Mxwll Price Action Suite [Mxwll]Introducing the Mxwll Price Action Suite!
The Mxwll Price Action Suite is an all-in-one analysis indicator incorporating elements of SMC and also ideas extending beyond the trading methodology!
Features
Internal structures
External structures
Customizable Sensitivities
BoS/CHoCH
Order Blocks
HH/LH/LL/LH Areas
Rolling TF highs/lows
Rolling Volume Comparisons
Auto Fibs
And more!
The image above shows the indicator's market structure identification capabilities. Internal BoS and CHoCH structures in addition to overarching market structures are available with customizable sensitivities.
The image above shows the indicator identifying order blocks! Additionally, HH/LH/LL/LH areas are also identified.
The image above shows a rolling area of interest. These areas can be compared to supply/demand zones, where traders might consider a bargain long/short/sell area.
The indicator displays a rolling 4hr high/low and 1D high/low, alongside auto fibonacci levels with a customizable sensitivity.
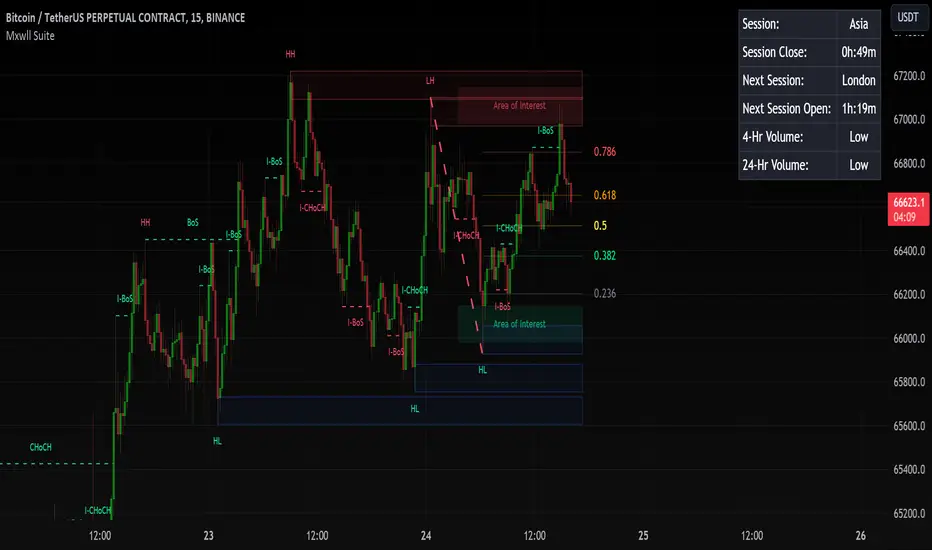
Finally, the Mxwll Price Action Suite shows relevant session information.
Table information
Current Session
Countdown to session close
Next Session
Countdown to next session open
Rolling 4-Hr volume intensity
Rolling 24-Hr volume intensity
Introducing the Mxwll SMC Suite!
The Mxwll SMC Suite is an all-in-one analysis indicator incorporating elements of SMC and also ideas extending beyond the trading methodology!
Features
Internal structures
External structures
Customizable Sensitivities
BoS/CHoCH
Order Blocks
HH/LH/LL/LH Areas
Rolling TF highs/lows
Rolling Volume Comparisons
Auto Fibs
And more!
The image above shows the indicator's market structure identification capabilities. Internal BoS and CHoCH structures in addition to overarching market structures are available with customizable sensitivities.
The image above shows the indicator identifying order blocks! Additionally, HH/LH/LL/LH areas are also identified.
The image above shows a rolling area of interest. These areas can be compared to supply/demand zones, where traders might consider a bargain long/short/sell area.
The indicator displays a rolling 4hr high/low and 1D high/low, alongside auto fibonacci levels with a customizable sensitivity.
Finally, the Mxwll Price Action Suite shows relevant session information.
Table information
Current Session
Countdown to session close
Next Session
Countdown to next session open
Rolling 4-Hr volume intensity
Rolling 24-Hr volume intensity
Expanded Features of Mxwll Price Action Suite
Internal and External Structures
Internal Structures: These elements refer to the price formations and patterns that occur within a smaller scope or a specific trading session. The suite can detect intricate details like minor support/resistance levels or short-term trend reversals.
External Structures: These involve larger, more significant market patterns and trends spanning multiple sessions or time frames. This capability helps traders understand overarching market directions.
Customizable Sensitivities
Adjusting sensitivity settings allows users to tailor the indicator's responsiveness to market changes. Higher sensitivity can catch smaller fluctuations, while lower sensitivity might focus on more significant, reliable market moves.
Break of Structure (BoS) and Change of Character (CHoCH)
BoS: This feature identifies points where the price breaks a significant structure, potentially indicating a new trend or a trend reversal.
CHoCH: Detects subtle shifts in the market's behavior, which could suggest the early stages of a trend change before they become apparent to the broader market.
Order Blocks and Market Phases
Order Blocks: These are essentially price levels or zones where significant trading activities previously occurred, likely pointing to the positions of smart money.
HH/LH/LL/LH Areas: Identifying Higher Highs (HH), Lower Highs (LH), Lower Lows (LL), and Lower Highs (LH) helps in understanding the trend and market structure, aiding in predictive analysis.
Rolling Timeframe Highs/Lows and Volume Comparisons
Tracks highs and lows over specified rolling periods, providing dynamic support and resistance levels.
Compares volume data across different timeframes to assess the strength or weakness of the current price movements.
Auto Fibonacci Levels
Automatically calculates and plots Fibonacci retracement levels, a popular tool among traders to identify potential reversal points based on past movements.
Session Data and Volume Intensity
Session Information: Displays current and upcoming trading sessions along with countdown timers, which is crucial for day traders and those trading on session overlaps.
Volume Intensity: Measures and compares the volume within the last 4 hours and 24 hours to gauge market activity and potential breakout/breakdown movements.
Visualizations and Practical Use
Dynamic Visuals: The suite provides dynamic visual aids, such as real-time updating of high/low markers and Fibonacci levels, which adjust as new data comes in. This feature is critical in fast-paced markets.
Strategic Entry/Exit Points: By identifying order blocks and using Fibonacci levels, traders can pinpoint strategic entry and exit points, maximizing potential returns.
Risk Management: Enhanced features like session countdowns and volume intensity help in better risk management by providing traders with more data on market sentiment and potential volatility.
Индикаторы и стратегии
Percent Rank HistogramThis Pine script indicator is designed to create a visual representation of the percent rank for multiple financial instruments. Here's a breakdown of its key features:
Percent Rank Calculation:
The core functionality of this Pine script indicator revolves around the calculation of the percent rank for each selected financial instrument.
The percent rank is a statistical measure that indicates the percentage of historical data points that are less than or equal to the current value in a given series.
Symbol Selection:
The script allows the user to select up to 10 financial instruments (tickers) for analysis. The default symbols include various cryptocurrencies such as BTCUSD, ETHUSD etc., and TOTAL market cap at ticker 1, to show overal trend of crypto market.
(Top 9 Coins by market cap).
Columns and Colors:
The script visually represents the percent rank using columns based on lines.
The color of each column is determined by a gradient from red to green based on the calculated percent rank, providing a quick visual indication of the instrument's relative performance.
BTC Trending Up while other coins are underperformance:
Labels:
Labels are displayed on the chart, indicating the symbol name and the corresponding percent rank percentage.
The labels include directional arrows (▲ or ▼) to denote whether the percent rank is increasing or decreasing.
Customization:
Users can customize parameters such as the percent rank length and column width to adapt the indicator to their specific preferences, or select needed assets to compare them to each other.
Chart Desk and Scales:
The script includes the visualization of a chart desk with scale lines to provide additional context to the chart. When Percent Rank above middle scale line (50) usually it signaling about asset trending up and below 50 asset trending down.
Mozilla Public License:
The script is subject to the terms of the Mozilla Public License 2.0.
This indicator is useful for traders and analysts interested in visually assessing the percent rank of multiple financial instruments simultaneously, helping them identify potential opportunities or trends in the market.

Heat Map SeasonsHeat Map Seasons indicator
Indicator offers traders a unique perspective on market dynamics by visualizing seasonal trends and deviations from typical price behavior. By blending regression analysis with a color-coded heat map, this indicator highlights periods of heightened volatility and helps identify potential shifts in market sentiment.
Summer:
In the context of the indicator, "summer" represents a period of heightened volatility and upward price momentum in the market. This is analogous to the warmer months of the year when activities are typically more vibrant and energetic. During the "summer" phase indicated by the indicator, traders may observe strong bullish trends, increased trading volumes, and larger price movements. It suggests a favorable environment for bullish strategies, such as trend following or momentum trading. However, traders should exercise caution as heightened volatility can also lead to increased risk and potential drawdowns.
Winter:
Conversely, "winter" signifies a period of decreased volatility and potentially sideways or bearish price action in the market. Similar to the colder months of the year when activities tend to slow down, the "winter" phase in the indicator suggests a quieter market environment with subdued price movements and lower trading volumes. During this phase, traders may encounter choppy price action, consolidation patterns, or even downtrends. It indicates a challenging environment for trend-following strategies and may require a more cautious approach, such as range-bound or mean-reversion trading strategies.
In summary, the "summer" and "winter" phases in the "Heat Map Seasons" indicator provide traders with valuable insights into the prevailing market sentiment and can help inform their trading decisions based on the observed levels of volatility and price momentum.
How to Use:
Watch for price bars that deviate significantly from the regression line , as these may signal potential trading opportunities.
Use the seasonal gauge to gauge the current market sentiment and adjust trading strategies accordingly.
Experiment with different settings for Length and Heat Sensitivity to customize the indicator to your trading style and preferences.
The "Heat Map Seasons" indicator can potentially identify overheated market tops and bottoms on a weekly timeframe by detecting significant deviations from the regression line and observing extreme color gradients in the heat map. Here's how it can be used for this purpose:
Observing Extreme Color Gradients:
When the market is overheated and reaches a potential top, you may observe extremely warm colors (e.g., deep red) in the heat map section of the indicator.
Traders can interpret this as a warning sign of a potential market top, indicating that bullish momentum may be reaching unsustainable levels.
Conversely, when prices deviate too far below the regression line, it may indicate oversold conditions and a potential bottom.
Potential Tops and Bottoms:
User Inputs:
Length: Determines the length of the regression analysis period.
Heat Sensitivity: Controls the sensitivity of the heat map to deviations from the regression line.
Show Regression Line: Option to display or hide the regression line on the chart
Note: This indicator is best used in conjunction with other technical analysis tools and should not be relied upon as the sole basis for trading decisions.

Index Generator [By MUQWISHI]▋ INTRODUCTION :
The “Index Generator” simplifies the process of building a custom market index, allowing investors to enter a list of preferred holdings from global securities. It aims to serve as an approach for tracking performance, conducting research, and analyzing specific aspects of the global market. The output will include an index value, a table of holdings, and chart plotting, providing a deeper understanding of historical movement.
_______________________
▋ OVERVIEW:
The image can be taken as an example of building a custom index. I created this index and named it “My Oil & Gas Index”. The index comprises several global energy companies. Essentially, the indicator weights each company by collecting the number of shares and then computes the market capitalization before sorting them as seen in the table.
_______________________
▋ OUTPUTS:
The output can be divided into 3 sections:
1. Index Title (Name & Value).
2. Index Holdings.
3. Index Chart.
1. Index Title , displays the index name at the top, and at the bottom, it shows the index value, along with the daily change in points and percentage.
2. Index Holdings , displays list the holding securities inside a table that contains the ticker, price, daily change %, market cap, and weight %. Additionally, a tooltip appears when the user passes the cursor over a ticker's cell, showing brief information about the company, such as the company's name, exchange market, country, sector, and industry.
3. Index Chart , display a plot of the historical movement of the index in the form of a bar, candle, or line chart.
_______________________
▋ INDICATOR SETTINGS:
(1) Naming the index.
(2) Entering a currency. To unite all securities in one currency.
(3) Table location on the chart.
(4) Table’s cells size.
(5) Table’s colors.
(6) Sorting table. By securities’ (Market Cap, Change%, Price, or Ticker Alphabetical) order.
(7) Plotting formation (Candle, Bar, or Line)
(8) To show/hide any indicator’s components.
(9) There are 34 fields where user can fill them with symbols.
Please let me know if you have any questions.

Higher-timeframe requests█ OVERVIEW
This publication focuses on enhancing awareness of the best practices for accessing higher-timeframe (HTF) data via the request.security() function. Some "traditional" approaches, such as what we explored in our previous `security()` revisited publication, have shown limitations in their ability to retrieve non-repainting HTF data. The fundamental technique outlined in this script is currently the most effective in preventing repainting when requesting data from a higher timeframe. For detailed information about why it works, see this section in the Pine Script™ User Manual .
█ CONCEPTS
Understanding repainting
Repainting is a behavior that occurs when a script's calculations or outputs behave differently after restarting it. There are several types of repainting behavior, not all of which are inherently useless or misleading. The most prevalent form of repainting occurs when a script's calculations or outputs exhibit different behaviors on historical and realtime bars.
When a script calculates across historical data, it only needs to execute once per bar, as those values are confirmed and not subject to change. After each historical execution, the script commits the states of its calculations for later access.
On a realtime, unconfirmed bar, values are fluid . They are subject to change on each new tick from the data provider until the bar closes. A script's code can execute on each tick in a realtime bar, meaning its calculations and outputs are subject to realtime fluctuations, just like the underlying data it uses. Each time a script executes on an unconfirmed bar, it first reverts applicable values to their last committed states, a process referred to as rollback . It only commits the new values from a realtime bar after the bar closes. See the User Manual's Execution model page to learn more.
In essence, a script can repaint when it calculates on realtime bars due to fluctuations before a bar's confirmation, which it cannot reproduce on historical data. A common strategy to avoid repainting when necessary involves forcing only confirmed values on realtime bars, which remain unchanged until each bar's conclusion.
Repainting in higher-timeframe (HTF) requests
When working with a script that retrieves data from higher timeframes with request.security() , it's crucial to understand the differences in how such requests behave on historical and realtime bars .
The request.security() function executes all code required by its `expression` argument using data from the specified context (symbol, timeframe, or modifiers) rather than on the chart's data. As when executing code in the chart's context, request.security() only returns new historical values when a bar closes in the requested context. However, the values it returns on realtime HTF bars can also update before confirmation, akin to the rollback and recalculation process that scripts perform in the chart's context on the open bar. Similar to how scripts operate in the chart's context, request.security() only confirms new values after a realtime bar closes in its specified context.
Once a script's execution cycle restarts, what were previously realtime bars become historical bars, meaning the request.security() call will only return confirmed values from the HTF on those bars. Therefore, if the requested data fluctuates across an open HTF bar, the script will repaint those values after it restarts.
This behavior is not a bug; it's simply the default behavior of request.security() . In some cases, having the latest information from an unconfirmed HTF bar is precisely what a script needs. However, in many other cases, traders will require confirmed, stable values that do not fluctuate across an open HTF bar. Below, we explain the most reliable approach to achieve such a result.
Achieving consistent timing on all bars
One can retrieve non-fluctuating values with consistent timing across historical and realtime feeds by exclusively using request.security() to fetch the data from confirmed HTF bars. The best way to achieve this result is offsetting the `expression` argument by at least one bar (e.g., `close [1 ]`) and using barmerge.lookahead_on as the `lookahead` argument.
We discourage the use of barmerge.lookahead_on alone since it prompts the function to look toward future values of HTF bars across historical data, which is heavily misleading. However, when paired with a requested `expression` that includes a one-bar historical offset, the "future" data the function retrieves is not from the future. Instead, it represents the last confirmed bar's values at the start of each HTF bar, thus preventing the results on realtime bars from fluctuating before confirmation from the timeframe.
For example, this line of code uses a request.security() call with barmerge.lookahead_on to request the close price from the "1D" timeframe, offset by one bar with the history-referencing operator [ ] . This line will return the daily price with consistent timing across all bars:
float htfClose = request.security(syminfo.tickerid, "1D", close , lookahead = barmerge.lookahead_on)
Note that:
• This technique only works as intended for higher-timeframe requests .
• When designing a script to work specifically with HTFs, we recommend including conditions to prevent request.security() from accessing timeframes equal to or lower than the chart's timeframe, especially if you intend to publish it. In this script, we included an if structure that raises a runtime error when the requested timeframe is too small.
• A necessary trade-off with this approach is that the script must wait for an HTF bar's confirmation to retrieve new data on realtime bars, thus delaying its availability until the open of the subsequent HTF bar. The time elapsed during such a delay varies with each market, but it's typically relatively small.
👉 Failing to offset the function's `expression` argument while using barmerge.lookahead_on will produce historical results with lookahead bias , as it will look to the future states of historical HTF bars, retrieving values before the times at which they're available in the feed. See the `lookahead` and Future leak with `request.security()` sections in the Pine Script™ User Manual for more information.
Evolving practices
The fundamental technique outlined in this publication is currently the only reliable approach to requesting non-repainting HTF data with request.security() . It is the superior approach because it avoids the pitfalls of other methods, such as the one introduced in the `security()` revisited publication. That publication proposed using a custom `f_security()` function, which applied offsets to the `expression` and the requested result based on historical and realtime bar states. At that time, we explored techniques that didn't carry the risk of lookahead bias if misused (i.e., removing the historical offset on the `expression` while using lookahead), as requests that look ahead to the future on historical bars exhibit dangerously misleading behavior.
Despite these efforts, we've unfortunately found that the bar state method employed by `f_security()` can produce inaccurate results with inconsistent timing in some scenarios, undermining its credibility as a universal non-repainting technique. As such, we've deprecated that approach, and the Pine Script™ User Manual no longer recommends it.
█ METHOD VARIANTS
In this script, all non-repainting requests employ the same underlying technique to avoid repainting. However, we've applied variants to cater to specific use cases, as outlined below:
Variant 1
Variant 1, which the script displays using a lime plot, demonstrates a non-repainting HTF request in its simplest form, aligning with the concept explained in the "Achieving consistent timing" section above. It uses barmerge.lookahead_on and offsets the `expression` argument in request.security() by one bar to retrieve the value from the last confirmed HTF bar. For detailed information about why this works, see the Avoiding Repainting section of the User Manual's Other timeframes and data page.
Variant 2
Variant 2 ( fuchsia ) introduces a custom function, `htfSecurity()`, which wraps the request.security() function to facilitate convenient repainting control. By specifying a value for its `repaint` parameter, users can determine whether to allow repainting HTF data. When the `repaint` value is `false`, the function applies lookahead and a one-bar offset to request the last confirmed value from the specified `timeframe`. When the value is `true`, the function requests the `expression` using the default behavior of request.security() , meaning the results can fluctuate across chart bars within realtime HTF bars and repaint when the script restarts.
Note that:
• This function exclusively handles HTF requests. If the requested timeframe is not higher than the chart's, it will raise a runtime error .
• We prefer this approach since it provides optional repainting control. Sometimes, a script's calculations need to respond immediately to realtime HTF changes, which `repaint = true` allows. In other cases, such as when issuing alerts, triggering strategy commands, and more, one will typically need stable values that do not repaint, in which case `repaint = false` will produce the desired behavior.
Variant 3
Variant 3 ( white ) builds upon the same fundamental non-repainting approach used by the first two. The difference in this variant is that it applies repainting control to tuples , which one cannot pass as the `expression` argument in our `htfSecurity()` function. Tuples are handy for consolidating `request.*()` calls when a script requires several values from the same context, as one can request a single tuple from the context rather than executing multiple separate request.security() calls.
This variant applies the internal logic of our `htfSecurity()` function in the script's global scope to request a tuple containing open and `srcInput` values from a higher timeframe with repainting control. Historically, Pine Script™ did not allow the history-referencing operator [ ] when requesting tuples unless the tuple came from a function call, which limited this technique. However, updates to Pine over time have lifted this restriction, allowing us to pass tuples with historical offsets directly as the `expression` in request.security() . By offsetting all items in a tuple `expression` by one bar and using barmerge.lookahead_on , we effectively retrieve a tuple of stable, non-repainting HTF values.
Since we cannot encapsulate this method within the `htfSecurity()` function and must execute the calculations in the global scope, the script's "Repainting" input directly controls the global `offset` and `lookahead` values to ensure it behaves as intended.
Variant 4 (Control)
Variant 4, which the script displays as a translucent orange plot, uses a default request.security() call, providing a reference point to compare the difference between a repainting request and the non-repainting variants outlined above. Whenever the script restarts its execution cycle, realtime bars become historical bars, and the request.security() call here will repaint the results on those bars.
█ Inputs
Repainting
The "Repainting" input (`repaintInput` variable) controls whether Variant 2 and Variant 3 are allowed to use fluctuating values from an unconfirmed HTF bar. If its value is `false` (default), these requests will only retrieve stable values from the last confirmed HTF bar.
Source
The "Source" input (`srcInput` variable) determines the series the script will use in the `expression` for all HTF data requests. Its default value is close .
HTF Selection
This script features two ways to specify the higher timeframe for all its data requests, which users can control with the "HTF Selection" input (`tfTypeInput` variable):
1) If its value is "Fixed TF", the script uses the timeframe value specified by the "Fixed Higher Timeframe" input (`fixedTfInput` variable). The script will raise a runtime error if the selected timeframe is not larger than the chart's.
2) If the input's value is "Multiple of chart TF", the script multiplies the value of the "Timeframe Multiple" input (`tfMultInput` variable) by the chart's timeframe.in_seconds() value, then converts the result to a valid timeframe string via timeframe.from_seconds() .
Timeframe Display
This script features the option to display an "information box", i.e., a single-cell table that shows the higher timeframe the script is currently using. Users can toggle the display and determine the table's size, location, and color scheme via the inputs in the "Timeframe Display" group.
█ Outputs
This script produces the following outputs:
• It plots the results from all four of the above variants for visual comparison.
• It highlights the chart's background gray whenever a new bar starts on the higher timeframe, signifying when confirmations occur in the requested context.
• To demarcate which bars the script considers historical or realtime bars, it plots squares with contrasting colors corresponding to bar states at the bottom of the chart pane.
• It displays the higher timeframe string in a single-cell table with a user-specified size, location, and color scheme.
Look first. Then leap.

Trailing Management (Zeiierman)█ Overview
The Trailing Management (Zeiierman) indicator is designed for traders who seek an automated and dynamic approach to managing trailing stops. It helps traders make systematic decisions regarding when to enter and exit trades based on the calculated risk-reward ratio. By providing a clear visual representation of trailing stop levels and risk-reward metrics, the indicator is an essential tool for both novice and experienced traders aiming to enhance their trading discipline.
The Trailing Management (Zeiierman) indicator integrates a Break-Even Curve feature to enhance its utility in trailing stop management and risk-reward optimization. The Break-Even Curve illuminates the precise point at which a trade neither gains nor loses value, offering clarity on the risk-reward landscape. Furthermore, this precise point is calculated based on the required win rate and the risk/reward ratio. This calculation aids traders in understanding the type of strategy they need to employ at any given time to be profitable. In other words, traders can, at any given point, assess the kind of strategy they need to utilize to make money, depending on the price's position within the risk/reward box.
█ How It Works
The indicator operates by computing the highest high and the lowest low over a user-defined period and then applying this information to determine optimal trailing stop levels for both long and short positions.
Directional Bias:
It establishes the direction of the market trend by comparing the index of the highest high and the lowest low within the lookback period.
Bullish
Bearish
Trailing Stop Adjustment:
The trailing stops are adjusted using one of three methods: an automatic calculation based on the median of recent peak differences, pivot points, or a fixed percentage defined by the user.
The Break-Even Curve:
The Break-Even Curve, along with the risk/reward ratio, is determined through the trailing method. This approach utilizes the current closing price as a hypothetical entry point for trades. All calculations, including those for the curve, are based on this current closing price, ensuring real-time accuracy and relevance. As market conditions fluctuate, the curve dynamically adjusts, offering traders a visual benchmark that signifies the break-even point. This real-time adjustment provides traders with an invaluable tool, allowing them to visually track how shifts in the market could impact the point at which their trades neither gain nor lose value.
Example:
Let's say the price is at the midpoint of the risk/reward box; this means that the risk/reward ratio should be 1:1, and the minimum win rate is 50% to break even.
In this example, we can see that the price is near the stop-loss level. If you are about to take a trade in this area and would respect your stop, you only need to have a minimum win rate of 11% to earn money, given the risk/reward ratio, assuming that you hold the trade to the target.
In other words, traders can, at any given point, assess the kind of strategy they need to employ to make money based on the price's position within the risk/reward box.
█ How to Use
Market Bias:
When using the Auto Bias feature, the indicator calculates the underlying market bias and displays it as either bullish or bearish. This helps traders align their trades with the underlying market trend.
Risk Management:
By observing the plotted trailing stops and the risk-reward ratios, traders can make strategic decisions to enter or exit positions, effectively managing the risk.
Strategy selection:
The Break-Even Curve is a powerful tool for managing risk, allowing traders to visualize the relationship between their trailing stops and the market's price movements. By understanding where the break-even point lies, traders can adjust their strategies to either lock in profits or cut losses.
Based on the plotted risk/reward box and the location of the price within this box, traders can easily see the win rate required by their strategy to make money in the long run, given the risk/reward ratio.
Consider this example: The market is bullish, as indicated by the bias, and the indicator suggests looking into long trades. The price is near the top of the risk/reward box, which means entering the market right now carries a huge risk, and the potential reward is very low. To take this trade, traders must have a strategy with a win rate of at least 90%.
█ Settings
Trailing Method:
Auto: The indicator calculates the trailing stop dynamically based on market conditions.
Pivot: The trailing stop is adjusted to the highest high (long positions) or lowest low (short positions) identified within a specified lookback period. This method uses the pivotal points of the market to set the trailing stop.
Percentage: The trailing stop is set at a fixed percentage away from the peak high or low.
Trailing Size (prd):
This setting defines the lookback period for the highest high and lowest low, which affects the sensitivity of the trailing stop to price movements.
Percentage Step (perc):
If the 'Percentage' method is selected, this setting determines the fixed percentage for the trailing stop distance.
Set Bias (bias):
Allows users to set a market bias which can be Bullish, Bearish, or Auto, affecting how the trailing stop is adjusted in relation to the market trend.
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!

Periodic Activity Tracker [LuxAlgo]The Periodic Activity Tracker tool periodically tracks the cumulative buy and sell volume in a user-defined period and draws the corresponding matching bars and volume delta for each period.
Users can select a predefined aggregation period from the following options: Hourly, Daily, Weekly, and Monthly.
🔶 USAGE
This tool provides a simple and clear way of analyzing volumes for each aggregated period and is made up of the following elements:
Buy and sell volumes by period as red and green lines with color gradient area
Delta (difference) between buy & sell volume for each period
Buy & sell volume bars for each period
Separator between lines and bars, and period tags below each pair of bars for ease of reading
On the chart above we can see all the elements displayed, the volume level on the lines perfectly matches the volume level on the bars for each period.
In this case, the tool has the default settings so the anchor period is set to Daily and we can see how the period tag (each day of the week) is displayed below each pair of bars.
Users can disable the delta display and adjust the bar size.
🔹 Reading The Tool
In trading, assessing the strength of the bulls (buyers) and bears (sellers) is key to understanding the current trading environment. Which side, if any, has the upper hand? To answer this question, some traders look at volume in relation to price.
This tool provides you with a view of buy volume versus sell volume, allowing you to compare both sides of the market.
As with any volume tool, the key is to understand when the forces of the two groups are balanced or unbalanced.
As we can observe on the chart:
NOV '23: Buy volume greater than sell volume, both moving up close together, flat delta. We can see that the price is in range.
DEC '23: Buy volume bigger than Sell volume, both moving up but with a bigger difference, bigger delta than last month but still flat. We can see the price in the range above last month's range.
JAN '24: Buy and sell volume tied together, no delta whatsoever. We can see the price in range but testing above and below last month's range.
FEB '24: Buy volume explodes higher and sell volume cannot keep up, big growing delta. Price explodes higher above last month's range.
Traders need to understand that there is always an equal number of buyers and sellers in a liquid market, the quality here is how aggressive or passive they are. Who is 'attacking' and who is 'defending', who is using market orders to move prices, and who is using limit orders waiting to be filled?
This tool gives you the following information:
Lines: if the top line is green, the buyers are attacking, if it is red, the sellers are attacking.
Delta: represents the difference in their strength, if it is above 0 the buyers are stronger, if it is below 0 the sellers are stronger.
Bars: help you to see the difference in strength between buyers and sellers for each period at a glance.
🔹 Anchor Period
By default, the tool is set to Hourly. However, users can select from a number of predefined time periods.
Depending on the user's selection, the bars are displayed as follows:
Hourly : hours of the current day
Daily : days of the current week
Weekly : weeks of the current month
Monthly : months of the current year
On the chart above we can see the four periods displayed, starting at the top left and moving clockwise we have hourly, daily, weekly, and monthly.
🔶 DETAILS
🔹 Chart TimeFrame
The chart timeframe has a direct impact on the visualization of the tool, and the user should select a chart timeframe that is compatible with the Anchor period in the tool's settings panel.
For the chart timeframe to be compatible it must be less than the Anchor period parameter. If the user selects an incompatible chart timeframe, a warning message will be displayed.
As a rule of thumb, the smaller the chart timeframe, the more data the tool will collect, returning indications for longer-term price variations.
These are the recommended chart timeframes for each period:
Hourly : 5m charts or lower
Daily : 1H charts or lower
Weekly : 4H charts or lower
Monthly : 1D charts or lower
🔹 Warnings
This chart shows both types of warnings the user may receive
At the top, we can see the warning that is given when the 'Bar Width' parameter exceeds the allowed value.
At the bottom is the incompatible chart timeframe warning, which prompts the user to select a smaller chart timeframe or a larger "Anchor Period" parameter.
🔶 SETTINGS
🔹 Data Gathering
Anchor period: Time period representing each bar: hours of the day, days of the week, weeks of the month, and months of the year. The timeframe of the chart must be less than this parameter, otherwise a warning will be displayed.
🔹 Style
Bars width: Size of each bar, there is a maximum limit so a warning will be displayed if it is reached.
Volume color
Delta: Enable/Disable Delta Area Display

Gaps Profile [vnhilton]Note: If you get an error preventing indicator from executing due to a loop running longer than >500ms, please lower the amount of boxes shown and/or increase the minimum gap % threshold.
OVERVIEW
The Gaps Profile (GP) simply shows the remaining gaps on the chart that have yet to be closed. Gaps are created where there's a distance between the current open and the previous close. Big gaps suggest change in sentiment and volatility causing prices to pull away thereby creating gaps. Gaps can be used as pivot areas where price may attempt to close the inefficiency entirely and/or serve as supply/demand zones.
(FEATURES)
- 3 to 499 remaining up/down gaps can be displayed on the chart (furthest gaps away from price are removed to make way for new gaps)
- Minimum gap % threshold
- Ability to highlight largest or newest up/down gap
- 4 GP color themes: Mono, Up/Down, Up/Down Largest Gradients, Up/Down Newest Gradients
- GP Type: Left, Right (how it is built - overlapping gaps plotted from left/right to right/left)
- GP offset from current bar
- Box border width
- Box border style for up/down: Dashed, Dotted, Solid
- Toggles to hide border/box with ease
TTrades Daily Bias [TFO]Inspired by @TTrades_edu video on daily bias, this indicator aims to develop a higher timeframe bias and collect data on its success rate. While a handful of concepts were introduced in said video, this indicator focuses on one specific method that utilizes previous highs and lows. The following description will outline how the indicator works using the daily timeframe as an example, but the weekly timeframe is also an included option that functions in the exact same manner.
On the daily timeframe, there are a handful of possible scenarios that we consider: if price closes above its previous day high (PDH), the following day's bias will target PDH; if price trades above its PDH but closes back below it, the following day's bias will target its previous day low (PDL).
Similarly, if price closes below its PDL, the following day's bias will target PDL. If price trades below its PDL but closes back above it, the following day's bias will target PDH.
If price trades as an inside bar that doesn't take either PDH or PDL, it will refer to the previous candle for bias. If the previous day closed above its open, it will target PDH and vice versa. If price trades as an outside bar that takes both PDH and PDL, but closes inside that range, no bias is assigned.
With a rigid framework in place, we can apply it to the charts and observe the results.
As shown above, each new day starts by drawing out the PDH and PDL levels. They start out as blue and turn red once traded through (these are the default colors which can be changed in the indicator's settings). The triangles you see are plotted to indicate the time at which PDH or PDL was traded through. This color scheme is also applied to the table in the top right; once a bias is determined, that cell's color starts out as blue and turns red once the level is traded through.
The table indicates the success rate of price hitting the levels provided by each period's bias, followed by the success rate of price closing through said levels after reaching them, as well as the sample size of data collected for each scenario.
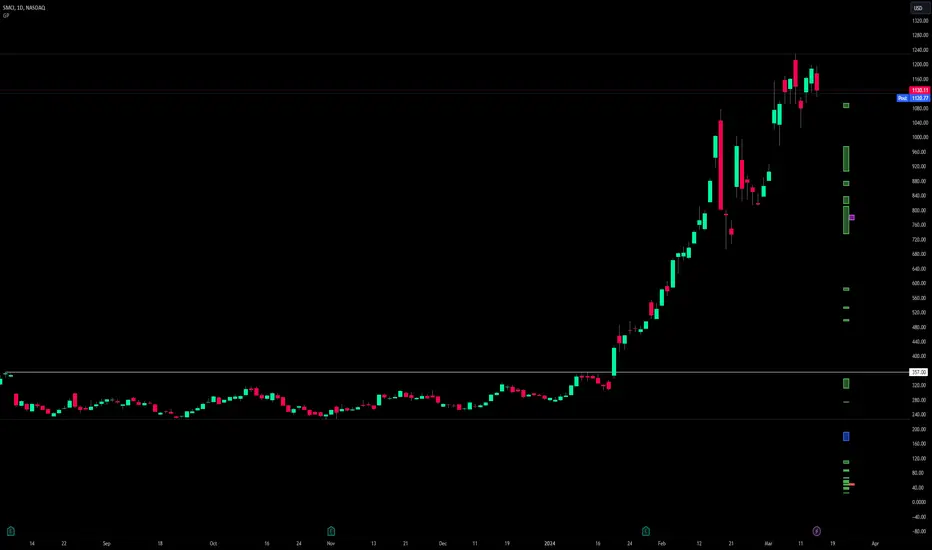
In the above crude oil futures (CL1!) 30m chart, we can glean a lot of information from the table in the top right. First we may note that the "PDH" cell is red, which indicates that the current day's bias was targeting PDH and it has already traded through that level. We might also note that the "PWH" cell is blue, which indicates that the weekly bias is targeting the previous week high (PWH) but price has yet to reach that level.
As an example of how to read the table's data, we can look at the "PDH" row of the crude oil chart above. The sample size here indicates that there were 279 instances where the daily bias was assigned as PDH. From this sample size, 76.7% of instances did go on to trade through PDH, and only 53.7% of those instances actually went on to close through PDH after hitting that level.
Of course, greater sample sizes and therefore greater statistical significance may be derived from higher timeframe charts that may go further back in time. The amount of data you can observe may also depend on your TradingView plan.
If we don't want to see the labels describing why bias is assigned a certain way, we can simply turn off the "Show Bias Reasoning" option. Additionally, if we want to see a visual of what the daily and weekly bias currently is, we can plot that along the top and bottom of the chart, as shown above. Here I have daily bias plotted at the top and weekly bias at the bottom, where the default colors of green and red indicate that the bias logic is expecting price to draw towards the given timeframe's previous high or low, respectively.
For a compact table view that doesn't take up much chart space, simply deselect the "Show Statistics" option. This will only show the color-coded bias column for a quick view of what levels are being anticipated (more user-friendly for mobile and other smaller screens).
Alerts can be configured to indicate the bias for a new period, and/or when price hits its previous highs and lows. Simply enable the alerts you want from the indicator's settings and create a new alert with this indicator as the condition. There will be options to use "Any alert() function call" which will alert whatever is selected from the settings, or you can use more specific alerts for bullish/bearish bias, whether price hit PDH/PDL, etc.
Lastly, while the goal of this indicator was to evaluate the effectiveness of a very specific bias strategy, please understand that past performance does not guarantee future results.

Risk Management Chart█ OVERVIEW
Risk Management Chart allows you to calculate and visualize equity and risk depend on your risk-reward statistics which you can set at the settings.
This script generates random trades and variants of each trade based on your settings of win/loss percent and shows it on the chart as different polyline and also shows thick line which is average of all trades.
It allows you to visualize and possible to analyze probability of your risk management. Be using different settings you can adjust and change your risk management for better profit in future.
It uses compound interest for each trade.
Each variant of trade is shown as a polyline with color from gradient depended on it last profit.
Also I made blurred lines for better visualization with function :
poly(_arr, _col, _t, _tr) =>
for t = 1 to _t
polyline.new(_arr, false, false, xloc.bar_index, color.new(_col, 0 + t * _tr), line_width = t)
█ HOW TO USE
Just add it to the cart and expand the window.
█ SETTINGS
Start Equity $ - Amount of money to start with (your equity for trades)
Win Probability % - Percent of your win / loss trades
Risk/Reward Ratio - How many profit you will get for each risk(depends on risk per trade %)
Number of Trades - How many trades will be generated for each variant of random trading
Number of variants(lines) - How many variants will be generated for each trade
Risk per Trade % -risk % of current equity for each trade
If you have any ask it at comments.
Hope it will be useful.

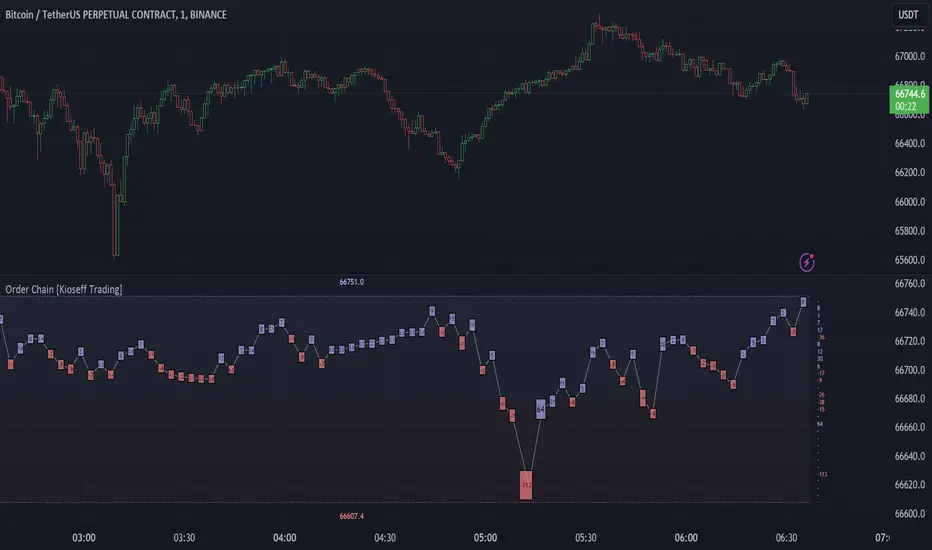
Order Chain [Kioseff Trading]Hello!
This indicator "Order Chain" uses live tick data (varip) to retrieve live tick volume.
This indicator must be used on a live market with volume data
Features
Live Tick Volume
Live Tick Volume Delta
Orders are appended to boxes, whose width and height are scaled proportional to the size of the order.
CVD recorded at relevant tick levels
Order chain spans up to 450 ticks (might include aggregates)
The image above shows key features for the indicator!
The image above explains line and color placements.
The image above shows the indicator in action for a live market!
How It Works
The indicator records the difference in volume from "now" and the previous tick. Predicated on whether the "now" price is greater than or less than price one tick prior, the difference in volume is recorded as "buy" or "sell" volume.
This filled order (or aggregates) is colored in congruence with price direction. The filled order is subsequently appended to its relevant tick level and added (buy order) or subtracted (sell order) from the CVD value at the identified tick level.
Of course, thank you to @PineCoders and @RicardoSantos for their awesome libraries :D
Thank you!
Gann Box (Zeiierman)█ Overview
The Gann Box (Zeiierman) is an indicator that provides visual insights using the principles of W.D. Gann's trading methods. Gann's techniques are based on geometry, astronomy, and astrology, and are used to predict important price levels and market trends. This indicator helps traders identify potential support and resistance levels, and forecast future price movements.
Gann used angles and various geometric constructions to divide time and price into proportionate parts. Gann indicators are often used to predict areas of support and resistance, key tops and bottoms, and future price moves.
█ How It Works
The indicator operates by identifying high and low points within a visible range on the chart and drawing a Gann Box between these points. The box is divided into segments based on selected percentages, which represent key levels for observing market reactions. It includes options to display labels, a Gann fan, and Gann angles for analysis. Advanced features allow extending the box into the future for predictive analysis and reversing its orientation for alternative viewpoints.
High and Low Points Identification: It starts by locating the highest and lowest price points visible on the chart.
Gann Box Construction: Draws a box from these points and divides it according to specified percentages, highlighting potential support and resistance levels.
█ How to Use
Support and Resistance Levels
Using a Gann angle to forecast support and resistance is probably the most popular way they are used. This technique frames the market, allowing the analyst to read the movement of the market inside this framework.
The lines within the Gann Box, drawn at the key percentages, create a grid of potential support and resistance levels. As prices fluctuate, these lines can act as barriers to price movement, with the price often pausing or reversing at these intervals.
Forecasting with the 'Extend' Feature: The indicator's ability to extend lines and boxes into the future provides traders with a forward-looking tool to anticipate potential market movements and prepare for them.
Gann Fan: This feature draws lines at a significant price angle, helping traders identify potential support and resistance levels based on the theory that prices move in predictable patterns.
Gann Curves: Gann Curves display dynamic support and resistance levels, aiding in the analysis of momentum and trend strength.
█ Settings
The indicator includes several settings that allow customization of its appearance and functionality:
⚪ General Settings
Reverse: This setting changes the orientation of labels and calculations within the Gann Box, providing alternative analytical perspectives. It essentially flips the Gann Box's direction, which can be useful in different market conditions or analysis scenarios.
Extend: Extends the drawing of Gann lines or boxes into the future beyond the current last bar. This feature is essential for forecasting future price movements and identifying potential support or resistance levels that lie outside the current price action.
⚪ Gann Box
Show Box: Toggles the visibility of the Gann Box on the chart. The Gann Box is a fundamental tool in Gann analysis, highlighting key levels based on selected high and low points to identify potential support and resistance areas.
Show Fibonacci Labels: Controls the display of Fibonacci labels within the Gann Box. These labels mark specific Fibonacci retracement levels, aiding traders in recognizing significant levels for potential reversals.
Box Visibility: Allows users to enable or disable individual boxes within the Gann Box, providing flexibility in focusing on specific levels of interest.
Percentage Levels: Defines the Fibonacci levels within the Gann Box. Traders can adjust these levels to customize the Gann Box according to their specific analysis needs.
Coloring: Customizes the color of each level within the Gann Box, enhancing visual clarity and differentiation between levels.
⚪ Gann Fan
Show Fan: Enables the Gann Fan, which draws lines at significant Gann angles from a particular point on the chart, helping identify potential support and resistance levels.
Fan Percentages and Coloring: Similar to the Gann Box, these settings allow traders to customize which Gann angles are displayed and how they are colored.
⚪ Gann Curves
Show Curves: When enabled, this setting draws Gann Curves on the chart. These curves are based on Gann percentages and provide a dynamic view of support and resistance levels as they adapt to changing market conditions.
Curve Percentages and Coloring: Define which curves are displayed and their colors, allowing for a tailored analysis experience.
⚪ Gann Angles
Show Angles: Toggles the display of Gann Angles, which are crucial for understanding the market's price and time dynamics, offering insights into future support and resistance levels.
Coloring: Customizes the color of the Gann Angles, making it easier to differentiate between various angles on the chart.
█ Alerts
The indicator includes several alert conditions for price breakouts from the Gann Box and specific levels, enabling traders to be notified of significant market movements.
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!
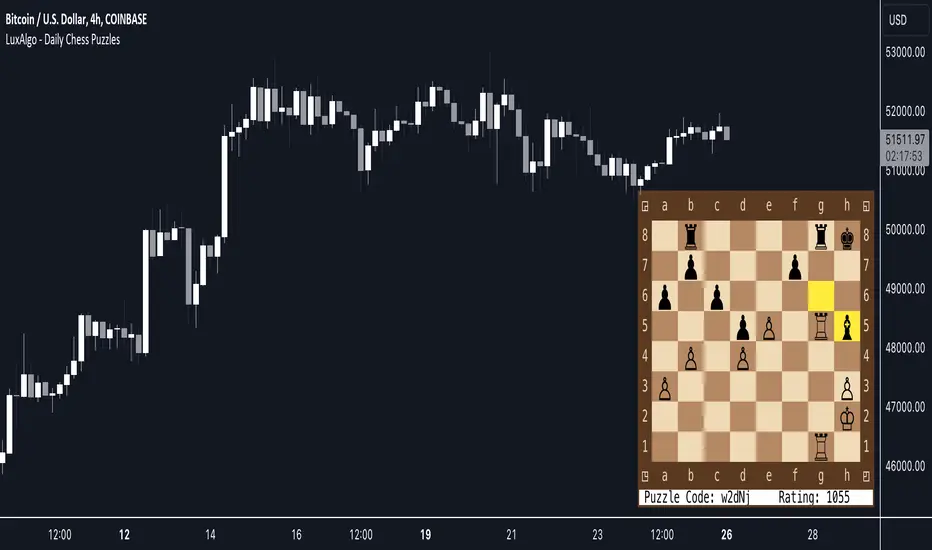
Daily Chess Puzzles [LuxAlgo]Play Chess Puzzles right on your Chart!
Daily Chess Puzzles brings you a new 1-Move chess puzzle straight to your chart every day.
🔶 USAGE
Submit your answer to see if your solution is correct! For quick access to the settings, Double-Click on the Chess board to open the settings interface.
The current active color (Who's move it is) is represented by the color of the information bar, and the corner board squares.
This game uses long algebraic notation without pieces names for submitting moves.
This method for determining moves is perfect for simplicity and clarity, and is standard for the Universal Chess Interface (UCI).
🔹 How to Notate
Long algebraic notation (without pieces name) is simple to understand. This notation does not use capture symbols or check/checkmate symbols; it uses only the squares involved in the move and any promotion occurring.
{Starting Square}{Ending Square}{Promotion Piece(if needed)}
Locate the starting square and the ending square of the piece being moved, without mentioning the piece itself.
Identify the column letters (a-h) and row numbers (1-8) that align with your desired move.
If a pawn reaches the opposite end of the board the pawn gets promoted, add the letter representing the piece it is promoted to at the end of the move.
Put it all together and you've got your notation!
Piece Notations for Pawn Promotions:
'n' for Knight ('k' is reserved for the King in chess notation)
'b' for Bishop
'r' for Rook
'q' for Queen
Normal Move Example: Moving a piece from e2 to e4 is notated as "e2e4".
Pawn Promotion Example: Promoting a pawn to a queen is notated as "e7e8q".
🔶 DETAILS
Miss a day? Yesterday's puzzle can be re-played, check the box for 'View Yesterday's Puzzle' in the settings.
This indicator makes use of Tooltips! . Hover over a square to see that square's notation.
This script makes use of 5 libraries, each storing 2 years worth of daily chess puzzles amounting to 10 years of unique daily chess puzzles.
"timenow" is used to determine which day it is, so even on a closed ticker or weekend or holiday a new chess puzzle will be displayed.
Users have the option to choose from 5 different board themes.
Ichimoku OscillatorHello All,
This is Ichimoku Oscillator that creates different oscillator layers, calculates the trend and possible entry/exit levels by using Ichimoku Cloud features.
There are four layer:
First layer is the distance between closing price and cloud (min or max, depending on the main trend)
Second layer is the distance between Lagging and Cloud X bars ago (X: the displacement)
Third layer is the distance between Conversion and Base lines
Fourth layer is the distance between both Leadlines
If all layers are visible maning that positive according to the main trend, you can take long/short position and when main trend changed then you should close the position. so it doesn't mean you can take position when main trend changed, you need to wait for all other conditions met (all layers(
there is take profit partially option. if Conversion and base lines cross then you can take profit partially. Optionally you can take profit partially when EMA line crosses Fourth layer.
Optionally ATR (average true range) is used for Conversion and baseline for protection from whipsaws. you can use it to stay on the trend longer time.
I added options to enable/disable the alert and customize alert messages. You can change alert messages as you wish. if you use ' close ' in the alert message then you can get closing price in the alert message when the alert was triggered.
There is an option Bounce Off Support/Resistance , if there is trend and if the price bounce off Support/Resistance zone then a tiny triangle is shown.
There are many other options for coloring, alerts etc.
Some screenshots:
Main trend:
Taking/closing positions:
Example alert messages:
Bounce off:
Colors:
Colors:
Colors:
Non-colored background:
P.S. For a few months I haven't published any new script because of some health issues. hope to be healthy and create new scripts in 2024 :)
Enjoy!
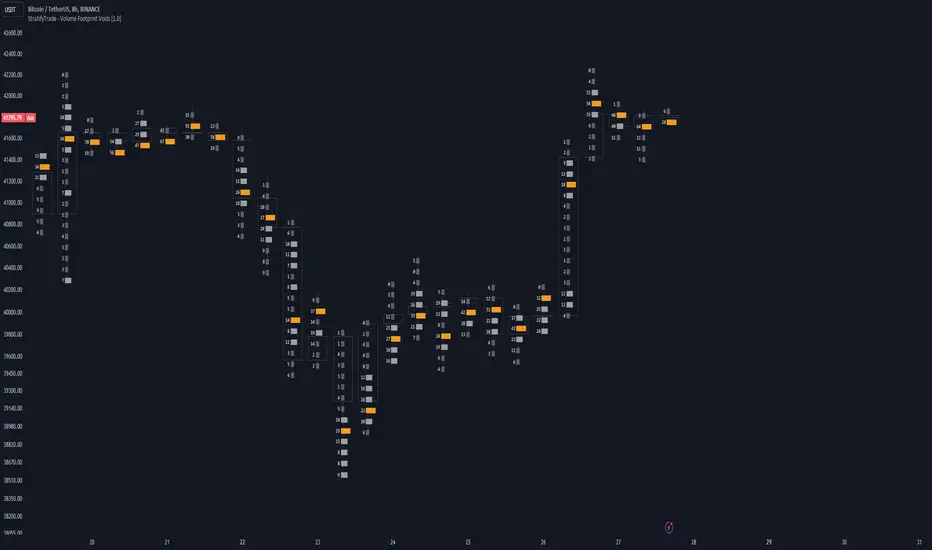
Volume Footprint Voids [BigBeluga]Volume Footprint Voids is a unique tool that uses lower timeframe calculation to plot different styles of single candle POC.
This indicator is very powerful for scalping and finding very precise entry and exits, spotting potential trapped traders, and more.
Unlike many other volume profiles, this aims to plot single candle profiles as well as their own footprints.
🔶 FEATURES
The script includes the following settings:
Windows: Plotting style and calculations
Coloring modes
Display modes
lower-timeframe calculations
🔶 CALCULATION
In the image above we can see how the script calculates each level position that will serve as a calculation process to see how much volume/closes there are within the levels.
In the image above, we can have a more clear example of how we count each candle close.
We use the prior screenshot as an example, after setting each level we will use the lower-timeframe input to measure the amount of closes within the ranges.
Depending on the lot size, the box will be larger or smaller, usually the POC will always have the highest box size.
NOTE: Size is the starting point, always from the low of the candle.
To find more voids, select a closer LTF to the current one you're using.
To find fewer voids, select a timeframe away from your current one.
Due to Pine Script limitations, we are only able to plot a certain amount of footprints, and we can't plot the whole history chart.
POC will be the largest block displayed, indicating the time point of control
Gray areas are closes above the average
Black are Void or imbalance that price will fill in the future, like FVG
The image above shows an incorrect size input that will lead to bad calculations, while on the other side, a correct size input that will lead to a clear vision and better calculation.
🔶 WINDOWS
The "▲▼" Mode will display delta buyers and delta sellers coloring with voids as black.
It also offers a gradient mode for a beautier visualization
The "Total Volume" mode will display the net volume within the lot size (closes within the levels).
This is useful to spot possible highest net volume within the same highest lot size.
The "POC + Gaps" will show both POC and Gaps as the highest block while all the rest will be considered as the smaller block.
This is useful to see where the highest lot were and if there are higher or lower imbalances within the candle
The last option "Gaps" will simply display the gaps as the highest block, while the POC as the lowest block.
This is useful to have a better view of the gaps areas
🔶 EXAMPLE
This is one of the most basic examples of how this script can be used. POC at the bottom creating a strong support area as price holds and creates higher voids gap that price fills while rising.
🔶 SETTINGS
Users have full control over the script, from colors to choosing the lower-timeframe inputs to disabling the lot size.
Auto Chart Patterns [Trendoscope®]🎲 Introducing our most comprehensive automatic chart pattern recognition indicator.
Last week, we published an idea on how to algorithmically identify and classify chart patterns.
This indicator is nothing but the initial implementation of the idea. Whatever we explained in that publication that users can do manually to identify and classify the pattern, this indicator will do it for them.
🎲 Process of identifying the patterns.
The bulk of the logic is implemented as part of the library - chartpatterns . The indicator is a shell that captures the user inputs and makes use of the library to deliver the outcome.
🎯 Here is the list of steps executed to identify the patterns on the chart.
Derive multi level recursive zigzag for multiple base zigzag length and depth combinations.
For each zigzag and level, check the last 5 pivots or 6 pivots (based on the input setting) for possibility of valid trend line pairs.
If there is a valid trend line pair, then there is pattern.
🎯 Rules for identifying the valid trend line pairs
There should be at least two trend lines that does not intersect between the starting and ending pivots.
The upper trend line should touch all the pivot highs of the last 5 or 6 pivots considered for scanning the patterns
The lower trend line should touch all the pivot lows of the last 5 or 6 pivots considered for scanning the patterns.
None of the candles from starting pivot to ending pivot should fall outside the trend lines (above upper trend line and below lower trend line)
The existence of a valid trend line pair signifies the existence of pattern. What type of pattern it is, to identify that we need to go through the classification rules.
🎲 Process of classification of the patterns.
We need to gather the following information before we classify the pattern.
Direction of upper trend line - rising, falling or flat
Direction of lower trend line - rising, falling or flat
Characteristics of trend line pair - converging, expanding, parallel
🎯 Broader Classifications
Broader classification would include the following types.
🚩 Classification Based on Geometrical Shapes
This includes
Wedges - both trend lines are moving in the same direction. But, the trend lines are either converging or diverging and not parallel to each other.
Triangles - trend lines are moving in different directions. Naturally, they are either converging or diverging.
Channels - Both trend lines are moving in the same direction, and they are parallel to each other within the limits of error.
🚩 Classification Based on Pattern Direction
This includes
Ascending/Rising Patterns - No trend line is moving in the downward direction and at least one trend line is moving upwards
Descending/Falling Patterns - No trend line is moving in the upward direction, and at least one trend line is moving downwards.
Flat - Both Trend Lines are Flat
Bi-Directional - Both trend lines are moving in opposite direction and none of them is flat.
🚩 Classification Based on Formation Dynamics
This includes
Converging Patterns - Trend Lines are converging towards each other
Diverging Patterns - Trend Lines are diverging from each other
Parallel Patterns - Trend Lines are parallel to each others
🎯 Individual Pattern Types
Now we have broader classifications. Let's go through in detail to find out fine-grained classification of each individual patterns.
🚩 Ascending/Uptrend Channel
This pattern belongs to the broader classifications - Ascending Patterns, Parallel Patterns and Channels. The rules for the Ascending/Uptrend Channel pattern are as below
Both trend lines are rising
Trend lines are parallel to each other
🚩 Descending/Downtrend Channel
This pattern belongs to the broader classifications - Descending Patterns, Parallel Patterns and Channels. The rules for the Descending/Downtrend Channel pattern are as below
Both trend lines are falling
Trend lines are parallel to each other
🚩 Ranging Channel
This pattern belongs to the broader classifications - Flat Patterns, Parallel Patterns and Channels. The rules for the Ranging Channel pattern are as below
Both trend lines are flat
Trend lines are parallel to each other
🚩 Rising Wedge - Expanding
This pattern belongs to the broader classifications - Rising Patterns, Diverging Patterns and Wedges. The rules for the Expanding Rising Wedge pattern are as below
Both trend lines are rising
Trend Lines are diverging.
🚩 Rising Wedge - Contracting
This pattern belongs to the broader classifications - Rising Patterns, Converging Patterns and Wedges. The rules for the Contracting Rising Wedge pattern are as below
Both trend lines are rising
Trend Lines are converging.
🚩 Falling Wedge - Expanding
This pattern belongs to the broader classifications - Falling Patterns, Diverging Patterns and Wedges. The rules for the Expanding Falling Wedge pattern are as below
Both trend lines are falling
Trend Lines are diverging.
🚩 Falling Wedge - Contracting
This pattern belongs to the broader classifications - Falling Patterns, Converging Patterns and Wedges. The rules for the Converging Falling Wedge are as below
Both trend lines are falling
Trend Lines are converging.
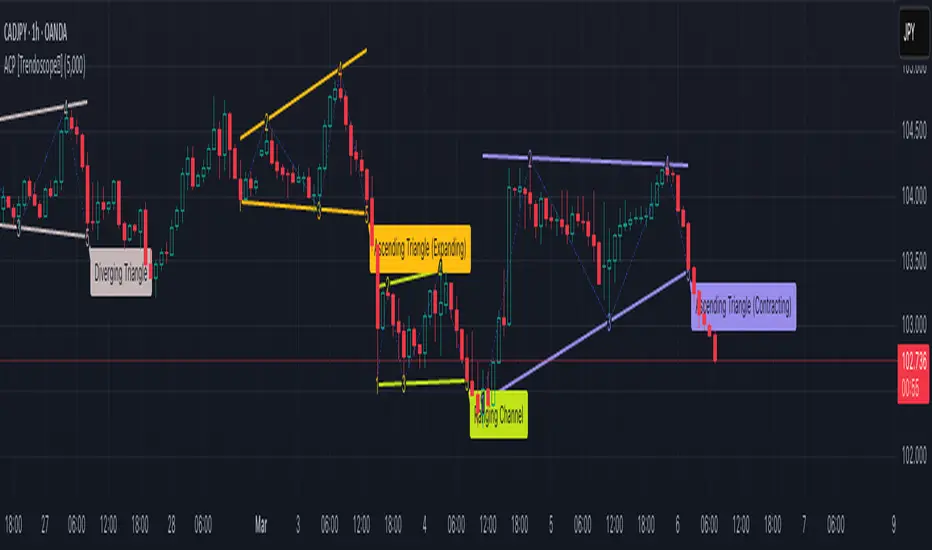
🚩 Rising/Ascending Triangle - Expanding
This pattern belongs to the broader classifications - Rising Patterns, Diverging Patterns and Triangles. The rules for the Expanding Ascending Triangle pattern are as below
The upper trend line is rising
The lower trend line is flat
Naturally, the trend lines are diverging from each other
🚩 Rising/Ascending Triangle - Contracting
This pattern belongs to the broader classifications - Rising Patterns, Converging Patterns and Triangles. The rules for the Contracting Ascending Triangle pattern are as below
The upper trend line is flat
The lower trend line is rising
Naturally, the trend lines are converging.
🚩 Falling/Descending Triangle - Expanding
This pattern belongs to the broader classifications - Falling Patterns, Diverging Patterns and Triangles. The rules for the Expanding Descending Triangle pattern are as below
The upper trend line is flat
The lower trend line is falling
Naturally, the trend lines are diverging from each other
🚩 Falling/Descending Triangle - Contracting
This pattern belongs to the broader classifications - Falling Patterns, Converging Patterns and Triangles. The rules for the Contracting Descending Triangle pattern are as below
The upper trend line is falling
The lower trend line is flat
Naturally, the trend lines are converging.
🚩 Converging Triangle
This pattern belongs to the broader classifications - Bi-Directional Patterns, Converging Patterns and Triangles. The rules for the Converging Triangle pattern are as below
The upper trend line is falling
The lower trend line is rising
Naturally, the trend lines are converging.
🚩 Diverging Triangle
This pattern belongs to the broader classifications - Bi-Directional Patterns, Diverging Patterns and Triangles. The rules for the Diverging Triangle pattern are as below
The upper trend line is rising
The lower trend line is falling
Naturally, the trend lines are diverging from each other.
🎲 Indicator Settings - Auto Chart Patterns
🎯 Zigzag Settings
Zigzag settings allow users to select the number of zigzag combinations to be used for pattern scanning, and also allows users to set zigzag length and depth combinations.
🎯 Scanning Settings
Number of Pivots - This can be either 5 or 6. Represents the number of pivots used for identification of patterns.
Error Threshold - Error threshold used for initial trend line validation.
Flat Threshold - Flat angle threshold is used to identify the slope and direction of trend lines.
Last Pivot Direction - Filters patterns based on the last pivot direction. The values can be up, down, both, or custom. When custom is selected, then the individual pattern specific last pivot direction setting is used instead of the generic one.
Verify Bar Ratio - Provides option to ignore extreme patterns where the ratios of zigzag lines are not proportionate to each other.
Avoid Overlap - When selected, the patterns that overlap with existing patterns will be ignored while scanning. Meaning, if the new pattern starting point falls between the start and end of an existing pattern, it will be ignored.
🎯 Group Classification Filters
Allows users to enable disable patterns based on group classifications.
🚩 Geometric Shapes Based Classifications
Wedges - Rising Wedge Expanding, Falling Wedge Expanding, Rising Wedge Contracting, Falling Wedge Contracting.
Channels - Ascending Channel, Descending Channel, Ranging Channel
Triangles - Converging Triangle, Diverging Triangle, Ascending Triangle Expanding, Descending Triangle Expanding, Ascending Triangle Contrcting and Descending Triangle Contracting
🚩 Direction Based Classifications
Rising - Rising Wedge Contracting, Rising Wedge Expanding, Ascending Triangle Contracting, Ascending Triangle Expanding and Ascending Channel
Falling - Falling Wedge Contracting, Falling Wedge Expanding, Descending Triangle Contracting, Descending Triangle Expanding and Descending Channel
Flat/Bi-directional - Ranging Channel, Converging Triangle, Diverging Triangle
🚩 Formation Dynamics Based Classifications
Expanding - Rising Wedge Expanding, Falling Wedge Expanding, Ascending Triangle Expanding, Descending Triangle Expanding, Diverging Triangle
Contracting - Rising Wedge Contracting, Falling Wedge Contracting, Ascending Triangle Contracting, Descending Triangle Contracting, Converging Triangle
Parallel - Ascending Channel, Descending Channgel and Ranging Channel
🎯 Individual Pattern Filters
These settings allow users to enable/disable individual patterns and also set last pivot direction filter individually for each pattern. Individual Last Pivot direction filters are only considered if the main "Last Pivot Direction" filter is set to "custom"
🎯 Display Settings
These are the settings that determine the indicator display. The details are provided in the tooltips and are self explanatory.
🎯 Alerts
A basic alert message is enabled upon detection of new pattern on the chart.
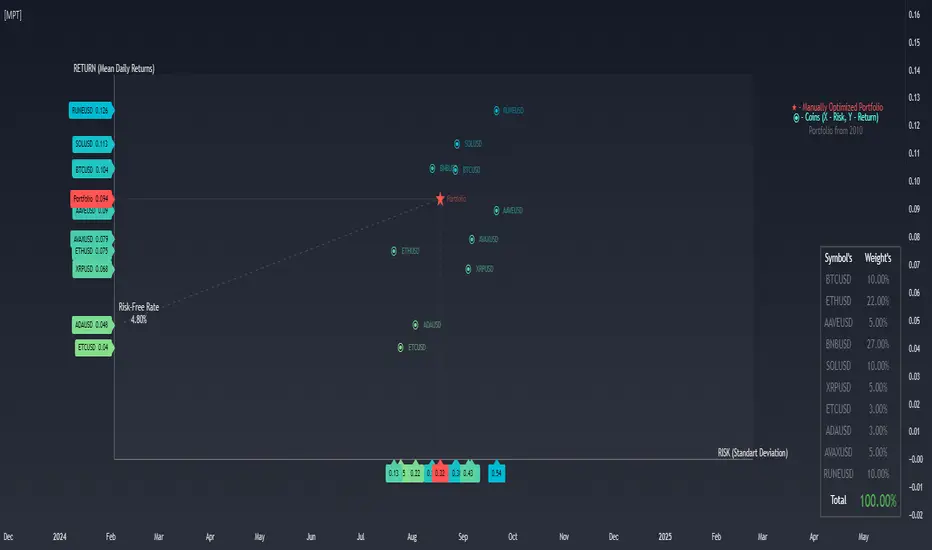
Modern Portfolio TheoryModern Portfolio Theory
The indicator is designed to apply the principles of Modern Portfolio Theory, a financial theory developed by Harry Markowitz. MPT aims to maximize portfolio returns for a given level of risk by diversifying investments.
User Inputs:
Users can customize various parameters, including the bar scale, risk-free rate, and the start year for the portfolio. Additionally, users can assign weights to different assets (symbols) in the portfolio.
Asset Selection:
Users can choose up to 10 different symbols (assets) for the portfolio. The script supports a variety of symbols, including cryptocurrencies such as BTCUSD and ETHUSD.
Weights and Allocation:
Users can assign weights to each selected asset, determining its percentage allocation in the portfolio. The script calculates the total portfolio weight to ensure it equals 100%. If total portfolio weight is lower then 100% you will see orange color with additional cash % bellow
If total portfolio weight is bigger then 100% you will see red big % warning.
Warning: (Total Weight must be 100%)
Cash Mode:
Risk and Return Calculation:
The script calculates the daily returns and standard deviation for each selected asset. These metrics are essential for assessing the risk and return of each asset, as well as the overall portfolio.
Scatter Plot Visualization:
The indicator includes a scatter plot that visualizes the risk-return profile of each asset. Each point on the plot represents an asset, and its position is determined by its risk (X-axis) and return (Y-axis).
Portfolio Optimization:
The script calculates the risk and return of the overall portfolio based on the selected assets and their weights. Based on the selected assets and their weights user can create optimal portfolio with preferable risk and return.
It then plots the portfolio point on the scatter plot, indicating its risk-return profile.
Additional Information:
The indicator provides a table displaying information about each selected asset, including its symbol, weight, and total portfolio weight. The table also shows the total portfolio weight and, if applicable, the percentage allocated to cash.
Visualization and Legend:
The script includes visual elements such as a legend, capital allocation line (CAL), and labels for risk-free rate and key information. This enhances the overall understanding of the portfolio's risk and return characteristics.
User Guidance:
The script provides informative labels and comments to guide users through the interpretation of the scatter plot, risk-return axes, and other key elements.
Interactivity:
Users can interact with the indicator on the TradingView platform, exploring different asset combinations and weightings to observe the resulting changes in the portfolio's risk and return.
In summary, this Pine Script serves as a comprehensive tool for traders and investors interested in applying Modern Portfolio Theory principles to optimize their portfolio allocations based on individual asset characteristics, risk preferences, and return
[MAD] Acceleration based dampened SMA projectionsThis indicator utilizes concepts of arrays inside arrays to calculate and display projections of multiple Smoothed Moving Average (SMA) lines via polylines.
This is partly an experiment as an educational post, on how to work with multidimensional arrays by using User-Defined Types
------------------
Input Controls for User Interaction:
The indicator provides several input controls, allowing users to adjust parameters like the SMA window, acceleration window, and dampening factors.
This flexibility lets users customize the behavior and appearance of the indicator to fit their analysis needs.
sma length:
Defines the length of the simple moving average (SMA).
acceleration window:
Sets the window size for calculating the acceleration of the SMA.
Input Series:
Selects the input source for calculating the SMA (typically the closing price).
Offset:
Determines the offset for the input source, affecting the positioning of the SMA. Here it´s possible to add external indicators like bollinger bands,.. in that case as double sma this sma should be very short.
(Thanks Fikira for that idea)
Startfactor dampening:
Initial dampening factor for the polynomial curve projections, influencing their starting curvature.
Growfactor dampening:
Growth rate of the dampening factor, affecting how the curvature of the projections changes over time.
Prediction length:
Sets the length of the projected polylines, extending beyond the current bar.
cleanup history:
Boolean input to control whether to clear the previous polyline projections before drawing new ones.
Key technologies used in this indicator include:
User-Defined Types (UDT) :
This indicator uses UDT to create a custom type named type_polypaths.
This type is designed to store information for each polyline, including an array of points (array), a color for the polyline, and a dampening factor.
UDTs in Pine Script enable the creation of complex data structures, which are essential for organizing and manipulating data efficiently.
type type_polypaths
array polyline_points = na
color polyline_color = na
float dampening_factor= na
Arrays and Nested Arrays:
The script heavily utilizes arrays.
For example, it uses a color array (colorpreset) to store different colors for the polyline.
Moreover, an array of type_polypaths (polypaths) is used, which is an array consisting of user-defined types. Each element of this array contains another array (polyline_points), demonstrating nested array usage.
This structure is essential for handling multiple polylines, each with its set of points and attributes.
var type_polypaths polypaths = array.new()
Polyline Creation and Manipulation:
The core visual aspect of the indicator is the creation of polylines.
Polyline points are calculated based on a dampened polynomial curve, which is influenced by the SMA's slope and acceleration.
Filling initial dampening data
array_size = 9
middle_index = math.floor(array_size / 2)
for i = 0 to array_size - 1
damp_factor = f_calculate_damp_factor(i, middle_index, Startfactor, Growfactor)
polyline_color = colorpreset.get(i)
polypaths.push(type_polypaths.new(array.new(0, na), polyline_color, damp_factor))
The script dynamically generates these polyline points and stores them in the polyline_points array of each type_polypaths instance based on those prefilled dampening factors
if barstate.islast or cleanup == false
for damp_factor_index = 0 to polypaths.size() - 1
GET_RW = polypaths.get(damp_factor_index)
GET_RW.polyline_points.clear()
for i = 0 to predictionlength
y = f_dampened_poly_curve(bar_index + i , src_input , sma_slope , sma_acceleration , GET_RW.dampening_factor)
p = chart.point.from_index(bar_index + i - src_off, y)
GET_RW.polyline_points.push(p)
polypaths.set(damp_factor_index, GET_RW)
Polyline Drawout
The polyline is then drawn on the chart using the polyline.new() function, which uses these points and additional attributes like color and width.
for pl_s = 0 to polypaths.size() - 1
GET_RO = polypaths.get(pl_s)
polyline.new(points = GET_RO.polyline_points, line_width = 1, line_color = GET_RO.polyline_color, xloc = xloc.bar_index)
If the cleanup input is enabled, existing polylines are deleted before new ones are drawn, maintaining clarity and accuracy in the visualization.
if cleanup
for pl_delete in polyline.all
pl_delete.delete()
------------------
The mathematics
in the (ABDP) indicator primarily focuses on projecting the behavior of a Smoothed Moving Average (SMA) based on its current trend and acceleration.
SMA Calculation:
The indicator computes a simple moving average (SMA) over a specified window (sma_window). This SMA serves as the baseline for further calculations.
Slope and Acceleration Analysis:
It calculates the slope of the SMA by subtracting the current SMA value from its previous value. Additionally, it computes the SMA's acceleration by evaluating the sum of differences between consecutive SMA values over an acceleration window (acceleration_window). This acceleration represents the rate of change of the SMA's slope.
sma_slope = src_input - src_input
sma_acceleration = sma_acceleration_sum_calc(src_input, acceleration_window) / acceleration_window
sma_acceleration_sum_calc(src, window) =>
sum = 0.0
for i = 0 to window - 1
if not na(src )
sum := sum + src - 2 * src + src
sum
Dampening Factors:
Custom dampening factors for each polyline, which are based on the user-defined starting and growth factors (Startfactor, Growfactor).
These factors adjust the curvature of the projected polylines, simulating various future scenarios of SMA movement.
f_calculate_damp_factor(index, middle, start_factor, growth_factor) =>
start_factor + (index - middle) * growth_factor
Polynomial Curve Projection:
Using the SMA value, its slope, acceleration, and dampening factors, the script calculates points for polynomial curves. These curves represent potential future paths of the SMA, factoring in its current direction and rate of change.
f_dampened_poly_curve(index, initial_value, initial_slope, acceleration, damp_factor) =>
delta = index - bar_index
initial_value + initial_slope * delta + 0.5 * damp_factor * acceleration * delta * delta
damp_factor = f_calculate_damp_factor(i, middle_index, Startfactor, Growfactor)
Have fun trading :-)
Live Economic Calendar by toodegrees⚠️ PLEASE READ ⚠️
Although this indicator is accurate in showcasing live and upcoming News Events, checking the original sources is always suggested. This indicator aims to save Time, but due to limitations it may not be 100% correct 100% of the Time.
Description:
The Live Economic Calendar indicator seamlessly integrates with external news sources to provide real-Time, upcoming, and past financial news directly on your Tradingview chart.
By having a clear understanding of when news are planned to be released, as well as their respective impact, analysts can prepare their weeks and days in advance. These injections of volatility can be harnessed by analysts to support their thesis, or may want to be avoided to ensure higher probability market conditions. Fundamentals and news releases transcend the boundaries of technical analysis, as their effects are difficult to predict or estimate.
Designed for both novice and experienced traders, the Live Economic Calendar indicator enhances your analysis by keeping you informed of the latest and upcoming market-moving news.
This is achieved with three different visual components:
News Table: A dedicated News Table shows the Day of the Week, Date, Time of the Day, Currency, Expected Impact, and News Name for each event (in chronological order). Once a news event has occurred, or the day is over, it will be greyed out – helping to focus on the next upcoming news events.
News Lines: Vertical lines plotted in the future help analysts monitor upcoming news events; vertical lines in the past help analysts spot and backtest previous news events that already occurred.
News Labels: Color-coded news labels will plot once the news events have occurred. This not only gives analysts a minimalistic visual cue, but also retains the information of which news were released at that Time in their tooltips.
Forex Factory Calendar News Feed:
The Forex Factory Data Feed includes news events from January 2007 to the present. The data is updated daily. Please see the Technical Description below for more information.
Forex Factory provides news for all major currencies and markets:
Australia (AUD)
Canada (CAD)
Switzerland (CHF)
China (CNY)
European Union (EUR)
United Kingdom (GBP)
Japan (JPY)
New Zealand (NZD)
United States of America (USD)
Further, there are four types of news impact, defined by respective color-coding which is retained to avoid confusion:
⚪ Holiday
🟡 Low Impact
🟠 Medium Impact
🔴 High Impact
News' Time of the day data is in 24H format, and 'All Day' news are marked at Daily candle open.
⚠️ Original Release Notes ⚠️
The original release of this indicator supports the Forex Factory News Calendar in EST (New York Time). Future updates will include multiple news sources, as well as supporting different Timezones.
Given Data limitations, the Daily chart can omit some data due to the market being close on some days. This will be fixed in the future once an efficient solution is implemented.
Key Features:
Impact-Based News Filtering: Filter news items based on their expected impact (holiday, low, medium, high) to focus on the most market-critical information.
Symbol-Specific News: Automatically filter news to display only what's relevant to the currency pair or trading symbol you are analyzing.
Custom Currency News: Want to see more than the news relevant to the current symbol? Toggle which markets' news you are most interested in.
Chart History: Keep your charts clean by displaying only the drawings of Today's news, or This Week's news.
Custom Lookback: Look further back in Time by choosing a custom number of Lookback Days, allowing you to backtest and keep in mind salient news events from the past.
Line and Label Customization: Both the News Lines and Labels are highly customizable (except the colors), allowing you to make the indicator yours.
Table History: Choose whether to focus on Today's news only, or the news for This Week.
Table Customization: The table colors and position are highly customizable, allowing you to make it fit your visual preference and your layouts' aesthetic.
"Wondering how it's done? 👇"
Technical Description:
This script utilizes Pine Seeds , a service integrated with TradingView for importing custom data. This stunning feature enables users to upload and access custom End Of Day (EOD) data, which can be updated as frequently as five times daily.
This data can be imported in one of two formats:
Single Value: integer or float
Candle Data: open, high, low, close, volume
Upon encountering Pine Seeds, I recognized its potential for importing financial news events. Given that Forex Factory is a primary source of financial news in my personal analysis, integrating it into my layouts seemed like an exciting opportunity. This integration is expected to provide significant value to users looking to integrate additional news feeds all in one place.
Development Challenges:
Format Limitations: News events must be converted into numerical values for import, due to the required Pine Seeds format.
Amount of Data: With all currencies considered, the system may encounter over 40 news events in a single day.
Data Availability: The reliance on End Of Day (EOD) data means that information for the current day is displayed with a delay, and accessing future data is not possible.
Solutions:
Encoding: Each news event is encoded as an integer in the "DCHHMMITYP" format.
D = day of the week
C = currency
HHMM = Time of day
I = news impact
TYP = event ID (see Event Library A and Event Library B )
To ensure data assignment for each candle across the open, high, low, close, and volume series, the value "999" is used as a placeholder:
Importing: Utilizing the encoding system, up to five news events per day can be imported for a singular Pine Seeds custom symbol.
By creating multiple custom Pine Seeds Symbols, efficient imports of a larger number of events is then easily achievable. Nine unique symbols have been established, accommodating up to 45 news events per day.
These symbols are searchable, and accessible as " TOODEGREES_FOREX_FACTORY_SLOT_N " where N ranges from 1 to 9.
The Pine Seeds data feed appears as follows:
Uploading Schedule: To ensure analysts are informed about current and upcoming week's news, events are uploaded one week in advance.
This approach is vital for preparing for potential market impacts across various asset classes and currencies, allowing visibility of an entire week's news ahead of Time.
Data Scraping:
Unfortunately Forex Factory doesn't offer an API to fetch their news feed.
Hence an ad hoc python scraper was developed to read and save news events from January 2007 till the present leveraging Selenium. The scraper algorithm is part of a larger script responsible for scraping data, formatting data, and creating all necessary datasets.
The pseudo-code for the python script is as follows:
Read and save news event data on Forex Factory
Format day of the week, currency, Time of the day, and impact data for the Encoding
Encode and save News Event IDs – Event ID dataset is created
Format news data for Pine Seeds (roll-back date by one week, assign news to open, high, low, close, and volume values)
Create Pine Seeds Datasets
This script is ran everyday at Futures market close (16:00 EST) to update the last part of the each dataset, ensuring accuracy, and taking into account last-minute news additions or revisions.
Once the data (next week's news) is imported by the Live Economic Calendar indicator, it's immediately decoded by leveraging the Forex Factory Decoding Library , and saved into an array.
Upon a new week open, the decoded data is used to plot news events on the chart and in the news table.
See the inner workings of these processes in the Forex Factory Utility Library .
Although these libraries are specifically built for this indicator, feel free to use them to create your own scripts. Looking forward to see what the Pine Script community comes up with!
Thank you for making it this far. Enjoy!
Ciao,
toodegrees
This tool is available ONLY on the TradingView platform.
Terms and Conditions
Our charting tools are provided for informational and educational purposes only and do not constitute financial, investment, or trading advice. Our charting tools are not designed to predict market movements or provide specific recommendations. Users should be aware that past performance is not indicative of future results and should not be relied upon for making financial decisions. By using our charting tools, the user agrees that Toodegrees and the Toodegrees Team are not responsible for any decisions made based on the information provided by these charting tools. The user assumes full responsibility and liability for any actions taken and the consequences thereof, including any loss of money or investments that may occur as a result of using these products. Hence, by using these charting tools, the user accepts and acknowledges that Toodegrees and the Toodegrees Team are not liable nor responsible for any unwanted outcome that arises from the development, or the use of these charting tools. Finally, the user indemnifies Toodegrees and the Toodegrees Team from any and all liability.
By continuing to use these charting tools, the user acknowledges and agrees to the Terms and Conditions outlined in this legal disclaimer.
chartpatternsLibrary "chartpatterns"
Library having complete chart pattern implementation
method draw(this)
draws pattern on the chart
Namespace types: Pattern
Parameters:
this (Pattern) : Pattern object that needs to be drawn
Returns: Current Pattern object
method erase(this)
erase the given pattern on the chart
Namespace types: Pattern
Parameters:
this (Pattern) : Pattern object that needs to be erased
Returns: Current Pattern object
method findPattern(this, properties, patterns)
Find patterns based on the currect zigzag object and store them in the patterns array
Namespace types: zg.Zigzag
Parameters:
this (Zigzag type from Trendoscope/ZigzagLite/2) : Zigzag object containing pivots
properties (PatternProperties) : PatternProperties object
patterns (Pattern ) : Array of Pattern objects
Returns: Current Pattern object
PatternProperties
Object containing properties for pattern scanning
Fields:
offset (series int) : Zigzag pivot offset. Set it to 1 for non repainting scan.
numberOfPivots (series int) : Number of pivots to be used in pattern search. Can be either 5 or 6
errorRatio (series float) : Error Threshold to be considered for comparing the slope of lines
flatRatio (series float) : Retracement ratio threshold used to determine if the lines are flat
checkBarRatio (series bool) : Also check bar ratio are within the limits while scanning the patterns
barRatioLimit (series float) : Bar ratio limit used for checking the bars. Used only when checkBarRatio is set to true
avoidOverlap (series bool)
patternLineWidth (series int) : Line width of the pattern trend lines
showZigzag (series bool) : show zigzag associated with pattern
zigzagLineWidth (series int) : line width of the zigzag lines. Used only when showZigzag is set to true
zigzagLineColor (series color) : color of the zigzag lines. Used only when showZigzag is set to true
showPatternLabel (series bool) : display pattern label containing the name
patternLabelSize (series string) : size of the pattern label. Used only when showPatternLabel is set to true
showPivotLabels (series bool) : Display pivot labels of the patterns marking 1-6
pivotLabelSize (series string) : size of the pivot label. Used only when showPivotLabels is set to true
pivotLabelColor (series color) : color of the pivot label outline. chart.bg_color or chart.fg_color are the appropriate values.
allowedPatterns (bool ) : array of bool encoding the allowed pattern types.
themeColors (color ) : color array of themes to be used.
Pattern
Object containing Individual Pattern data
Fields:
pivots (Pivot type from Trendoscope/ZigzagLite/2) : array of Zigzag Pivot points
trendLine1 (Line type from Trendoscope/LineWrapper/1) : First trend line joining pivots 1, 3, 5
trendLine2 (Line type from Trendoscope/LineWrapper/1) : Second trend line joining pivots 2, 4 (, 6)
properties (PatternProperties) : PatternProperties Object carrying common properties
patternColor (series color) : Individual pattern color. Lines and labels will be using this color.
ratioDiff (series float) : Difference between trendLine1 and trendLine2 ratios
zigzagLine (series polyline) : Internal zigzag line drawing Object
pivotLabels (label ) : array containning Pivot labels
patternLabel (series label) : pattern label Object
patternType (series int) : integer representing the pattern type
patternName (series string) : Type of pattern in string
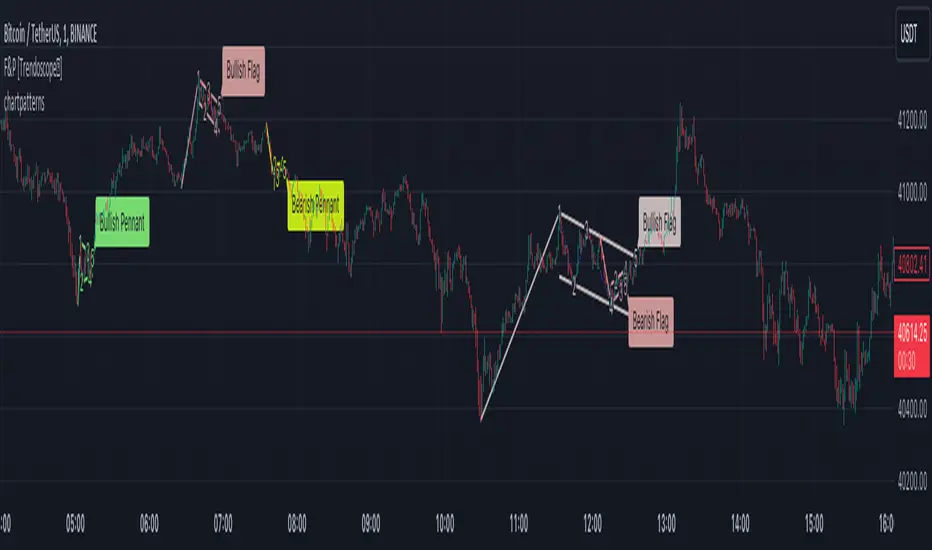
Volume Speed [By MUQWISHI]▋ INTRODUCTION :
The “Volume Dynamic Scale Bar” is a method for determining the dominance of volume flow over a selected length and timeframe, indicating whether buyers or sellers are in control. In addition, it detects the average speed of volume flow over a specified period. This indicator is almost equivalent to Time & Sales (Tape) .
_______________________
▋ OVERVIEW:
_______________________
▋ ELEMENTS
(1) Volume Dynamic Scale Bar. As we observe, it has similar total up and down volume values to what we're seeing in the table. Note they have similar default inputs.
(2) A notice of a significant volume came.
(3) It estimates the speed of the average volume flow. In the tooltip, it shows the maximum and minimum recorded speeds along with the time since the chart was updated.
(4) Info of entered length and the selected timeframe.
(5) The widget will flash gradually for 3 seconds when there’s a significant volume occurred based on the selected timeframe.
_______________________
▋ INDICATOR SETTINGS:
(1) Timezone.
(2) Widget location and size on chart.
(3) Up & Down volume colors.
(4) Option to enable a visual flash when a single volume is more than {X value} of Average. For instance, 2 → means double the average volume.
(5) Fetch data from the selected lower timeframe.
(6) Number of bars at chosen timeframe.
(7) Volume OR Price Volume.
_____________________
▋ COMMENT:
The Volume Dynamic Scale Bar should not be taken as a major concept to build a trading decision.
Please let me know if you have any questions.
Thank you.
Christmas Toolkit [LuxAlgo]It's that time of the year... and what would be more appropriate than displaying Christmas-themed elements on your chart?
The Christmas Toolkit displays a tree containing elements affected by various technical indicators. If you're lucky, you just might also find a precious reindeer trotting toward the tree, how fancy!
🔶 USAGE
Each of the 7 X-mas balls is associated with a specific condition.
Each ball has a color indicating:
lime: very bullish
green: bullish
blue: holding the same position or sideline
red: bearish
darkRed: very bearish
From top to bottom:
🔹 RSI (length 14)
rsi < 20 - lime (+2 points)
rsi < 30 - green (+1 point)
rsi > 80 - darkRed (-2 points)
rsi > 70 - red (-1 point)
else - blue
🔹 Stoch (length 14)
stoch < 20 - lime (+2 points)
stoch < 30 - green (+1 point)
stoch > 80 - darkRed (-2 points)
stoch > 70 - red (-1 point)
else - blue
🔹 close vs. ema (length 20)
close > ema 20 - green (+1 point)
else - red (-1 point)
🔹 ema (length 20)
ema 20 rises - green (+1 point)
else - red (-1 point)
🔹 ema (length 50)
ema 50 rises - green (+1 point)
else - red (-1 point)
🔹 ema (length 100)
ema 100 rises - green (+1 point)
else - red (-1 point)
🔹 ema (length 200)
ema 200 rises - green (+1 point)
else - red (-1 point)
The above information can also be found on the right side of the tree.
You'll see the conditions associated with the specific X-mas ball and the meaning of color changes. This can also be visualized by hovering over the labels.
All values are added together, this result is used to color the star at the top of the tree, with a specific color indicating:
lime: very bullish (> 6 points)
green: bullish (6 points)
blue: holding the same position or sideline
red: bearish (-6 points)
darkRed: very bearish (< -6 points)
Switches to green/lime or red/dark red can be seen by the fallen stars at the bottom.
The Last Switch indicates the latest green/lime or red/dark red color (not blue)
🔶 ANIMATION
Randomly moving snowflakes are added to give it a wintry character.
There are also randomly moving stars in the tree.
Garland rotations, style, and color can be adjusted, together with the width and offset of the tree, put your tree anywhere on your chart!
Disabling the "static tree" setting will make the needles 'move'.
Have you happened to see the precious reindeer on the right? This proud reindeer moves towards the most recent candle. Who knows what this reindeer might be bringing to the tree?
🔶 SETTINGS
Width: Width of tree.
Offset: Offset of the tree.
Garland rotations: Amount of rotations, a high number gives other styles.
Color/Style: sets the color & style of garland stars.
Needles: sets the needle color.
Static Tree: Allows the tree needles to 'move' with each tick.
Reindeer Speed: Controls how fast the deer moves toward the most recent bar.
🔶 MESSAGE FROM THE LUXALGO TEAM
It has been an honor to contribute to the TradingView community and we are always so happy to see your supportive messages on our scripts.
We have posted a total of 78 script publications this year, which is no small feat & was only possible thanks to our team of Wizard developers @alexgrover + @dgtrd + @fikira , the development team behind Pine Script, and of course to the support of our legendary community.
Happy Holidays to you all, and we'll see ya next year! ☃️

GuageLibrary "Gauge"
The gauge library utilizes a gaugeParams object, encapsulating crucial parameters for gauge creation. Essential attributes include num (the measured value) , min (the minimum value equating to 100% on the gauge's minimum scale) , and max (the maximum value equating to 100% on the gauge's maximum scale) . The size attribute (defaulting to 10) splits the scale into increments, each representing 100% divided by the specified size.
The num value dynamically shifts within the gauge based on its percentage move from the mathematical average between min and max . When num is below the average, the minimum portion of the scale activates, displaying the appropriate percentage based on the distance from the average to the minimum. The same principle applies when num exceeds the average. The 100% scale is reached at either end when num equals min or max .
The library offers full customization, allowing users to configure color schemes, labels, and titles. The gauge can be displayed either vertically (default) or horizontally. The colors employ a gradient, adapting based on the number's movement. Overall, the gauge library provides a flexible and comprehensive tool for visualizing and interpreting numerical values within a specified range.