2. Uses advanced position sizing and risk management, usually reserved for institutional portfolio management, a proven technique utilised by Commodity Trading Advisors and Managed Futures funds (Algo/Quant funds).
"Real Price" is a transformed price series derived from the sum of volatility adjusted (daily) returns, over the entire price series of an asset. The lookback period of the volatility adjustment is user defined.
A Hull moving average (HMA) is derived from the real price, and used as the main trend determinant. The lookback period of the HMA is user defined. Default lookback of 100 periods (days) ensures a responsive trend indicator, but without leading to over-trading from frequent crossovers (average holding period 14 days on BTC).
The core strategy is very simple, go long when real price crosses over HMA, go short when real price crosses under HMA. New position triggers automatically close open positions in the counter direction.
Position sizing is based on recent price volatility and the user defined annualised risk target. In essence positions are inverse volatility weighted, so larger size is opened during lower volatility and smaller size during increased volatility. Recent volatility is calculated as the standard deviation of returns with 14 period lookback, then extrapolated into an annualised volatility of expected returns. Annualised recent volatility is then referenced to the risk target set by the user to adjust the position size. The default settings are a very conservative 10% annual risk target. Initial capital should be set as the maximum risk capital per trade (ie if $10,000 total capital and 10% risk per trade, initial capital should be $1000). Maximum leverage per position can be set independently, to facilitate hitting risk targets that are greater than the natural volatility of the traded asset, and to accommodate low volatility conditions, whilst maintaining overall risk controls.
Hard stop losses are based on multiples of the average true range of recent price (14 period lookback), user configurable.
Please leave comments regarding further features or refinements. I plan to develop further adding alternative moving average selections and the ability to select/deselect long and short strategies.
3 hours ago
Release Notes:
Added option to compound profits versus using a fixed position capital. Be mindful that compounding will potentially increase profits, but also increase drawdowns and overall risk. Leverage will still cap overall exposure with compounding and therefore provides an additional layer of risk control.
2 hours ago
Release Notes:
Added function to toggle long/short strategy legs on and off.
ICT Friday's Asian Range°This concept was engineered and taught by the Inner Circle Trader .
The goal of this script is to outline a potential draw on liquidity for the next trading week. It gives a parameter for ICT PD Arrays to be located above and below the marketplace and should be used in conjunction with the higher Timeframe Arrays as defined by ICT.
If there is a higher Timeframe array with a standard deviation confluence of the Friday Asian Range it is considered high probability for price to reach up/down to that level, and present a potential retracement or reversal.
The Asian Range is defined as the window of Time between 7PM to Midnight New York Time. In this case we will be only using the Friday's Asian Range which will take place on Thursday between these Times.
We have two ranges: a Body range made of the highest and lowest candle bodies, and a Wick range made by the highest and lowest candle wicks.
ICT teaches that we only want to apply this concept to the 5minute and 15minute chart.
THIS SCRIPT WILL NOT WORK ON ANY OTHER TIMEFRAME OUT OF THE BOX
Framework:
Visualization:
Example:

Crunchster's Real PriceThis is a simple transformation of any price series (best suited to daily timeframe) that filters out random price fluctuations and revealing the "real" price action. It allows comparison between different assets easily and is a useful confirmation of support and resistance levels, or can be used with other technical analysis.
In the default settings based on a daily chart, the daily returns are first calculated, then volatility normalised by dividing by the standard deviation of daily returns over the defined lookback period (14 periods by default).
These normalised returns are then added together over the entire price series period, to create a new "Real price" - the volatility adjusted price. This is the default presentation.
In addition, a second signal ("Normalised price series over rolling period") is available which, instead of summing the normalised returns over the entire price series, allows a user configurable, rolling lookback window over which the normalised returns are summed up. The default setting is 365 periods (ie 1 year on the daily timeframe for tickers with 24hr markets such as crypto. This can be set to 252 periods if analysing equities, which only trade 5 days per week, or any other user defined period of interest).

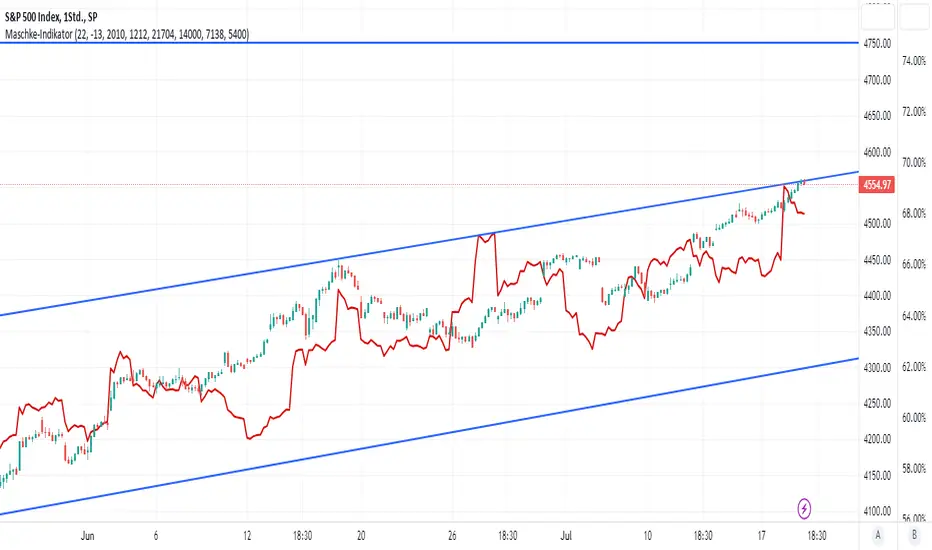
Maschke-IndikatorThis indicator is based on market data independently from the current chart being used. It considers data from FED (M2, net liquidity) as well as heavy truck index and Redbook index. This combination allows the determination of the current market situation and factors that influence short term future economy.
As an indicator is not able to determine the absolute maximum values and it does not make sense to shed light back to history more than 5 years or to consider those minimum values long time ago, the default minimum and maximum values for the 4 primary indicators have been selected to fix to those in the last 5 years, with the possibility to change the consideration limits for the user. As the index is calculated in percentage between those ranges, the values entered for minimum and maximum have great influence, but also give the experienced user the possibility to change those limits based on her or his knowledge.
This indicator has a particularly high correlation with the S&P 500. It is clearly leading in some places. I use the indicator on the daily and hourly charts, manually bring the indicator over the S&P chart as best I can and see if the indicator is showing a major breakout ahead that the chart hasn't followed yet. Larger deviations are also a sign that the price is moving too far away from the indicator and that this deviation will probably be closed in the near future. The indicator shows the theoretical course more from the economic side, how the course should run. The deviation is therefore primarily due to the mood. I recommend using the indicator together with others, so as not to rely on this indicator alone.
Open Price Regression Modelnput Variables: The user can adjust the lookbackPeriod and m (multiplier) inputs. The lookbackPeriod specifies the number of previous bars used for regression calculations, and m is used to calculate the confidence interval width.
Calculate Regression Model: The code extracts open, high, low, and close prices for the current candle. It then performs regression calculations for high, low, and close prices based on the open prices.
Calculate Predicted Prices: Using the regression coefficients and intercepts, the code calculates predicted high, low, and close prices based on the current open price.
Calculate Confidence Interval: The code computes the standard errors of the regression for high, low, and close prices and multiplies them by the specified confidence level multiplier (m) to determine the width of the confidence intervals.
Plotting: The predicted high, low, and close prices are plotted with different colors. Additionally, confidence intervals are plotted around the predicted prices using lines.
Implications and Trading Advantage:
The Open Price Regression Model aims to predict future high, low, and close prices based on the current open price. Traders can use the predicted values and confidence intervals as potential price targets and volatility measures. Traders can consider taking long or short positions based on whether the current open price is below or above the predicted prices. Can be used on a daily time frame to forecast the day's high and low and use this levels are horizontal price levels on lower timeframes.

Main Market Opener Breakout [RH]Based on my observations while analyzing the crypto and forex charts, particularly BTCUSDT and EURUSD, I have noticed that the prices exhibit significant movements during most stock market sessions, particularly during New York main market session.
With the aim of capturing these moves, I embarked on extensive research. Through this research, I discovered that by considering the very first "15m" or "30m" candle of the main market trading session and marking that first candle's high and low points, we can create potential trigger points.
A break above the high point indicates a bullish signal, while a break below the low point suggests a bearish signal. To further refine our analysis and filter out some noise, we can incorporate the Average True Range (ATR) value of that candle.
Candle time is very important here. We will mark the candle when the actual trading begins in New York stock exchange. The trading hours for the New York Stock Exchange (NYSE) typically begin at 9:30 AM and end at 4:00 PM Eastern Time (ET), Monday through Friday. This is known as the "NYSE Regular Trading Session." However, it's important to note that there are also pre-market and after-hours trading sessions that occur outside of these core hours. We will not consider these pre and after-hours.
Example:
First break-above and break-below is marked automatically and alerts are also available for first breaks.
Example:
I have also added the option to add the, London Stock Exchange Main Market and Tokyo Stock Exchange Regular Trading Session. You can add those sessions also and test with different symbols.
Stocks symbols from different stock exchanges just mark the very first candle of the day(main market trading session).
Alerts are available.

Wick-to-Body Ratio Trend Forecast | Flux ChartsThe Wick-to-Body Ratio Trend Forecast Indicator aims to forecast potential movements following the last closed candle using the wick-to-body ratio. The script identifies those candles within the loopback period with a ratio matching that of the last closed candle and provides an analysis of their trends.
➡️ USAGE
Wick-to-body ratios can be used in many strategies. The most common use in stock trading is to discern bullish or bearish sentiment. This indicator extends candle ratios, revealing previous patterns that follow a candle with a similar ratio. The most basic use of this indicator is the single forecast line.
➡️ FORECASTING SYSTEM
This line displays a compilation of the averages of all the previous trends resulting from those historical candles with a matching ratio. It shows the average movements of the trends as well as the 'strength' of the trend. The 'strength' of the trend is a gradient that is blue when the trend deviates more from the average and red when it deviates less.
Chart: AMEX:SPY 30 min; Indicator Settings: Loopback 700, Previous Trends ON
The color-coded deviation is visible in this image of the indicator with the default settings (except for Forecast Lines > Previous Trends ), and the trend line grows bluer as the past patterns deviate more.
➡️ ADAPTIVE ACCEPTABLE RANGE
The algorithm looks back at every candle within the loopback period to find candles that match the last closed candle. The algorithm adaptively changes the acceptable range to which a candle can differ from the ratio of the last closed candle. The algorithm will never have more than 15 historical points used, as it will lower its sensitivity before it reaches that point.
Chart: BITSTAMP:BTCUSD 5 min; Indicator Settings: Loopback 700
Here is the BTC chart on 7/6/23 with default settings except for the loopback period at 700.
Chart: BITSTAMP:BTCUSD 5 min; Indicator Settings: Loopback 200
Here is the exact same chart with a loopback period of 200. While the first ratio for both is the same, a new ratio is revealed for the chart with a loopback of only 200 because the adaptive range is adjusted in the algorithm to find an acceptable number of reference points. Note the table in the top right however, while the algorithm adapts the acceptable range between the current ratio and historical ones to find reference points, there is a threshold at which candles will be considered too inaccurate to be considered. This prevents meaningless associations between candles due to a particularly rare ratio. This threshold can be adjusted in the settings through "Default Accuracy".

Trend Reversal PredictorTrend Reversal Predictor - An Indicator for Identifying Potential Trend Reversals
This indicator is designed to help traders identify potential trend reversals in the financial markets. It combines multiple criteria including trend identification, volume analysis, average net price movement, and RSI (Relative Strength Index) crossing its moving average to highlight potential danger zones where a trend reversal may occur.
How it Works:
1. Trend Identification: The script uses the Hull Moving Average (HMA) and Parabolic SAR to determine the prevailing trend. The HMA is a smoothing indicator that reduces lag and provides a clear representation of the trend direction.
2. Danger Zone Identification: The script analyzes volume-related metrics and average net price movement to identify potential danger zones where trend reversals might occur. It calculates the rate of change of buying and selling volume and compares it to their respective averages. Additionally, it considers the average net price movement over a specified period.
3. RSI Integration: The script incorporates the RSI, a momentum oscillator, to evaluate overbought and oversold conditions. It calculates the RSI based on user-defined length and source inputs. It also calculates the RSI's moving average using different types of moving averages (SMA, EMA, etc.) specified by the user.
4. Trend Ending Prediction: By combining the conditions of trend identification, volume analysis, average net price movement, and RSI crossing its moving average, the script identifies potential trend reversal points or danger zones. These danger zones are highlighted on the chart using different colors to represent potential uptrend and downtrend reversals.
How to Use:
2. Danger Zone Highlighting: The script highlights potential danger zones on the chart using orange color for uptrend danger zones and blue color for downtrend danger zones. These danger zones suggest areas where a trend reversal may occur.
3. Additional Analysis: Traders can further analyze the danger zones based on their trading strategy and risk management. Consider other technical indicators, price action, and fundamental factors to make informed trading decisions.
Please note that this script provides potential signals for trend reversals but does not guarantee their occurrence. It is important to use this indicator in conjunction with other technical analysis tools and risk management techniques to make well-informed trading decisions.
By understanding the underlying concepts and using the provided visual cues, traders can leverage the Trend Reversal Predictor to potentially identify potential trend reversals in the markets.

Cycles AnalysisI strongly believe in cycles, so I wanted to create something that would give a visual representation of bull/bear markets and give a prediction based on the previous data. It's up to you how to decide what is a bull/bear cycle. There is no single rule for all assets because 20% drop in SP500 starts a bear market in traditional markets, while 35% drop for Bitcoin is a Tuesday. You have two options on how to decide when markets turn: either by a % change (traditional definition) or if there is no new high/low after X days. A softer version to show periods of no new highs/lows is to use the Stagnation option. Stagnation periods hava the same logic as the cycle change by X days: if there is no new high/low then we treat this period as a stagnation. The difference is that stagnation periods do not change cycle directions and do not participate in calculations.
The script also draws a possible "predictions" zone where the current cycle might end up. There is no magic here, it just takes previous cycles' size to draw the possible boundaries. If you decide to use percentiles then the box area will be taken from the percentiles calculations, otherwise it will come from the full data. "x" in the predictions zone represents a target mean (average) value, "o" represents a target median value.
A few things to keep in mind:
- this script is not supposed to be used in trading. It was created for analysis. It repaints. And when I say "it repaints" - it might like repaint the last 6 months of data if a new low comes and we are in a stagnation period (aka not a financial advice).
- it doesn't work with replays as it does calculations only once on the last candle.
- you need at least 3 periods to be able to calculate percentiles. And after this it will remove at least 1 period on each side. Which means that 90 percentile will not be a real 90 percentile until you have enough periods for it to be (20 in this specific case).
- it assumes that a year = 360 days, and a month = 30 days. So the duration presentation might not be exact, until you move to the day level.
- I had macro analysis in mind when I created the script, but nothing stops you from using it in a 1m time frame for BTC. Just change the time duration presentation.
- the last period is not finished, so it doesn't participate in calculations.

K's Pivot PointsPivot points are a popular technical analysis tool used by traders to identify potential levels of support and resistance in a given timeframe. Pivot points are derived from previous price action and are used to estimate potential price levels where an asset may experience a reversal, breakout, or significant price movement.
The calculation of pivot points involves a simple formula that takes into account the high, low, and close prices from the previous trading session or a specific period. The most commonly used pivot point calculation method is the "Standard" or "Classic" method. Here's the formula:
Pivot Point (P) = (High + Low + Close) / 3
In addition to the pivot point itself, several support and resistance levels are calculated based on the pivot point value.
K's Pivot Points try to enhance them by incorporating multiple elements and by applying a re-integration strategy to validate two events:
* Found_Support: This event represents a basing market that is bound to recover or at least shape a bounce.
* Found_Resistance: This event represents a toppish market that is bound to consolidate or at least shape a pause.
K's Pivot Points are calculated following these steps:
1. Calculate the highest of highs for the previous 24 periods (preferably hours).
2. Calculate the lowest of lows for the previous 24 periods (preferably hours).
3. Calculate a 24-period (preferably hours) moving average of the close price.
4. Calculate K's Pivot Point as the average between the three previous step.
5. To find the support, use this formula: Support = (Lowest K's pivot point of the last 12 periods * 2) - Step 1
6. To find the resistance, use this formula: Resistance = (Highest K's pivot point of the last 12 periods * 2) - Step 2
The re-integration strategy to find support and resistance areas is as follows:
* A support has been found if the market breaks the support and shapes a close above it afterwards.
* A resistance has been found if the market surpasses the resistance and shapes a close below it afterwards.
The lookback period (whether 24 and 12) can be modified but the default versions work well.

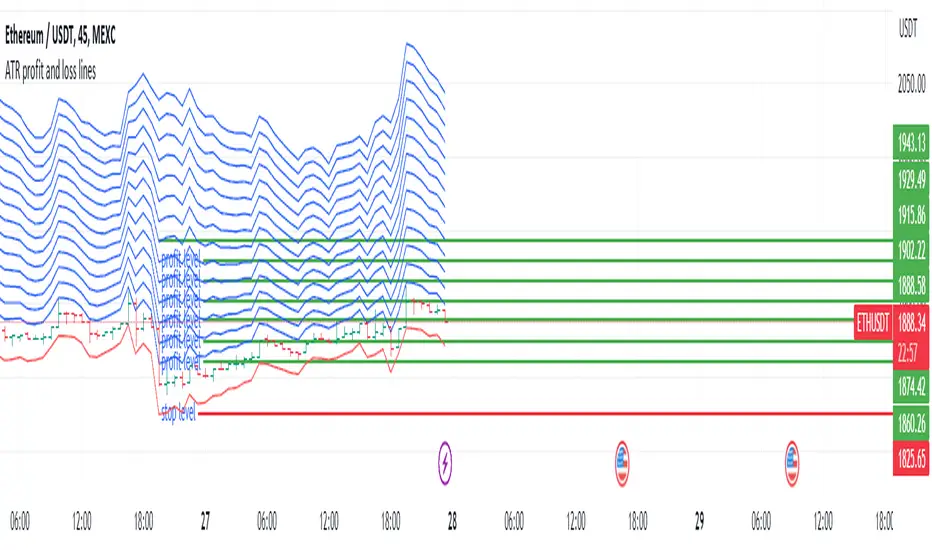
ATR profit and loss linesWhat is ATR?
Taking a candlestick, the following 3 transactions are calculated:
1-The difference between the high of the day and the low of the day
2-The difference between today's high and yesterday's close
3-The difference between today's low and yesterday's close
Atr takes the average of these 14-day candlesticks after making their calculations and it predicts how high or low a candle can go and these give us support and resistance helps with points
If you have noticed a rise in your chart and have no idea how high it will go, you can use Atr profit and loss lines.
The red zone is the stop point, the blue zones are the snow zones.
Must be used with macd. macd is validator.
There is an increase in your chart, you opened the atr profit and loss lines upwards and if macd gives you an increase, it is recommended that you enter the trade at that time. It is recommended to increase your loss line 1 step in the direction of profit every 2 profit breaks on atr profit and loss lines.
ATR Nedir?
Bir mum barı ele alınarak şu 3 işlem hesaplanır:
1-Günün yükseği ile günün düşüğü farkı
2-Günün yükseği ile dünün kapanışının farkı
3-Günün düşüğü ile dünkü kapanışın farkı
ATR ise 14 günlük bu mum barlarının hesaplarını yaptıktan sonra ortalamasını alır ve bir mumum ne kadar yükselip düşebileceği konusunda tahmin verir ve bunlar bize destek ve direnç noktaları konusunda yardımcı olur
Eğer grafiğinizde bir yükseliş farketmişseniz ne kadar yükseleceği konusunda fikriniz yoksa Atr kar zarar çizgilerini kullanabilirsiniz.
Kırmızı bölge durdurma noktası,mavi bölgeler kar bölgeleridir.
Macd ile birlikte kullanılmalıdır.macd doğrulayıcıdır.
Grafiğinizde yükseliş var,atr kar zarar çizgilerini yukarı yönlü açtınız ve macd size yükseliş veriyorsa işte o sırada işleme girmeniz tavsiye edilir.atr kar zarar çizgilerinde her 2 kar kırılımında bir zarar çizginizi kar yönünde 1 kademe arttırmanız önerilir
Bitcoin Limited Growth ModelThe Bitcoin Limeted Growth is a model proposed by QuantMario that offers an alternative approach to estimating Bitcoin's price based on the Stock-to-Flow (S2F) ratio. This model takes into account the limitations of the traditional S2F model and introduces refinements to enhance its analysis.
The S2F model is commonly used to analyze Bitcoin's price by considering the scarcity of the asset, measured by the stock (existing supply) relative to the flow (new supply). However, the LGS-S2F Bitcoin Price Formula recognizes the need for improvements and presents an updated perspective on Bitcoin's price dynamics.
Invalidation of the Normal S2F Model:
The normal S2F model has faced criticisms and challenges. One of the limitations is its assumption of a linear relationship between the S2F ratio and Bitcoin's price, overlooking potential nonlinearities and other market dynamics. Additionally, the normal S2F model does not account for external influences, such as market sentiment, regulatory developments, and technological advancements, which can significantly impact Bitcoin's price.
Addressing the Issues:
The LGS-S2F Bitcoin Price Formula introduces refinements to address the limitations of the traditional S2F model. These refinements aim to provide a more comprehensive analysis of Bitcoin's price dynamics:
Nonlinearity: The LGS-S2F model recognizes that the relationship between the S2F ratio and Bitcoin's price may not be linear. It incorporates a logistic growth function that considers the diminishing returns of scarcity and the saturation of market demand.
Data Analysis: The LGS-S2F model employs statistical analysis and data-driven techniques to validate its predictions. It leverages historical data and econometric modeling to support its analysis of Bitcoin's price.
Utility:
The LGS-S2F Bitcoin Price Formula offers insights for traders and investors in the cryptocurrency market. By incorporating a more refined approach to analyzing Bitcoin's price, this model provides an alternative perspective. It allows market participants to consider various factors beyond the S2F ratio alone, potentially aiding in their decision-making processes.
Key Features:
Adjustable Coefficients
Sigma calculation methods: Normal or Stdev
Credit:
The LGS-S2F Bitcoin Price Formula was developed by QuantMario, who has contributed to the field of cryptocurrency analysis through their research and modeling efforts.

FalconRed 5 EMA Indicator (Powerofstocks)Improved version:
This indicator is based on Subhashish Pani's "Power of Stocks" 5 EMA Strategy, which aims to identify potential buying and selling opportunities in the market. The indicator plots the 5 EMA (Exponential Moving Average) and generates Buy/Sell signals with corresponding Target and Stoploss levels.
Subhashish Pani's 5 EMA Strategy is a straightforward approach. For intraday trading, a 5-minute timeframe is recommended for selling. In this strategy, you can choose to sell futures, sell calls, or buy puts as part of your selling strategy. The goal is to capture market tops by selling at the peak, anticipating a reversal for profitable trades. Although this strategy may result in frequent stop losses, they are typically small, while the minimum target should be at least three times the risk taken. By staying aligned with the trend, significant profits can be achieved. Subhashish Pani claims that this strategy has a 60% success rate.
Strategy for Selling (Short Future/Call/Stock or Buy Put):
1. When a candle completely closes above the 5 EMA (with no part of the candle touching the 5 EMA), it is considered an Alert Candle.
2. If the next candle is also entirely above the 5 EMA and does not break the low of the previous Alert Candle, ignore the previous Alert Candle and consider the new candle as the new Alert Candle.
3. Continue shifting the Alert Candle in this manner. However, when the next candle breaks the low of the Alert Candle, take a short trade (e.g., short futures, calls, stocks, or buy puts).
4. Set the stop loss above the high of the Alert Candle, and the minimum target should be 1:3 (at least three times the stop loss).
Strategy for Buying (Buy Future/Call/Stock or Sell Put):
1. When a candle completely closes below the 5 EMA (with no part of the candle touching the 5 EMA), it is considered an Alert Candle.
2. If the next candle is also entirely below the 5 EMA and does not break the high of the previous Alert Candle, ignore the previous Alert Candle and consider the new candle as the new Alert Candle.
3. Continue shifting the Alert Candle in this manner. However, when the next candle breaks the high of the Alert Candle, take a long trade (e.g., buy futures, calls, stocks, or sell puts).
4. Set the stop loss below the low of the Alert Candle, and the minimum target should be 1:3 (at least three times the stop loss).
Buy/Sell with Additional Conditions:
An additional condition is added to the buying/selling strategy:
1. Check if the closing price of the current candle is lower than the closing price of the Alert Candle for selling, or higher than the closing price of the Alert Candle for buying.
- This condition aims to filter out false moves, potentially preventing entering trades based on temporary fluctuations. However, it may cause you to miss out on significant moves, as you will enter trades after the candle closes, rather than at the breakout point.
Note: According to Subhashish Pani, the recommended timeframe for intraday buying is 15 minutes. However, this strategy can also be applied to positional/swing trading. If used on a monthly timeframe, it can be beneficial for long-term investing as well. The rules remain the same for all types of trades and timeframes.
If you need a deeper understanding of this strategy, you can search for "Subhashish Pani's (Power of Stocks) 5 EMA Strategy" on YouTube for further explanations.
Note: This strategy is not limited to intraday trading and can be applied to positional/swing

Trendilo (OPEN-SOURCE)The provided code is a custom indicator called "Trendilo" in TradingView. It helps traders identify trends in price data. The indicator calculates the percentage change of the chosen price source and applies smoothing to it. Then, it calculates the Arnaud Legoux Moving Average (ALMA) of the smoothed percentage change. The ALMA is compared to a root mean square (RMS) band, which represents the expected range of the ALMA values. Based on this comparison, the indicator determines whether the trend is up, down, or sideways. The indicator line is plotted in a color corresponding to the trend direction. The indicator also provides the option to fill the area between the indicator line and the RMS band. Additionally, users can choose to color the bars of the chart based on the trend direction. Overall, the "Trendilo" indicator helps traders visually identify trends and potential reversals in the price data.

Futures All List / Sell SignalAs of May 2023, there are more than 180 usdt perpetual coins on the binance futures exchange. These coins are included in the indicator in lists of 40. They are sorted instantly in the table from largest to smallest. The sorting style can be changed in the indicator settings. This indicator collects RSI and TSI values at desired values. The result has a maximum value of 600. A value of 600 signals that the price will decrease or remain stable for a certain period of time. Generally, a short can be expected from the closest point to 600. If 3 separate lists are selected by using 3 of these indicators, 120 coins can be analyzed at the same time. Available in all time zones. Examine it in a 3-minute timeframe. The line inside the indicator draws the instantaneous values of the relevant coin.
Point and Figure Vertical Price TargetsThis is the first ever Point and Figure vertical price target script. Just hover over any column and the price target will be shown on the upper left hand side where the script name is. It is for both upside and downside vertical targets. It is based on a 3 box reversal, but that can be changed within the code, and the box size can be changed within the code or within the settings.

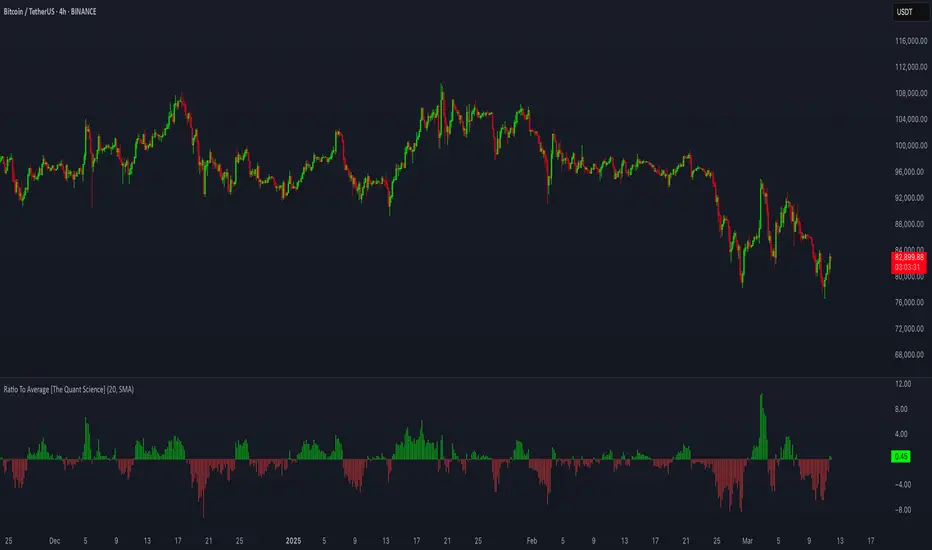
Ratio To Average - The Quant ScienceRatio To Average - The Quant Science is a quantitative indicator that calculates the percentage ratio of the market price in relation to a reference average. The indicator allows the calculation of the ratio using four different types of averages: SMA, EMA, WMA, and HMA. The ratio is represented by a series of histograms that highlight periods when the ratio is positive (in green) and periods when the ratio is negative (in red).
What is the Ratio to Average?
The Ratio to Average is a measure that tracks the price movements with one of its averages, calculating how much the price is above or below its own average, in percentage terms.
USER INTERFACE
Lenght: it adjusts the number of bars to include in the calculation of the average.
Moving Average: it allows you to choose the type of average to use.
Color Up/Color Down : it allows you to choose the color of the indicator for positive and negative ratios.
ReversalThe primary objective of this indicator is to discern candles that exhibit characteristics suggestive of potential market reversals through the application of candlestick analysis. Extensive observation across various assets and timeframes has revealed the existence of a recurrent reversal pattern. This pattern typically manifests as a sequence of one to three candles that abruptly diverge from the prevailing price action or trend, offering a distinctive signal indicating a potential reversal.
By leveraging the insights gained from this observation, the indicator aims to assist traders in identifying these noteworthy candle patterns that hold the potential to indicate significant market shifts.
The indicator operates as follows: initially, it identifies the lowest close (in the case of a bullish reversal) or the highest close (in the case of a bearish reversal) within a specified number of previous candles, as determined by user input (referred to as "Candle Lookback").
Next, the indicator examines whether the closing price surpasses the high of the previously identified lowest (bullish reversal) or highest (bearish reversal) closed candle within a designated number of candles, as specified by the user (referred to as "Confirm Within").
