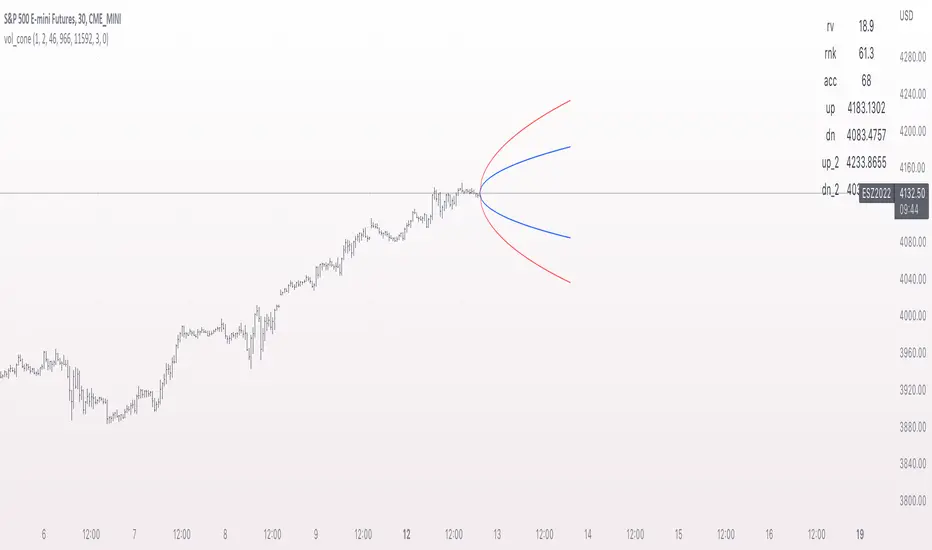
vol_coneDraws a volatility cone on the chart, using the contract's realized volatility (rv). The inputs are:
- window: the number of past periods to use for computing the realized volatility. VIX uses 30 calendar days, which is 21 trading days, so 21 is the default.
- stdevs: the number of standard deviations that the cone will cover.
- periods to project: the length of the volatility cone.
- periods per year: the number of periods in a year. for a daily chart, this is 252. for a thirty minute chart on a contract that trades 23 hours a day, this is 23 * 2 * 252 = 11592. for an accurate cone, this input must be set correctly, according to the chart's time frame.
- history: show the lagged projections. in other words, if the cone is set to project 21 periods in the future, the lines drawn show the top and bottom edges of the cone from 23 periods ago.
- rate: the current interest or discount rate. this is used to compute the forward price of the underlying contract. using an accurate forward price allows you to compare the realized volatility projection to the implied volatility projections derived from options prices.
Example settings for a 30 minute chart of a contract that trades 23 hours per day, with 1 standard deviation, a 21 day rv calculation, and half a day projected:
- stdevs: 1
- periods to project: 23
- window: 23 * 2 * 21 = 966
- periods per year: 23 * 2 * 252 = 11592
Additionally, a table is drawn in the upper right hand corner, with several values:
- rv: the contract's current realized volatility.
- rnk: the rv's percentile rank, compared to the rv values on past bars.
- acc: the proportion of times price settled inside, versus outside, the volatility cone, "periods to project" into the future. this should be around 65-70% for most contracts when the cone is set to 1 standard deviation.
- up: the upper bound of the cone for the projection period.
- dn: the lower bound of the cone for the projection period.
Limitations:
- pinescript only seems to be able to draw a limited distance into the future. If you choose too many "periods to project", the cone will start drawing vertically at some limit.
- the cone is not totally smooth owing to the facts a) it is comprised of a limited number of lines and b) each bar does not represent the same amount of time in pinescript, as some cross weekends, session gaps, etc.
Forecast
Polynomial Regression Bands w/ Extrapolation of Price [Loxx]Polynomial Regression Bands w/ Extrapolation of Price is a moving average built on Polynomial Regression. This indicator paints both a non-repainting moving average and also a projection forecast based on the Polynomial Regression. I've included 33 source types and 38 moving average types to smooth the price input before it's run through the Polynomial Regression algorithm. This indicator only paints X many bars back so as to increase on screen calculation speed. Make sure to read the tooltips to answer any questions you have.
What is Polynomial Regression?
In statistics, polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as an nth degree polynomial in x. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted E(y |x). Although polynomial regression fits a nonlinear model to the data, as a statistical estimation problem it is linear, in the sense that the regression function E(y | x) is linear in the unknown parameters that are estimated from the data. For this reason, polynomial regression is considered to be a special case of multiple linear regression .
Related indicators
Polynomial-Regression-Fitted Oscillator
Polynomial-Regression-Fitted RSI
PA-Adaptive Polynomial Regression Fitted Moving Average
Poly Cycle
Fourier Extrapolator of Price w/ Projection Forecast
Nearest Neighbor Extrapolation of Price [Loxx]I wasn't going to post this because I don't like how this calculates by puling in the Open price, but I'm posting it anyway. This does work in it's current form but there is a. better way to do this. I'll revisit this in the future.
Anyway...
The k-Nearest Neighbor algorithm (k-NN) searches for k past patterns (neighbors) that are most similar to the current pattern and computes the future prices based on weighted voting of those neighbors. This indicator finds only one nearest neighbor. So, in essence, it is a 1-NN algorithm. It uses the Pearson correlation coefficient between the current pattern and all past patterns as the measure of distance between them. Also, this version of the nearest neighbor indicator gives larger weights to most recent prices while searching for the closest pattern in the past. It uses a weighted correlation coefficient, whose weight decays linearly from newer to older prices within a price pattern.
This indicator also includes an error window that shows whether the calculation is valid. If it's green and says "Passed", then the calculation is valid, otherwise it'll show a red background and and error message.
Inputs
Npast - number of past bars in a pattern;
Nfut -number of future bars in a pattern (must be < Npast).
lastbar - How many bars back to start forecast? Useful to show past prediction accuracy
barsbark - This prevents Pine from trying to calculate on all past bars
Related indicators
Hodrick-Prescott Extrapolation of Price
Itakura-Saito Autoregressive Extrapolation of Price
Helme-Nikias Weighted Burg AR-SE Extra. of Price
Weighted Burg AR Spectral Estimate Extrapolation of Price
Levinson-Durbin Autocorrelation Extrapolation of Price
Fourier Extrapolator of Price w/ Projection Forecast
Hodrick-Prescott Extrapolation of Price [Loxx]Hodrick-Prescott Extrapolation of Price is a Hodrick-Prescott filter used to extrapolate price.
The distinctive feature of the Hodrick-Prescott filter is that it does not delay. It is calculated by minimizing the objective function.
F = Sum((y(i) - x(i))^2,i=0..n-1) + lambda*Sum((y(i+1)+y(i-1)-2*y(i))^2,i=1..n-2)
where x() - prices, y() - filter values.
If the Hodrick-Prescott filter sees the future, then what future values does it suggest? To answer this question, we should find the digital low-frequency filter with the frequency parameter similar to the Hodrick-Prescott filter's one but with the values calculated directly using the past values of the "twin filter" itself, i.e.
y(i) = Sum(a(k)*x(i-k),k=0..nx-1) - FIR filter
or
y(i) = Sum(a(k)*x(i-k),k=0..nx-1) + Sum(b(k)*y(i-k),k=1..ny) - IIR filter
It is better to select the "twin filter" having the frequency-independent delay Тdel (constant group delay). IIR filters are not suitable. For FIR filters, the condition for a frequency-independent delay is as follows:
a(i) = +/-a(nx-1-i), i = 0..nx-1
The simplest FIR filter with constant delay is Simple Moving Average (SMA):
y(i) = Sum(x(i-k),k=0..nx-1)/nx
In case nx is an odd number, Тdel = (nx-1)/2. If we shift the values of SMA filter to the past by the amount of bars equal to Тdel, SMA values coincide with the Hodrick-Prescott filter ones. The exact math cannot be achieved due to the significant differences in the frequency parameters of the two filters.
To achieve the closest match between the filter values, I recommend their channel widths to be similar (for example, -6dB). The Hodrick-Prescott filter's channel width of -6dB is calculated as follows:
wc = 2*arcsin(0.5/lambda^0.25).
The channel width of -6dB for the SMA filter is calculated by numerical computing via the following equation:
|H(w)| = sin(nx*wc/2)/sin(wc/2)/nx = 0.5
Prediction algorithms:
The indicator features the two prediction methods:
Metod 1:
1. Set SMA length to 3 and shift it to the past by 1 bar. With such a length, the shifted SMA does not exist only for the last bar (Bar = 0), since it needs the value of the next future price Close(-1).
2. Calculate SMA filer's channel width. Equal it to the Hodrick-Prescott filter's one. Find lambda.
3. Calculate Hodrick-Prescott filter value at the last bar HP(0) and assume that SMA(0) with unknown Close(-1) gives the same value.
4. Find Close(-1) = 3*HP(0) - Close(0) - Close(1)
5. Increase the length of SMA to 5. Repeat all calculations and find Close(-2) = 5*HP(0) - Close(-1) - Close(0) - Close(1) - Close(2). Continue till the specified amount of future FutBars prices is calculated.
Method 2:
1. Set SMA length equal to 2*FutBars+1 and shift SMA to the past by FutBars
2. Calculate SMA filer's channel width. Equal it to the Hodrick-Prescott filter's one. Find lambda.
3. Calculate Hodrick-Prescott filter values at the last FutBars and assume that SMA behaves similarly when new prices appear.
4. Find Close(-1) = (2*FutBars+1)*HP(FutBars-1) - Sum(Close(i),i=0..2*FutBars-1), Close(-2) = (2*FutBars+1)*HP(FutBars-2) - Sum(Close(i),i=-1..2*FutBars-2), etc.
The indicator features the following inputs:
Method - prediction method
Last Bar - number of the last bar to check predictions on the existing prices (LastBar >= 0)
Past Bars - amount of previous bars the Hodrick-Prescott filter is calculated for (the more, the better, or at least PastBars>2*FutBars)
Future Bars - amount of predicted future values
The second method is more accurate but often has large spikes of the first predicted price. For our purposes here, this price has been filtered from being displayed in the chart. This is why method two starts its prediction 2 bars later than method 1. The described prediction method can be improved by searching for the FIR filter with the frequency parameter closer to the Hodrick-Prescott filter. For example, you may try Hanning, Blackman, Kaiser, and other filters with constant delay instead of SMA.
Related indicators
Itakura-Saito Autoregressive Extrapolation of Price
Helme-Nikias Weighted Burg AR-SE Extra. of Price
Weighted Burg AR Spectral Estimate Extrapolation of Price
Levinson-Durbin Autocorrelation Extrapolation of Price
Fourier Extrapolator of Price w/ Projection Forecast
Modified Covariance Autoregressive Estimator of Price [Loxx]What is the Modified Covariance AR Estimator?
The Modified Covariance AR Estimator uses the modified covariance method to fit an autoregressive (AR) model to the input data. This method minimizes the forward and backward prediction errors in the least squares sense. The input is a frame of consecutive time samples, which is assumed to be the output of an AR system driven by white noise. The block computes the normalized estimate of the AR system parameters, A(z), independently for each successive input.
Characteristics of Modified Covariance AR Estimator
Minimizes the forward prediction error in the least squares sense
Minimizes the forward and backward prediction errors in the least squares sense
High resolution for short data records
Able to extract frequencies from data consisting of p or more pure sinusoids
Does not suffer spectral line-splitting
May produce unstable models
Peak locations slightly dependent on initial phase
Minor frequency bias for estimates of sinusoids in noise
Order must be less than or equal to 2/3 the input frame size
Purpose
This indicator calculates a prediction of price. This will NOT work on all tickers. To see whether this works on a ticker for the settings you have chosen, you must check the label message on the lower right of the chart. The label will show either a pass or fail. If it passes, then it's green, if it fails, it's red. The reason for this is because the Modified Covariance method produce unstable models
H(z)= G / A(z) = G / (1+. a(2)z −1 +…+a(p+1)z)
You specify the order, "ip", of the all-pole model in the Estimation order parameter. To guarantee a valid output, you must set the Estimation order parameter to be less than or equal to two thirds the input vector length.
The output port labeled "a" outputs the normalized estimate of the AR model coefficients in descending powers of z.
The implementation of the Modified Covariance AR Estimator in this indicator is the fast algorithm for the solution of the modified covariance least squares normal equations.
Inputs
x - Array of complex data samples X(1) through X(N)
ip - Order of linear prediction model (integer)
Notable local variables
v - Real linear prediction variance at order IP
Outputs
a - Array of complex linear prediction coefficients
stop - value at time of exit, with error message
false - for normal exit (no numerical ill-conditioning)
true - if v is not a positive value
true - if delta and gamma do not lie in the range 0 to 1
true - if v is not a positive value
true - if delta and gamma do not lie in the range 0 to 1
errormessage - an error message based on "stop" parameter; this message will be displayed in the lower righthand corner of the chart. If you see a green "passed" then the analysis is valid, otherwise the test failed.
Indicator inputs
LastBar = bars backward from current bar to test estimate reliability
PastBars = how many bars are we going to analyze
LPOrder = Order of Linear Prediction, and for Modified Covariance AR method, this must be less than or equal to 2/3 the input frame size, so this number has a max value of 0.67
FutBars = how many bars you'd like to show in the future. This algorithm will either accept or reject your value input here and then project forward
Further reading
Spectrum Analysis-A Modern Perspective 1380 PROCEEDINGS OF THE IEEE, VOL. 69, NO. 11, NOVEMBER 1981
Related indicators
Levinson-Durbin Autocorrelation Extrapolation of Price
Weighted Burg AR Spectral Estimate Extrapolation of Price
Helme-Nikias Weighted Burg AR-SE Extra. of Price
Itakura-Saito Autoregressive Extrapolation of Price
Modified Covariance Autoregressive Estimator of Price

Helme-Nikias Weighted Burg AR-SE Extra. of Price [Loxx]Helme-Nikias Weighted Burg AR-SE Extra. of Price is an indicator that uses an autoregressive spectral estimation called the Weighted Burg Algorithm, but unlike the usual WB algo, this one uses Helme-Nikias weighting. This method is commonly used in speech modeling and speech prediction engines. This is a linear method of forecasting data. You'll notice that this method uses a different weighting calculation vs Weighted Burg method. This new weighting is the following:
w = math.pow(array.get(x, i - 1), 2), the squared lag of the source parameter
and
w += math.pow(array.get(x, i), 2), the sum of the squared source parameter
This take place of the rectangular, hamming and parabolic weighting used in the Weighted Burg method
Also, this method includes Levinson–Durbin algorithm. as was already discussed previously in the following indicator:
Levinson-Durbin Autocorrelation Extrapolation of Price
What is Helme-Nikias Weighted Burg Autoregressive Spectral Estimate Extrapolation of price?
In this paper a new stable modification of the weighted Burg technique for autoregressive (AR) spectral estimation is introduced based on data-adaptive weights that are proportional to the common power of the forward and backward AR process realizations. It is shown that AR spectra of short length sinusoidal signals generated by the new approach do not exhibit phase dependence or line-splitting. Further, it is demonstrated that improvements in resolution may be so obtained relative to other weighted Burg algorithms. The method suggested here is shown to resolve two closely-spaced peaks of dynamic range 24 dB whereas the modified Burg schemes employing rectangular, Hamming or "optimum" parabolic windows fail.
Data inputs
Source Settings: -Loxx's Expanded Source Types. You typically use "open" since open has already closed on the current active bar
LastBar - bar where to start the prediction
PastBars - how many bars back to model
LPOrder - order of linear prediction model; 0 to 1
FutBars - how many bars you want to forward predict
Things to know
Normally, a simple moving average is calculated on source data. I've expanded this to 38 different averaging methods using Loxx's Moving Avreages.
This indicator repaints
Further reading
A high-resolution modified Burg algorithm for spectral estimation
Related Indicators
Levinson-Durbin Autocorrelation Extrapolation of Price
Weighted Burg AR Spectral Estimate Extrapolation of Price

Weighted Burg AR Spectral Estimate Extrapolation of Price [Loxx]Weighted Burg AR Spectral Estimate Extrapolation of Price is an indicator that uses an autoregressive spectral estimation called the Weighted Burg Algorithm. This method is commonly used in speech modeling and speech prediction engines. This method also includes Levinson–Durbin algorithm. As was already discussed previously in the following indicator:
Levinson-Durbin Autocorrelation Extrapolation of Price
What is Levinson recursion or Levinson–Durbin recursion?
In many applications, the duration of an uninterrupted measurement of a time series is limited. However, it is often possible to obtain several separate segments of data. The estimation of an autoregressive model from this type of data is discussed. A straightforward approach is to take the average of models estimated from each segment separately. In this way, the variance of the estimated parameters is reduced. However, averaging does not reduce the bias in the estimate. With the Burg algorithm for segments, both the variance and the bias in the estimated parameters are reduced by fitting a single model to all segments simultaneously. As a result, the model estimated with the Burg algorithm for segments is more accurate than models obtained with averaging. The new weighted Burg algorithm for segments allows combining segments of different amplitudes.
The Burg algorithm estimates the AR parameters by determining reflection coefficients that minimize the sum of for-ward and backward residuals. The extension of the algorithm to segments is that the reflection coefficients are estimated by minimizing the sum of forward and backward residuals of all segments taken together. This means a single model is fitted to all segments in one time. This concept is also used for prediction error methods in system identification, where the input to the system is known, like in ARX modeling
Data inputs
Source Settings: -Loxx's Expanded Source Types. You typically use "open" since open has already closed on the current active bar
LastBar - bar where to start the prediction
PastBars - how many bars back to model
LPOrder - order of linear prediction model; 0 to 1
FutBars - how many bars you want to forward predict
BurgWin - weighing function index, rectangular, hamming, or parabolic
Things to know
Normally, a simple moving average is calculated on source data. I've expanded this to 38 different averaging methods using Loxx's Moving Avreages.
This indicator repaints
Included
Bar color muting
Further reading
Performance of the weighted burg methods of ar spectral estimation for pitch-synchronous analysis of voiced speech
The Burg algorithm for segments
Techniques for the Enhancement of Linear Predictive Speech Coding in Adverse Conditions
Related Indicators
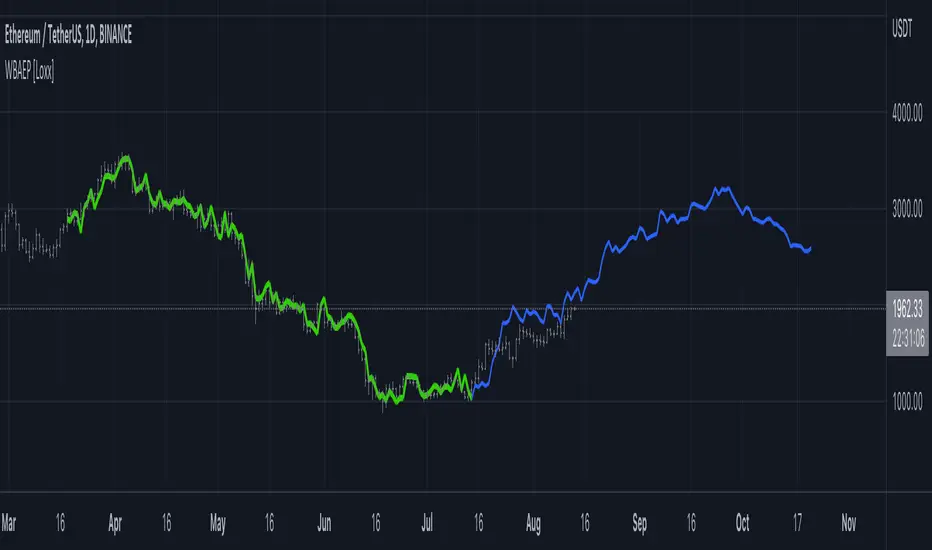
Levinson-Durbin Autocorrelation Extrapolation of Price [Loxx]Levinson-Durbin Autocorrelation Extrapolation of Price is an indicator that uses the Levinson recursion or Levinson–Durbin recursion algorithm to predict price moves. This method is commonly used in speech modeling and prediction engines.
What is Levinson recursion or Levinson–Durbin recursion?
Is a linear algebra prediction analysis that is performed once per bar using the autocorrelation method with a within a specified asymmetric window. The autocorrelation coefficients of the window are computed and converted to LP coefficients using the Levinson algorithm. The LP coefficients are then transformed to line spectrum pairs for quantization and interpolation. The interpolated quantized and unquantized filters are converted back to the LP filter coefficients to construct the synthesis and weighting filters for each bar.
Data inputs
Source Settings: -Loxx's Expanded Source Types. You typically use "open" since open has already closed on the current active bar
LastBar - bar where to start the prediction
PastBars - how many bars back to model
LPOrder - order of linear prediction model; 0 to 1
FutBars - how many bars you want to forward predict
Things to know
Normally, a simple moving average is caculated on source data. I've expanded this to 38 different averaging methods using Loxx's Moving Avreages.
This indicator repaints
Included
Bar color muting
Further reading
Implementing the Levinson-Durbin Algorithm on the StarCore™ SC140/SC1400 Cores
LevinsonDurbin_G729 Algorithm, Calculates LP coefficients from the autocorrelation coefficients. Intel® Integrated Performance Primitives for Intel® Architecture Reference Manual
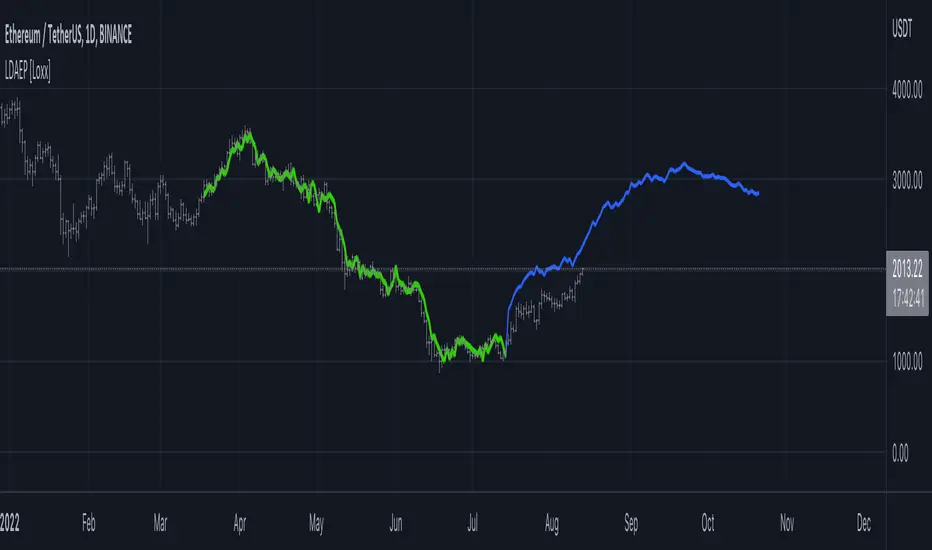
Fourier Extrapolation of Variety Moving Averages [Loxx]Fourier Extrapolation of Variety Moving Averages is a Fourier Extrapolation (forecasting) indicator that has for inputs 38 different types of moving averages along with 33 different types of sources for those moving averages. This is a forecasting indicator of the selected moving average of the selected price of the underlying ticker. This indicator will repaint, so past signals are only as valid as the current bar. This indicator allows for up to 1500 bars between past bars and future projection bars. If the indicator won't load on your chart. check the error message for details on how to fix that, but you must ensure that past bars + futures bars is equal to or less than 1500.
Fourier Extrapolation using the Quinn-Fernandes algorithm is one of several (5-10) methods of signals forecasting that I'l be demonstrating in Pine Script.
What is Fourier Extrapolation?
This indicator uses a multi-harmonic (or multi-tone) trigonometric model of a price series xi, i=1..n, is given by:
xi = m + Sum( a*Cos(w*i) + b*Sin(w*i), h=1..H )
Where:
xi - past price at i-th bar, total n past prices;
m - bias;
a and b - scaling coefficients of harmonics;
w - frequency of a harmonic ;
h - harmonic number;
H - total number of fitted harmonics.
Fitting this model means finding m, a, b, and w that make the modeled values to be close to real values. Finding the harmonic frequencies w is the most difficult part of fitting a trigonometric model. In the case of a Fourier series, these frequencies are set at 2*pi*h/n. But, the Fourier series extrapolation means simply repeating the n past prices into the future.
This indicator uses the Quinn-Fernandes algorithm to find the harmonic frequencies. It fits harmonics of the trigonometric series one by one until the specified total number of harmonics H is reached. After fitting a new harmonic , the coded algorithm computes the residue between the updated model and the real values and fits a new harmonic to the residue.
see here: A Fast Efficient Technique for the Estimation of Frequency , B. G. Quinn and J. M. Fernandes, Biometrika, Vol. 78, No. 3 (Sep., 1991), pp . 489-497 (9 pages) Published By: Oxford University Press
The indicator has the following input parameters:
src - input source
npast - number of past bars, to which trigonometric series is fitted;
Nfut - number of predicted future bars;
nharm - total number of harmonics in model;
frqtol - tolerance of frequency calculations.
Included:
Loxx's Expanded Source Types
Loxx's Moving Averages
Other indicators using this same method
Fourier Extrapolator of Variety RSI w/ Bollinger Bands
Fourier Extrapolator of Price w/ Projection Forecast
Fourier Extrapolator of Price
Loxx's Moving Averages: Detailed explanation of moving averages inside this indicator
Loxx's Expanded Source Types: Detailed explanation of source types used in this indicator

Fourier Extrapolator of Variety RSI w/ Bollinger Bands [Loxx]Fourier Extrapolator of Variety RSI w/ Bollinger Bands is an RSI indicator that shows the original RSI, the Fourier Extrapolation of RSI in the past, and then the projection of the Fourier Extrapolated RSI for the future. This indicator has 8 different types of RSI including a new type of RSI called T3 RSI. The purpose of this indicator is to demonstrate the Fourier Extrapolation method used to model past data and to predict future price movements. This indicator will repaint. If you wish to use this for trading, then make sure to take a screenshot of the indicator when you enter the trade to save your analysis. This is the first of a series of forecasting indicators that can be used in trading. Due to how this indicator draws on the screen, you must choose values of npast and nfut that are equal to or less than 200. this is due to restrictions by TradingView and Pine Script in only allowing 500 lines on the screen at a time. Enjoy!
What is Fourier Extrapolation?
This indicator uses a multi-harmonic (or multi-tone) trigonometric model of a price series xi, i=1..n, is given by:
xi = m + Sum( a*Cos(w*i) + b*Sin(w*i), h=1..H )
Where:
xi - past price at i-th bar, total n past prices;
m - bias;
a and b - scaling coefficients of harmonics;
w - frequency of a harmonic ;
h - harmonic number;
H - total number of fitted harmonics.
Fitting this model means finding m, a, b, and w that make the modeled values to be close to real values. Finding the harmonic frequencies w is the most difficult part of fitting a trigonometric model. In the case of a Fourier series, these frequencies are set at 2*pi*h/n. But, the Fourier series extrapolation means simply repeating the n past prices into the future.
This indicator uses the Quinn-Fernandes algorithm to find the harmonic frequencies. It fits harmonics of the trigonometric series one by one until the specified total number of harmonics H is reached. After fitting a new harmonic , the coded algorithm computes the residue between the updated model and the real values and fits a new harmonic to the residue.
see here: A Fast Efficient Technique for the Estimation of Frequency , B. G. Quinn and J. M. Fernandes, Biometrika, Vol. 78, No. 3 (Sep., 1991), pp . 489-497 (9 pages) Published By: Oxford University Press
The indicator has the following input parameters:
src - input source
npast - number of past bars, to which trigonometric series is fitted;
Nfut - number of predicted future bars;
nharm - total number of harmonics in model;
frqtol - tolerance of frequency calculations.
Included:
Loxx's Expanded Source Types
Loxx's Variety RSI
Other indicators using this same method
Fourier Extrapolator of Price w/ Projection Forecast
Fourier Extrapolator of Price

vol_boxA simple script to draw a realized volatility forecast, in the form of a box. The script calculates realized volatility using the EWMA method, using a number of periods of your choosing. Using the "periods per year", you can adjust the script to work on any time frame. For example, if you are using an hourly chart with bitcoin, there are 24 periods * 365 = 8760 periods per year. This setting is essential for the realized volatility figure to be accurate as an annualized figure, like VIX.
By default, the settings are set to mimic CBOE volatility indices. That is, 252 days per year, and 20 period window on the daily timeframe (simulating a 30 trading day period).
Inside the box are three figures:
1. The current realized volatility.
2. The rank. E.g. "10%" means the current realized volatility is less than 90% of realized volatility measures.
3. The "accuracy": how often price has closed within the box, historically.
Inputs:
stdevs: the number of standard deviations for the box
periods to project: the number of periods to forecast
window: the number of periods for calculating realized volatility
periods per year: the number of periods in one year (e.g. 252 for the "D" timeframe)

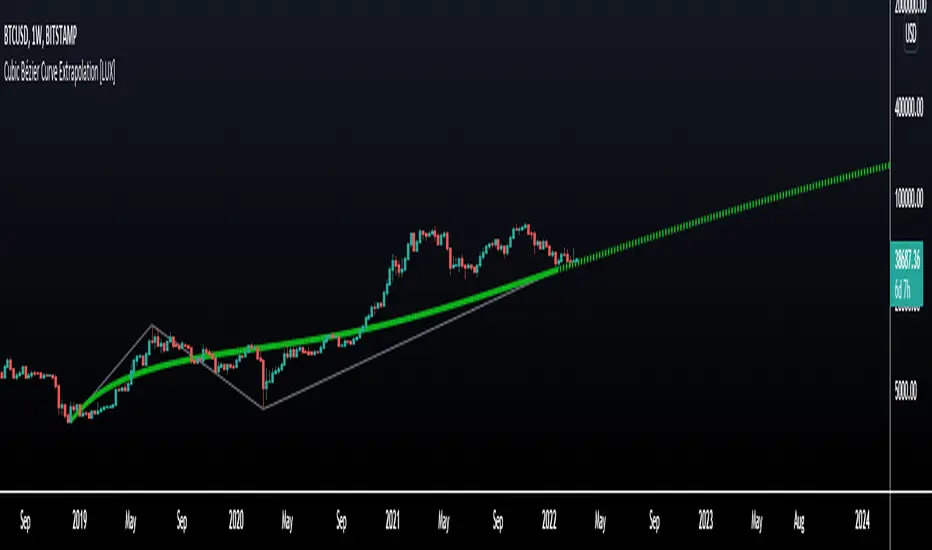
Cubic Bézier Curve Extrapolation [LuxAlgo]The following script allows for the extrapolation of a Cubic Bézier Curve fit using custom set control points and can be used as a drawing tool allowing users to estimate underlying price trends or to forecast future price trends.
Settings
Extrapolation Length: Number of extrapolated observations.
Source: Source input of the script.
Style
Width: Bézier curve line width.
Colors: The curve is colored based on the direction it's taking, the first color is used when the curve is rising, and the second when it is declining.
The other settings determine the locations of the control points. The user does not need to change them from the settings, instead only requiring adjusting their location on the chart like with a regular drawing tool. Setting these control points is required when adding the indicator to your chart.
Usage
Bézier curves are widely used in a lot of scientific and artistic fields. Using them for technical analysis can be interesting due to their extrapolation capabilities as well as their ease of calculation.
A cubic Bézier curve is based on four control points. Maxima/Minimas can be used as control points or the user can set them such that part of the extrapolated observation better fits the most recent price observations.
A possible disadvantage of Bézier curves is that obtaining a good fit with the data is not their primary goal. Rational Bézier curves can be used if obtaining a good fit is the primary user goal.
Details
At their core, Bézier curves are obtained from nested linear interpolation between each control point and the resulting linearly interpolated results. The Bézier curve point located at the first control point P0 and the last curve point located at the last control point Pn are equal to their respective control points. However, this script does not make use of this approach, instead using a more explicit form.
As mentioned previously, the complexity of a Bézier curve can be determined by its number of control points which is related to the Bézier curve degree (number of control points - 1). Instead of using nested linear interpolations to describe Bézier curves, one can describe them as a polynomial of a degree equal to the degree of the wanted Bézier curve.
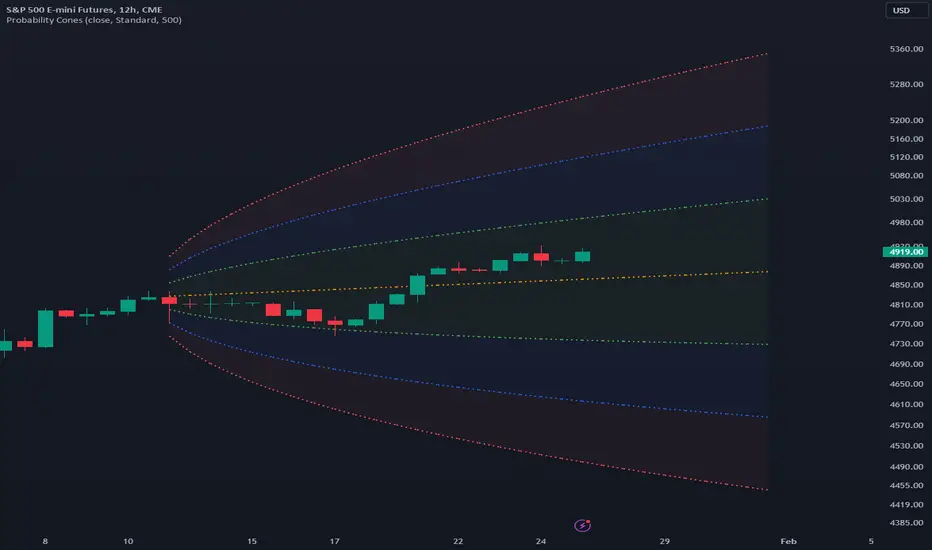
Probability ConesA probability cone is an indicator that forecasts a statistical distribution from a set point in time into the future.
Features
Forecast a Standard or Laplace distribution.
Change the how many bars the cones will lookback and sample in their calculations.
Set how many bars to forecast the cones.
Let the cones follow price from a set number of bars back.
Anchor the cones and they will not update from their last location.
Show or hide any set of cones.
Change the deviation used of any cone's upper or lower line.
Change any line's color, style, or width.
Change or toggle the fill colors between any two cone lines.
Basic Interpretations
First, there is an assumption that the distribution starting from the cone's origin, based on the number of historical bars sampled, is likely to represent the distribution of future price.
Price typically hangs around the mean.
About 68% of price stays within the first deviation cones.
About 95% of price stays within the second deviation cones.
About 99.7% of price stays within the third deviation cones.
When price is between the first and second deviation cones, there is a higher probability for a reversal.
However, strong momentum while above or below the first deviation can indicate a trend where price maintains itself past the first deviation. For this reason it's recommended to use a momentum indicator alongside the cones.
There is no mean reversion assumption when price deviates. Price can continue to stay deviated.
It's recommended that the cones are placed at the beginning of calendar periods. Like the month, week, or day.
Be mindful when using the cones on various timeframes. As the lookback setting, which selects the number of bars back to load from the cone's origin, will load the number of bars back based on the current timeframe.
Second Deviation Strategy
How to react when price goes beyond the second deviation is contingent on your trading position.
If you are holding a losing trade and price has moved past the second deviation, it could be time to stop trading and exit.
If you are holding a winning trade and price has moved past the second deviation, it would be best to look at exit strategies to capitalize on the outperformance.
If price has moved beyond the second deviation and you hold no position, then do not open any new trades.
TargetPredictor 5MA ForecastThis indicator consists of five moving averages. 7, 20, 50, 100 and 200.
Moving averages usually represent dynamic supports or resistances and are very useful in trading.
In addition, this indicator predicts where these moving averages will be located three candlesticks ahead and predicts their projected movement.
I hope you enjoy it and enjoy using it.

Universal logarithmic growth curves, with support and resistanceLogarithmic regression is used to model data where growth or decay accelerates rapidly at first and then slows over time. This model is for the long term series data (such as 10 years time span).
The user can consider entering the market when the price below 25% or 5% confidence and consider take profit when the price goes above 75% or 95% confidence line.
This script is:
- Designed to be usable in all tickers. (not only for bitcoin now!)
- Logarithmic regression and shows support-resistance level
- Shape of lines are all linear adjustable
- Height difference of levels and zones are customizable
- Support and resistance levels are highlighted
Input panel:
- Steps of drawing: Won't change it unless there are display problems.
- Resistance, support, other level color: self-explanatory.
- Stdev multipliers: A constant variable to adjust regression boundaries.
- Fib level N: Base on the relative position of top line and base line. If you don't want all fib levels, you might set all fib levels = 0.5.
- Linear lift up: vertically lift up the whole set of lines. By linear multiplication.
- Curvature constant: It is the base value of the exponential transform before converting it back to the chart and plotting it. A bigger base value will make a more upward curvy line.
FAQ:
Q: How to use it?
A: Click "Fx" in your chart then search this script to get it into your chart. Then right click the price axis, then select "Logarithmic" scale to show the curves probably.
Q: Why release this script?
A: - This script is intended to to fix the current issues of bitcoins growth curve script, and to provide a better version of the logarithmic curve, which is not only for bitcoin , but for all kinds of tickers.
- In the public library there is a hardcoded logarithmic growth curve by @quantadelic . But unfortunately that curve was hardcoded by his manual inputs, which makes the curve stop updating its value since 2019 the date he publish that code. Many users of that script love using it but they realize it was stop updating, many users out there based on @quantadelic version of "bitcoin logarithmic growth curves" and they tried their best to update the coordinates with their own hardcode input values. Eventually, a lot of redundant hardcoded "Bitcoin growth curve" scripts was born in the public library. Which is not a good thing.
Q: What about looking at the regression result with a log scale price axis?
A: You can use this script that I published in a year ago. This script display the result in a log scale price axis.

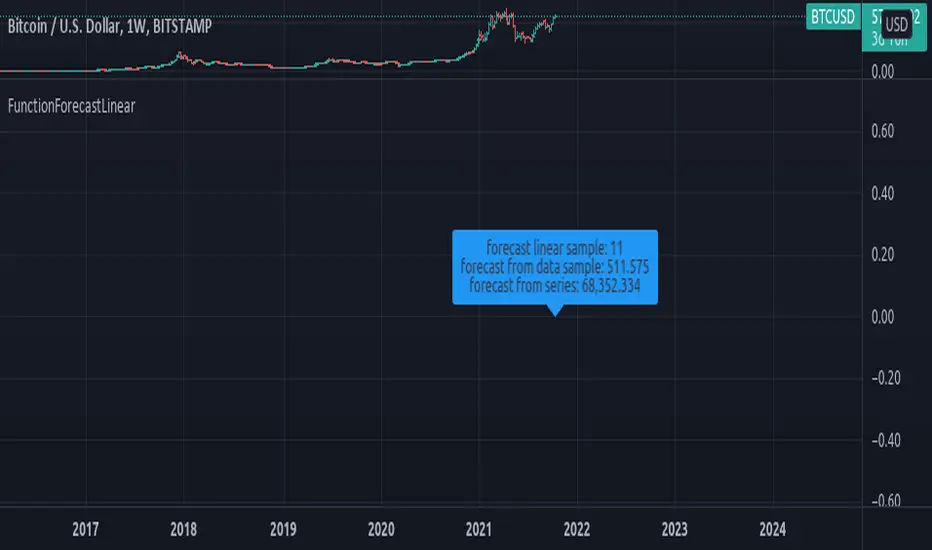
FunctionForecastLinearLibrary "FunctionForecastLinear"
Method for linear Forecast, same as found in excel and other sheet packages.
forecast(sample_x, sample_y, target_x) linear forecast method.
Parameters:
sample_x : float array, sample data X value.
sample_y : float array, sample data Y value.
target_x : float, target X to get Y forecast value.
Returns: float
The Echo Forecast [LuxAlgo]This indicator uses a simple time series forecasting method derived from the similarity between recent prices and similar/dissimilar historical prices. We named this method "ECHO".
This method originally assumes that future prices can be estimated from a historical series of observations that are most similar to the most recent price variations. This similarity is quantified using the correlation coefficient. Such an assumption can prove to be relatively effective with the forecasting of a periodic time series. We later introduced the ability to select dissimilar series of observations for further experimentation.
This forecasting technique is closely inspired by the analogue method introduced by Lorenz for the prediction of atmospheric data.
1. Settings
Evaluation Window: Window size used for finding historical observations similar/dissimilar to recent observations. The total evaluation window is equal to "Forecast Window" + "Evaluation Window"
Forecast Window: Determines the forecasting horizon.
Forecast Mode: Determines whether to choose historical series similar or dissimilar to the recent price observations.
Forecast Construction: Determines how the forecast is constructed. See "Usage" below.
Src: Source input of the forecast
Other style settings are self-explanatory.
2. Usage
This tool can be used to forecast future trends but also to indicate which historical variations have the highest degree of similarity/dissimilarity between the observations in the orange zone.
The forecasting window determines the prices segment (in orange) to be used as a reference for the search of the most similar/dissimilar historical price segment (in green) within the gray area.
Most forecasting techniques highly benefit from a detrended series. Due to the nature of this method, we highly recommend applying it to a detrended and periodic series.
You can see above the method is applied on a smooth periodic oscillator and a momentum oscillator.
The construction of the forecast is made from the price changes obtained in the green area, denoted as w(t) . Using the "Cumulative" options we construct the forecast from the cumulative sum of w(t) . Finally, we add the most recent price value to this cumulated series.
Using the "Mean" options will add the series w(t) with the mean of the prices within the orange segment.
Finally the "Linreg" will add the series w(t) to an extrapolated linear regression fit to the prices within the orange segment.

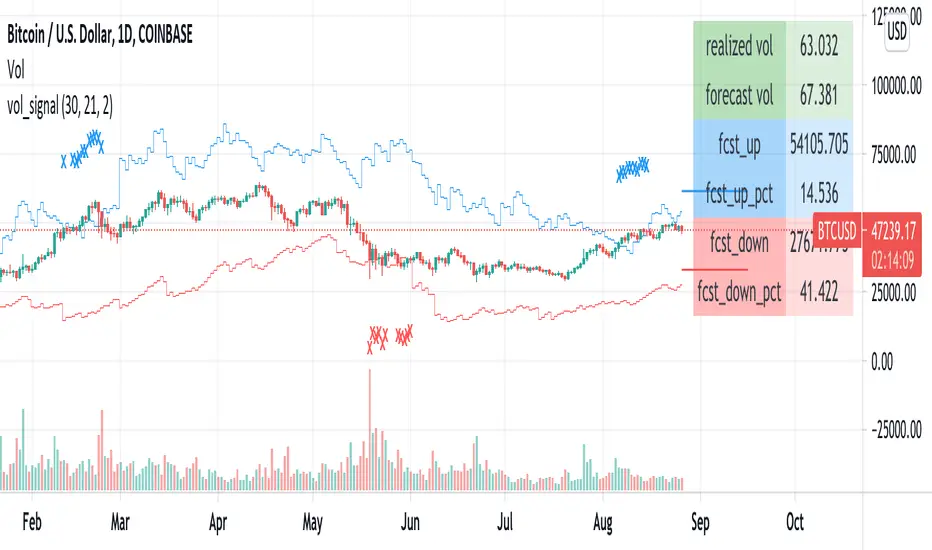
vol_signalNote: This description is copied from the script comments. Please refer to the comments and release notes for updated information, as I am unable to edit and update this description.
----------
USAGE
This script gives signals based on a volatility forecast, e.g. for a stop
loss. It is a simplified version of my other script "trend_vol_forecast", which incorporates a trend following system and measures performance. The "X" labels indicate when the price touches (exceeds) a forecast. The signal occurs when price crosses "fcst_up" or "fcst_down".
There are only three parameters:
- volatility window: this is the number of periods (bars) used in the
historical volatility calculation. smaller number = reacts more
quickly to changes, but is a "noisier" signal.
- forecast periods: the number of periods for projecting a volatility
forecast. for example, "21" on a daily chart means the plots will
show the forecast from 21 days ago.
- forecast stdev: the number of standard deviations in the forecast.
for example, "2" means that price is expected to remain within
the forecast plot ~95% of the time. A higher number produces a
wider forecast.
The output table shows:
- realized vol: the volatility over the previous N periods, where N =
"volatility window".
- forecast vol: the realized volatility from N periods ago, where N =
"forecast periods"
- up/down fcst (level): the price level of the forecast for the next
N bars, where N = "forecast periods".
- up/down fcst (%): the difference between the current and forecast
price, expressed as a whole number percentage.
The plots show:
- blue/red plot: the upper/lower forecast from "forecast periods" ago.
- blue/red line: the upper/lower forecast for the next
"forecast periods".
- red/blue labels: an "X" where the price touched the forecast from
"forecast periods" ago.
+ NOTE: pinescript only draws a limited number of labels.
They will not appear very far into the past.
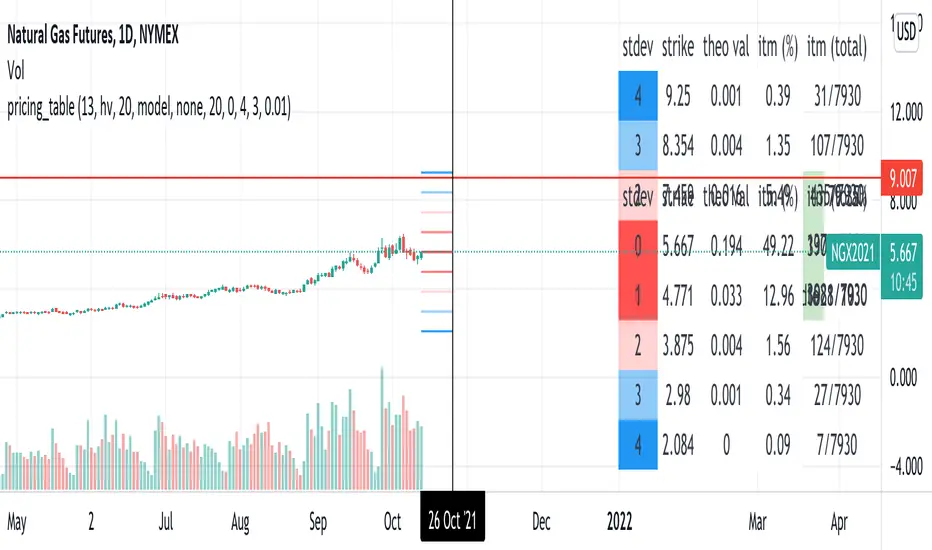
pricing_tableThis script helps you evaluate the fair value of an option. It poses the question "if I bought or sold an option under these circumstances in the past, would it have expired in the money, or worthless? What would be its expected value, at expiration, if I opened a position at N standard deviations, given the volatility forecast, with M days to expiration at the close of every previous trading day?"
The default (and only) "hv" volatility forecast is based on the assumption that today's volatility will hold for the next M days.
To use this script, only one step is mandatory. You must first select days to expiration. The script will not do anything until this value is changed from the default (-1). These should be CALENDAR days. The script will convert to these to business days for forecasting and valuation, as trading in most contracts occurs over ~250 business days per year.
Adjust any other variables as desired:
model: the volatility forecasting model
window: the number of periods for a lagged model (e.g. hv)
filter: a filter to remove forecasts from the sample
filter type: "none" (do not use the filter), "less than" (keep forecasts when filter < volatility), "greater than" (keep forecasts when filter > volatility)
filter value: a whole number percentage. see example below
discount rate: to discount the expected value to present value
precision: number of decimals in output
trim outliers: omit upper N % of (generally itm) contracts
The theoretical values are based on history. For example, suppose days to expiration is 30. On every bar, the 30 days ago N deviation forecast value is compared to the present price. If the price is above the forecast value, the contract has expired in the money; otherwise, it has expired worthless. The theoretical value is the average of every such sample. The itm probabilities are calculated the same way.
The default (and only) volatility model is a 20 period EWMA derived historical (realized) volatility. Feel free to extend the script by adding your own.
The filter parameters can be used to remove some forecasts from the sample.
Example A:
filter:
filter type: none
filter value:
Default: the filter is not used; all forecasts are included in the the sample.
Example B:
filter: model
filter type: less than
filter value: 50
If the model is "hv", this will remove all forecasts when the historical volatility is greater than fifty.
Example C:
filter: rank
filter type: greater than
filter value: 75
If the model volatility is in the top 25% of the previous year's range, the forecast will be included in the sample apart from "model" there are some common volatility indexes to choose from, such as Nasdaq (VXN), crude oil (OVX), emerging markets (VXFXI), S&P; (VIX) etc.
Refer to the middle-right table to see the current forecast value, its rank among the last 252 days, and the number of business days until
expiration.
NOTE: This script is meant for the daily chart only.
Pivot High/Low Analysis & Forecast [LuxAlgo]Returns pivot points high/low alongside the percentage change between one pivot and the previous one (Δ%) and the distance between the same type of pivots in bars (Δt). The trailing mean for each of these metrics is returned on a dashboard on the chart. The indicator also returns an estimate of the future time position of the pivot points.
This indicator by its very nature is not real-time and is meant for descriptive analysis alongside other components of the script. This is normal behavior for scripts detecting pivots as a part of a system and it is important you are aware the pivot labels are not designed to be traded in real-time themselves
🔶 USAGE
The indicator can provide information helping the user to infer the position of future pivot points. This information is directly used in the indicator to provide such forecasting. Note that each metric is calculated relative to the same type of pivot points.
It is also common for analysts to use pivot points for the construction of various figures, getting the percentage change and distance for each pivot point can allow them to eventually filter out points of non-interest.
🔹 Forecast
We use the trailing mean of the distance between respective pivots to estimate the time position of future pivot points, this can be useful to estimate the location of future tops/bottoms. The time position of the forecasted pivot is given by a vertical dashed line on the chart.
We can see a successful application of this method below:
Above we see the forecasted pivots for BTCUSD15. The forecast of interest being the pivot high. We highlight the forecast position with a blue dotted line for reference.
After some time we obtain a new pivot high with a new forecast. However, we can see that the time location of this new pivot high matches perfectly with the prior forecast.
The position in time for the forecast is given by:
x1_ph + E
x1_pl + E
where x1_ph denotes the position in time of the most recent pivot high. x1_pl denotes the position in time of the most recent pivot low and E the average distance between respective pivot points.
🔶 SETTINGS
Length: Window size for the detection of pivot points.
Show Forecasted Pivots: Display forecast of future pivot points.
🔹 Dashboard
Dashboard Location: Location of the dashboard on the chart
Dashboard Size: Size of the dashboard on the chart
Text/Frame Color: Determines the color of the frame grid as well as the text color

Multiple Regression Polynomial ForecastEXPERIMENTAL:
Forecasting using a polynomial regression over the estimates of multiple linear regression forecasts.
note: on low data the estimates are skewd away of initial value, i added the i_min_estimate option in to try curve this issue with limited success "o_o.

Function - Forecast LinearFunction to calculate a forecast using a linear regression approach, this is the same function used on excel and other data sheet programs.
reference:
- support.microsoft.com
- stackoverflow.com

Multi Moving Average with ForecastThis script allows to use 5 different MAs with prediction of the next five periods.
