Sessioned EMA - Frozen EMA in post market hoursWhy I develop this indicator?
In future indices, post market data with little volume distort the moving average seriously. This indicator is to eliminate the distortion of data during low volume post market hours.
How to use?
There is a time session setting in the indicator, you can set the cash hour time, moving average outside the session will be frozen.
What this indicator gives you
This indicator give you a more make sense ema pattern, the ema lines are more respected by the prices when you set the session properly.
Setup
1. Session setting
In US indices, such as NQ, ES etc, when there was data release at 0830 hr, huge volume transaction order appears, that makes the 0830 price data important that should be included in your ema trend line calculating. If that is the case, I will set the session begin from 0830, otherwise, I start the session at 0930. Golden rule : Price with huge volume counts.
2. Time zone
The coding is decided for GMT+8 time zone, you may amend the code to fit your timezone.
Полосы и каналы

Nadaraya-Watson Envelope (Non-Repainting) Logarithmic ScaleIn the fast-paced world of trading, having a reliable and accurate indicator can make all the difference. Enter the Nadaraya-Watson Envelope Indicator, a cutting-edge tool designed to provide traders with valuable insights into market trends and potential price movements. In this article, we'll explore the advantages of this non-repainting indicator and how it can empower traders to make informed decisions with confidence.
Accurate Price Analysis:
The Nadaraya-Watson Envelope Indicator operates in a logarithmic scale, allowing for more accurate price analysis. By considering the logarithmic nature of price movements, this indicator captures the subtle nuances of market dynamics, providing a comprehensive view of price action. Traders can leverage this advantage to identify key support and resistance levels, spot potential breakouts, and anticipate trend reversals.
Non-Repainting Reliability:
One of the most significant advantages of the Nadaraya-Watson Envelope Indicator is its non-repainting nature. Repainting indicators can mislead traders by changing historical signals, making it difficult to evaluate past performance accurately. With the non-repainting characteristic of this indicator, traders can have confidence in the reliability and consistency of the signals generated, ensuring more accurate backtesting and decision-making.
Customizable Parameters:
Every trader has unique preferences and trading styles. The Nadaraya-Watson Envelope Indicator offers a range of customizable parameters, allowing traders to fine-tune the indicator to their specific needs. From adjusting the lookback window and relative weighting to defining the start of regression, traders have the flexibility to adapt the indicator to different timeframes and trading strategies, enhancing its effectiveness and versatility.
Envelope Bounds and Estimation:
The Nadaraya-Watson Envelope Indicator calculates upper and lower bounds based on the Average True Range (ATR) and specified factors. These envelope bounds act as dynamic support and resistance levels, providing traders with valuable reference points for potential price targets and stop-loss levels. Additionally, the indicator generates an estimation plot, visually representing the projected price movement, enabling traders to anticipate market trends and make well-informed trading decisions.
Visual Clarity with Plots and Fills:
Clear visualization is crucial for effective technical analysis. The Nadaraya-Watson Envelope Indicator offers plots and fills to enhance visual clarity and ease of interpretation. The upper and lower boundaries are plotted, along with the estimation line, allowing traders to quickly assess price trends and volatility. Fills between the boundaries provide a visual representation of different price regions, aiding in identifying potential trading opportunities and risk management.
Conclusion:
The Nadaraya-Watson Envelope Indicator is a powerful tool for traders seeking accurate and reliable insights into market trends and price movements. With its logarithmic scale, non-repainting nature, customizable parameters, and visual clarity, this indicator equips traders with a competitive edge in the financial markets. By harnessing the advantages offered by the Nadaraya-Watson Envelope Indicator, traders can navigate the complexities of trading with confidence and precision. Unlock the potential of this advanced indicator and elevate your trading strategy to new heights.

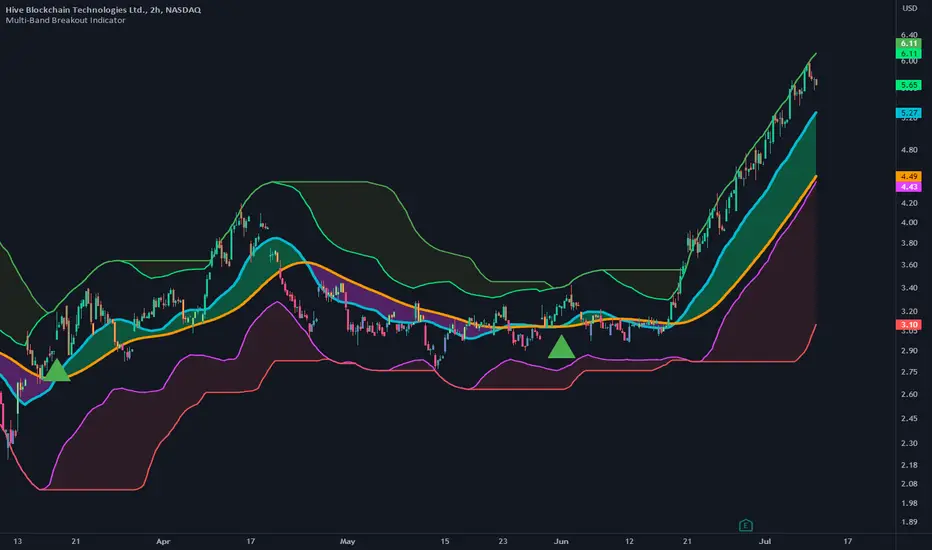
Multi-Band Breakout IndicatorThe Multi-Band Breakout Indicator was created to help identify potential breakout opportunities in the market. It combines multiple bands (ATR-Based and Donchian) and moving averages to provide valuable insights into the underlying trend and potential breakouts. By understanding the calculations, interpretation, parameter adjustments, potential applications, and limitations of the indicator, traders can effectively incorporate it into their trading strategy.
Calculation:
The indicator utilizes several calculations to plot the bands and moving averages. The length parameter determines the period used for the Average True Range (ATR), which measures volatility. A higher length captures a longer-term view of price movement, while a lower length focuses on shorter-term volatility. The multiplier parameter adjusts the distance of the upper and lower bands from the ATR. A higher multiplier expands the bands, accommodating greater price volatility, while a lower multiplier tightens the bands, reflecting lower volatility. The MA Length parameter determines the period for the moving averages used to calculate the trend and trend moving average. A higher MA Length creates a smoother trend line, filtering out shorter-term fluctuations, while a lower MA Length provides a more sensitive trend line.
The Donchian calculations in the Multi-Band Breakout Indicator play a significant role in identifying potential breakout opportunities and providing additional confirmation for trading signals. In this indicator, the Donchian calculations are applied to the trend line, which represents the average of the upper and lower bands. To calculate the Donchian levels, the indicator uses the Donchian Length parameter, which determines the period over which the highest high and lowest low are calculated. A longer Donchian Length captures a broader price range, while a shorter length focuses on more recent price action. By incorporating the Donchian calculations into the Multi-Band Breakout Indicator, traders gain an additional layer of confirmation for breakout signals.
Interpretation:
The Multi-Band Breakout Indicator offers valuable interpretation for traders. The upper and lower bands represent dynamic levels of resistance and support, respectively. These bands reflect the potential price range within which the asset is expected to trade. The trend line is the average of these bands and provides a central reference point for the overall trend. When the price moves above the upper band, it suggests a potential overbought condition and a higher probability of a pullback. Conversely, when the price falls below the lower band, it indicates a potential oversold condition and an increased likelihood of a bounce. The trend moving average further smooths the trend line, making it easier to identify the prevailing direction.
The crossover of the trend line (representing the average of the upper and lower bands) and the trend moving average holds a significant benefit for traders. This crossover serves as a powerful signal for potential trend changes and breakout opportunities in the market. When the trend line crosses above the trend moving average, it suggests a shift in momentum towards the upside, indicating a potential bullish trend. This provides traders with an early indication of a possible upward movement in prices. Conversely, when the trend line crosses below the trend moving average, it indicates a shift in momentum towards the downside, signaling a potential bearish trend. This crossover acts as an early warning for potential downward price movement. By identifying these crossovers, traders can capture the initial stages of a new trend, enabling them to enter trades at favorable entry points and potentially maximize their profit potential.
Breakout Signals:
For bullish breakouts, the indicator looks for a bullish crossover between the trend line and the trend moving average. This crossover suggests a shift in momentum towards the upside. Additionally, it checks if the current price has broken above the upper band and the previous Donchian high. This confirms that the price is surpassing a previous resistance level, indicating further upward movement.
For bearish breakouts, the indicator looks for a bearish crossunder between the trend line and the trend moving average. This crossunder indicates a shift in momentum towards the downside. It also checks if the current price has broken below the lower band and the previous Donchian low. This confirms that the price is breaking through a previous support level, signaling potential downward movement.
When a bullish or bearish breakout is detected, it suggests a potential trading opportunity. Traders may consider initiating positions in the direction of the breakout, anticipating further price movement in that direction. However, it's important to remember that breakouts alone do not guarantee a successful trade. Other factors, such as market conditions, volume, and confirmation from additional indicators, should be taken into account. Risk management techniques should also be implemented to manage potential losses.
Coloration:
The coloration in the Multi-Band Breakout Indicator is used to visually represent different aspects of the indicator and provide valuable insights to traders. Let's break down the coloration components:
-- Trend/Basis Color : The tColor variable determines the color of the bars based on the relationship between the trend line (trend) and the closing price (close), as well as the relationship between the trend line and the trend moving average (trendMA). If the trend line is above the closing price and the trend moving average is also above the closing price, the bars are colored fuchsia, indicating a potential bullish trend. If the trend line is below the closing price and the trend moving average is also below the closing price, the bars are colored lime, indicating a potential bearish trend. If neither of these conditions is met, the bars are colored yellow, representing a neutral or indecisive market condition.
-- Moving Average Color : The maColor variable determines the color of the filled area between the trend line and the trend moving average. If the trend line is above the trend moving average, the area is filled with a lime color with 70% opacity, indicating a potential bullish trend. Conversely, if the trend line is below the trend moving average, the area is filled with a fuchsia color with 70% opacity, indicating a potential bearish trend. This coloration helps traders visually identify the relationship between the trend line and the trend moving average.
-- highColor and lowColor : The highColor and lowColor variables determine the colors of the high Donchian band (hhigh) and the low Donchian band (llow), respectively. These bands represent dynamic levels of resistance and support. If the highest point in the previous Donchian period (hhigh) is above the upper band, the highColor is set to olive with 90% opacity, indicating a potential resistance level. On the other hand, if the lowest point in the previous Donchian period (llow) is below the lower band, the lowColor is set to red with 90% opacity, suggesting a potential support level. These colorations help traders quickly identify important price levels and assess their significance in relation to the bands.
By incorporating coloration, the Multi-Band Breakout Indicator provides visual cues to traders, making it easier to interpret the relationships between various components and assisting in identifying potential trend changes and breakout opportunities. Traders can use these color cues to quickly assess the prevailing market conditions and make informed trading decisions.
Adjusting Parameters:
The Multi-Band Breakout Indicator offers flexibility through parameter adjustments. Traders can customize the indicator based on their preferences and trading style. The length parameter controls the sensitivity to price changes, with higher values capturing longer-term trends, while lower values focus on shorter-term price movements. By adjusting the parameters, such as the ATR length, multiplier, Donchian length, and MA length, traders can customize the indicator to suit different timeframes and trading strategies. For shorter timeframes, smaller values for these parameters may be more suitable, while longer timeframes may require larger values.
Potential Applications:
The Multi-Band Breakout Indicator can be applied in various trading strategies. It helps identify potential breakout opportunities, allowing traders to enter trades in the direction of the breakout. Traders can use the indicator to initiate trades when the price moves above the upper band or below the lower band, confirming a potential breakout and providing a signal to enter a trade. Additionally, the indicator can be combined with other technical analysis tools, such as support and resistance levels, candlestick patterns, or trend indicators, to increase the probability of successful trades. By incorporating the Multi-Band Breakout Indicator into their trading approach, traders can gain a better understanding of market trends and capture potential profit opportunities.
Limitations:
While the Multi-Band Breakout Indicator is a useful tool, it has some limitations that traders should consider. The indicator performs best in trending markets where price movements are relatively strong and sustained. During ranging or choppy market conditions, the indicator may generate false signals, leading to potential losses. It is crucial to use the indicator in conjunction with other analysis techniques and risk management strategies to enhance its effectiveness. Additionally, traders should consider external factors such as market news, economic events, and overall market sentiment when interpreting the signals generated by the indicator.
By combining multiple bands and moving averages, this indicator offers valuable insights into the underlying trend and helps traders make informed trading decisions. With customization options and careful interpretation, this indicator can be a valuable addition to any trader's toolkit, assisting in identifying potential breakouts, capturing profitable trades, and enhancing overall trading performance.
RAINBOW AVERAGES - INDICATOR - (AS) - 1/3
-INTRODUCTION:
This is the first of three scripts I intend to publish using rainbow indicators. This script serves as a groundwork for the other two. It is a RAINBOW MOVING AVERAGES indicator primarily designed for trend detection. The upcoming script will also be an indicator but with overlay=false (below the chart, not on it) and will utilize RAINBOW BANDS and RAINBOW OSCILLATOR. The third script will be a strategy combining all of them.
RAINBOW moving averages can be used in various ways, but this script is mainly intended for trend analysis. It is meant to be used with overlay=true, but if the user wishes, it can be viewed below the chart. To achieve this, you need to change the code from overlay=true to false and turn off the first switch that plots the rainbow on the chart (or simply move the indicator to a new pane below). By doing this, you will be able to see how all four conditions used to detect trends work on the chart. But let's not get ahead of ourselves.
-WHAT IS IT:
In its simplest form, this indicator uses 10 moving averages colored like a rainbow. The calculation is as follows:
MA0: This is the main moving average and can be defined with the type (SMA, EMA, RMA, WMA, SINE), length, and price source. However, the second moving average (MA1) is calculated using MA0 as its source, MA2 uses MA1 as the data source, and so on, until the last one, MA9. Hence, there are 10 moving averages. The first moving average is special as all the others derive from it. This indicator has many potential uses, such as entry/exit signals, volatility indication, and stop-loss placement, but for now, we will focus on trend detection.
-TREND DETECTION:
The indicator offers four different background color options based on the user's preference:
0-NONE: No background color is applied as no trend detection tools is being used (boring)
1-CHANGE: The background color is determined by summing the changes of all 10 moving averages (from two bars). If the sum is positive and not falling, the background color is GREEN. If the sum is negative and not rising, the background color is RED. From early testing, it works well for the beginning of a movement but not so much for a lasting trend.
2-RAINBW: The background color is green when all the moving averages are in ascending order, indicating a bullish trend. It is red when all the moving averages are in descending order, indicating a bearish trend. For example, if MA1>MA2>MA3>MA4..., the background color is green. If MA1 threshold, and red indicates width < -threshold.
4-DIRECT: The background color is determined by counting the number of moving averages that are either above or below the input source. If the specified number of moving averages is above the source, the background color is green. If the specified number of moving averages is below the source, the background color is red. If all ten MAs are below the price source, the indicator will show 10, and if all ten MAs are above, it will show -10. The specific value will be set later in the settings (same for 3-TSHOLD variant). This method works well for lasting trends.
Note: If the indicator is turned into a below-chart version, all four color options can be seen as separate indicators.
-PARAMETERS - SETTINGS:
The first line is an on/off switch to plot the skittles indicator (and some info in the tooltip). The second line has already been discussed, which is the background color and the selection of the source (only used for MA0!).
The line "MA1: TYP/LEN" is where we define the parameters of MA0 (important). We choose from the types of moving averages (SMA, EMA, RMA, WMA, SINE) and set the length.
Important Note: It says MA1, but it should be MA0!.
The next line defines whether we want to smooth MA1 (which is actually MA0) and the period for smoothing. When smoothing is turned on, MA0 will be smoothed using a 3-pole super smoother. It's worth noting that although this only applies to MA0, as the other MAs are derived from it, they will also be smoothed.
In the line below, we define the type and length of MAs for MA2 (and other MAs except MA0). The same type and length are used for MA1 to MA9. It's important to remember that these values should be smaller. For example, if we set 55, it means that MA1 is the average of 55 periods of MA0, MA2 will be 55 periods of MA1, and so on. I encourage trying different combinations of MA types as it can be easily adjusted for ur type of trading. RMA looks quirky.
Moving on to the last line, we define some inputs for the background color:
TSH: The threshold value when using 3-TSHOLD-BGC. It's a good idea to change the chart to a pane below for easier adjustment. The default values are based on EURUSD-5M.
BG_DIR: The value that must be crossed or equal to the MA score if using 4-DIRECT-BGC. There are 10 MAs, so the maximum value is also 10. For example, if you set it to 9, it means that at least 9 MAs must be below/above the price for the script to detect a trend. Higher values are recommended as most of the time, this indicator oscillates either around the maximum or minimum value.
-SUMMARY OF SETTINGS:
L1 - PLOT MAs and general info tooltip
L2 - Select the source for MA0 and type of trend detection.
L3 - Set the type and length of MA0 (important).
L4 - Turn smoothing on/off for MA0 and set the period for super smoothing.
L5 - Set the type and length for the rest of the MAs.
L6 - Set values if using 4-DIRECT or 3-TSHOLD for the trend detection.
-OTHERS:
To see trend indicators, you need to turn off the plotting of MAs (first line), and then choose the variant you want for the background color. This will plot it on the chart below.
Keep in mind that M1 int settings stands for MA0 and MA2 for all of the 9 MAs left.
Yes, it may seem more complicated than it actually is. In a nutshell, these are 10 MAs, and each one after MA0 uses the previous one as its source. Plus few conditions for range detection. rest is mainly plots and colors.
There are tooltips to help you with the parameters.
I hope this will be useful to someone. If you have any ideas, feedback, or spot errors in the code, LET ME KNOW.
Stay tuned for the remaining two scripts using skittles indicators and check out my other scripts.
-ALSO:
I'm always looking for ideas for interesting indicators and strategies that I could code, so if you don't know Pinescript, just message me, and I would be glad to write your own indicator/strategy for free, obviously.
-----May the force of the market be with you, and until we meet again,

StdDev ChannelsThis script draws two sets of standard deviation channels on the price chart, providing a nuanced view of price volatility over different lengths.
The script starts by declaring a set of user-defined inputs allowing traders to customize the tool according to their individual requirements. The price input sets the source of the price data, defaulting to the closing price but customizable to use open, high, or low prices. The deviations parameter defines the width of the channels, with larger numbers resulting in wider channels. The length and length2 inputs represent the number of periods (in bars) that the script considers when calculating the regression line and standard deviation. Traders can also personalize the visual aspects of the indicator on the chart using the color, linewidth, and linestyle parameters.
Calculation of Standard Deviation:
The core of this script lies in calculating the regression line and standard deviation. This is where the InertiaAll function comes into play. This function calculates the linear regression line, which serves as the middle line of each channel. The function takes in two parameters: y (price data) and n (length for calculation). It returns an array containing the values for the regression line (InertiaTS), counter variable (x), slope of the line (a), and y-intercept (b). The standard deviation is then calculated using the built-in function ta.stdev, which measures the amount of variation or dispersion from the average.
After the calculation, the script proceeds to draw the channels. It creates two sets of lines (upper, middle, and lower) for each channel. These lines are initialized at the lowest price point on the chart (low). The coordinates for these lines get updated in the last section of the script, which runs only on the last bar on the chart (if barstate.islast). The functions line.set_xy1 and line.set_xy2 are used to adjust the starting and ending points for each line, forming the channels.
If the "full range" toggle is enabled, the script uses the maximum number of bars available on the chart to calculate the regression and standard deviation. This can give a broader perspective of the price's volatility over the entire available data range.
A Basic Strategy
The channels generated by this script may inform your trading decisions. If the price hits the upper line of a channel, it could suggest an 'overbought' condition indicating a potential selling opportunity. Conversely, if the price hits the lower line, it might signal an 'oversold' condition, suggesting a buying opportunity. The second channel, calculated over a different length, may serve to confirm these signals or identify longer-term trends.

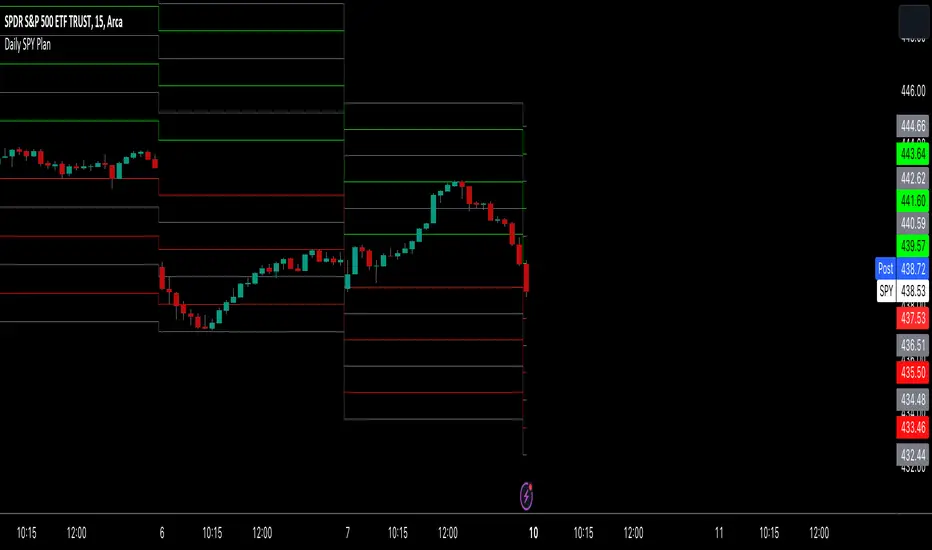
Daily SPY PlanThe Daily SPY Plan indicator is a technical analysis tool designed to provide traders with a visual representation of price levels and take profit points for the SPY (S&P 500 ETF) on a daily timeframe. This indicator utilizes the Average True Range (ATR) to calculate projected price levels and take profit points, aiding traders in identifying potential breakout and profit-taking opportunities.
Indicator Description:
The indicator is written in Pine Script, specifically for use on the TradingView platform. It plots several levels on the price chart, each representing a potential breakout or take profit point. The levels are determined based on a fraction of the ATR added or subtracted from the closing price. The fractions used are 0.25, 0.5, 0.75, 1.0, 1.25, and 1.5 times the ATR.
The indicator distinguishes between breakout levels and take profit levels using different colors. Breakout levels, which indicate potential entry or exit points, are displayed in green, while take profit levels are shown in gray.
Key Features and Use:
ATR Calculation: The indicator calculates the Average True Range (ATR) using a specified length (default value of 14). ATR is a measure of market volatility and represents the average range between the high and low prices over a specific period.
Projected Price Levels: The indicator plots several projected price levels above and below the closing price. These levels are calculated by adding or subtracting a fraction of the ATR from the closing price. Traders can use these levels as potential breakout points or areas to set stop-loss orders.
Take Profit Points: The indicator also plots take profit points at specific levels above and below the closing price. These levels are designed to help traders identify potential areas to secure profits or partially exit their positions.
Visual Representation: The indicator utilizes step-like lines to plot the projected price levels and take profit points, providing a clear visual representation on the price chart. Traders can easily identify the relevant levels and incorporate them into their trading strategies.
Customizability: The indicator allows traders to customize the ATR length and choose whether to display Fibonacci levels (although there are no Fibonacci calculations in the provided code). These customization options enable traders to adapt the indicator to their preferred trading style and timeframe.
Limitations and Considerations:
Complementary Analysis: The Daily SPY Plan indicator should be used as a complementary tool alongside other technical analysis techniques and indicators. It provides price levels and take profit points based on ATR calculations, but it doesn't incorporate additional market factors or trading strategies.
Timeframe Suitability: The indicator is specifically designed for the daily timeframe of the SPY. Traders should consider adjusting the parameters and adapting the indicator if using it on different timeframes or instruments.
Risk Management: While the indicator suggests potential breakout and take profit points, it does not provide explicit stop-loss levels or risk management parameters. Traders should incorporate appropriate risk management techniques to protect their capital.
Conclusion:
The Daily SPY Plan indicator is a valuable technical analysis tool for traders focusing on the SPY ETF and the daily timeframe. By utilizing the ATR, it helps traders identify potential breakout levels and take profit points. However, traders should remember that this indicator is just one piece of the puzzle and should be used in conjunction with other technical analysis tools and risk management strategies to make informed trading decisions.
Grid Strategy with MA0. Preface
Hello traders,
This is a strategy script that allows you to utilize a Grid Strategy using moving averages.
It is very simple, but I decided to post it because it was hard to find such shared open-source codes in Pine Script.
1. Main
This is a very simple trading method.
Based on the moving average line you set, if the price drops by a certain ATR (or percent) below it, you buy, and when it goes back up, you sell.
In basic settings, you choose the moving average line and its length, and decide how much to set the distance between each grid through the 'Band Multiplier/Percent' item.
I believe that it is advantageous to widen the bandwidth for stocks with strong upward momentum.
2. Conclusion
I have confirmed that this works better in the stock market than in the crypto market,
and that it is suitable for use on index stocks like NASDAQ because it follows trends.
In addition, through backtesting, I have confirmed that this grid strategy is more suitable for buying strategies than selling strategies, so I uploaded it as a strategy focused on buying strategies.
Personally, I have developed my own strategy by adjusting buying and selling strategies according to trends and managing risks.
I hope you can use this to create a script that suits you.
Thank you.
Order Block & Fractal Zones (OBFZ) Indicator.The "Order Block & Fractal Zones (OBFZ) Indicator." indicator is a technical analysis tool designed to identify and display key price levels on a chart. It utilizes the concept of Order Blocks and the Fractal Value Zone (FVG) to highlight potential support and resistance areas in the market.
The indicator marks bearish and bullish Order Blocks, which are significant price structures characterized by consecutive higher highs and higher lows for a bearish block, or consecutive lower lows and lower highs for a bullish block. These blocks suggest potential areas of market reversal.
Additionally, the indicator calculates and displays retracement and extension levels within each Order Block. These levels are derived from the previous highest and lowest values within a specified number of candles. The retracement levels include 38.2%, 50%, and 61.8%, while the extension levels include 138.2%, 150%, and 161.8%.
Furthermore, the Fractal Value Zone (FVG) is determined to identify the highest high and lowest low within the selected number of candles. The FVG helps identify areas of significant price action and potential breakout zones.
Overall, the "Order Block & Fractal Zones (OBFZ) Indicator." indicator assists traders in identifying potential support and resistance levels, as well as areas of market reversal or breakout. It can be used to make informed trading decisions based on key price levels within the observed price action.

Edri Extreme Points Buy & SellEDRI EXTREME POINTS BUY & SELL INDICATOR
This Buy and Sell (non-repainting) indicator uses signals based on the combined CCI/Momentum and RSI indicators and optional regular divergence.
The idea of the indicator is to look for a potential reversal after the price reached extreme points (overbought or oversold) and signals an entry when the price shows signs of momentum for reversal.
Optionally, it considers finding a divergence while RSI is at the extreme levels to improve the predictability of a possible reversal.
Additionally, the indicator includes a simple Mean Reversion visual on the chart to assist users in identifying extreme price levels and potential reversal opportunities. It features upper and lower bands that can be optionally plotted, showing calculated values where price bounces at those extreme levels.
The purpose of these bands is to help traders avoid getting trapped in the middle of a trend and to guide them to buy low and sell high. (It's important to note that this is purely a visual aid and does not impact the generation of trade signals.)
By utilizing the Mean Reversion bands alongside the entry conditions, traders can gain insights into potential price reversals and make more informed decisions about when to enter or exit trades.
Buy and Sell Entry conditions:
• The indicator looks at the CCI/Momentum indicator to turn positive (if buy) or negative (if sell) after the RSI was overbought or oversold in the recent past.
• It also checks if there is a 3-period regular bullish divergence in the RSI (if buy), or regular bearish divergence (if sell) and consider these in the entry condition.
• If these conditions are met, this indicator suggests that it may be a good time to enter a trade.
In summary this is how this indicator works:
• The indicator takes input settings such as the choice between using CCI or Momentum as the entry signal source, length parameters for CCI/Momentum, RSI levels for overbought and oversold conditions, RSI length, and options to plot mean reversion bands on the chart.
• It calculates the CCI and Momentum and RSI values based on user-defined length..
• It checks for regular bullish and bearish divergences (3 periods) in the RSI if the option is enabled.
• The script plots shapes on the chart to indicate the buy and sell signals based on the entry conditions.
• If the mean reversion bands option is enabled, it calculates the mean reversion, standard deviation, upper band, and lower band values.
• It also plots the upper band, mean reversion line, and lower band on the chart if the mean reversion bands option is enabled.
• This indicator includes alert conditions to generate alerts for the buy and sell signals.
• On top of that, users can opt to use only one alert for both buy and sell signals. (This can save Trading view subscribers with limited alerts.)
Important! Please do not consider everything you read here as financial advice. Additionally, do not rely solely on indicators for making your trading decisions. It is important to note that no indicator or strategy is perfect. Therefore, it is always recommended to backtest everything and practice proper risk management.
I appreciate your feedback on this indicator. As I am new to script development, I am open to comments and suggestions to improve it. If you encounter any issues while using this indicator, please let me know in the comments section. If you find it helpful, I kindly ask for your support in boosting it. Thank you for your cooperation.

Filtered Momentum Indicator (FMI)The Filtered Momentum Indicator (FMI) is a tool created to assist traders in identifying changes in momentum and gaining insights into potential shifts in price trends. By combining the concepts of momentum and Bollinger Bands, the FMI offers a unique perspective on momentum values and their relationship to price movements, helping traders make informed trading decisions. The FMI is calculated using two main components:
-- Momentum Calculation : Momentum measures the strength and velocity of price changes. It is calculated by comparing the current price to the price 14 (default) periods ago and expressing it as a percentage.
-- Bollinger Bands Calculation : Bollinger Bands are based on the momentum values and provide a range within which the momentum is expected to fluctuate. The upper and lower bands are determined using a specified period (default of 20) and deviations (default of 2.0).
The FMI consists of two lines : F+ (Filtered Plus) and F- (Filtered Minus). These lines help gauge the strength of bullish and bearish momentum:
-- F+ represents the difference between the upper Bollinger Band and the momentum values. It indicates the strength of bullish momentum. F+ is colored aqua.
-- F- represents the difference between the momentum values and the lower Bollinger Band. It indicates the strength of bearish momentum. F- is colored yellow.
When analyzing the FMI, pay attention to the relationship between F+ and F-:
-- If F- is greater than F+ , it suggests potential bullish momentum, indicating that prices may have room to rise.
-- If F+ is greater than F- , it suggests potential bearish momentum, indicating that prices may have room to decline.
Coloration of the FMI enhances its interpretability - when F- is greater than F+, the indicator color is set to lime (green), signaling potential bullish momentum; when F+ is greater than F-, the indicator color is set to fuchsia (purple), signaling potential bearish momentum.
The FMI can be applied in various ways for trading strategies:
-- Identifying Potential Reversals : Watch for crossovers between the F- and F+ lines, as they may indicate a potential shift in momentum and offer opportunities to enter or exit trades.
-- Confirmation Tool : Combine the FMI with other technical indicators or price patterns to validate potential trend reversals or continuations. By aligning signals from different indicators, you can strengthen your trading decisions.
-- Trade Timing : Consider taking trades in the direction of the dominant FMI color. When the indicator shows strong bullish momentum (F- > F+), consider going long. Conversely, when it shows strong bearish momentum (F+ > F-), consider going short.
It is essential to be aware of the limitations of the FMI:
-- False Signals : The FMI, like any indicator, may generate false signals, especially during low volatility or choppy market conditions. Always use the FMI in conjunction with other analysis techniques for confirmation.
-- Lagging Nature : The FMI relies on historical price data, causing it to lag behind sudden market moves. Keep in mind that the FMI provides insights based on past momentum and may not capture immediate changes in market conditions.
By combining momentum and Bollinger Bands, this indicator provides a unique perspective for making informed trading decisions. Utilize the FMI in conjunction with other analysis techniques, considering its limitations, to enhance your trading strategy and improve decision-making.

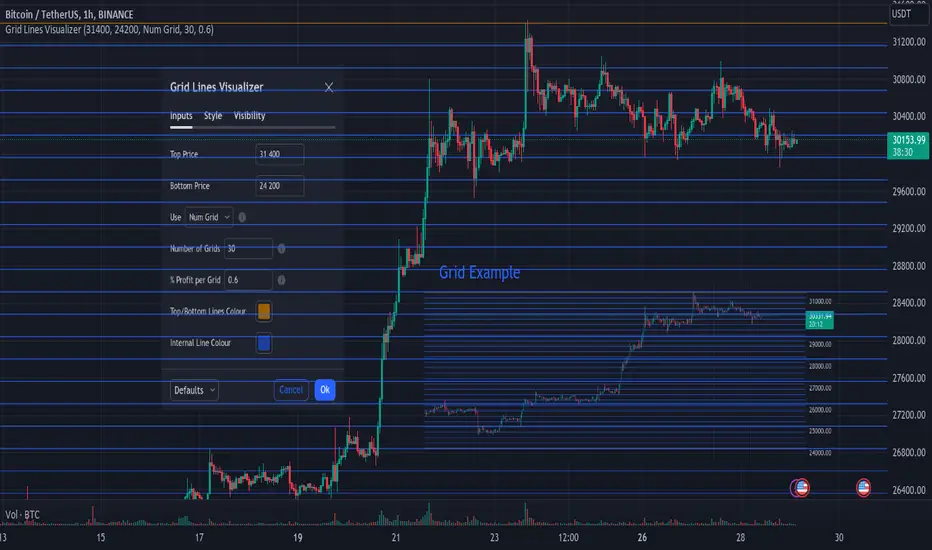
Simple Grid Lines VisualizerAbout Grid Bots
A grid bot is a type of trading bot or algorithm that is designed to automatically execute trades within a predefined price range or grid. It is commonly used in markets that exhibit ranging or sideways movement, where prices tend to fluctuate within a specific range without a clear trend.
The grid bot strategy involves placing a series of buy and sell orders at regular intervals within the predefined price range or grid. The bot essentially creates a grid of orders, hence the name. When the price reaches one of these levels, the bot will execute the corresponding trade. For example, if the price reaches a predefined lower level, the bot will buy, and if it reaches a predefined upper level, it will sell.
The purpose of the grid bot strategy is to take advantage of the price oscillations within the range. As the price moves up and down, the bot aims to generate profits by buying at the lower end of the range and selling at the higher end. By repeatedly buying and selling at these predetermined levels, the bot attempts to capture gains from the price fluctuations.
About this Script
Simple Grid Lines Visualizer is designed to assist traders in visualizing and implementing automated price grids on their charts. With just a few inputs, this script generates gridlines based on your specified top price, bottom price, and the number of grids or profit per grid.
How it Works:
Specify Top and Bottom Prices: Start by setting the top and bottom prices that define the range within which the gridlines will be generated. These prices can be based on support and resistance levels, historical data, or any other factors you consider relevant to your analysis.
Determine Grid Parameters: Choose either the number of grids or profit per grid, depending on your preference and trading strategy. If you select the number of grids, the script will evenly distribute the gridlines within the specified price range. Alternatively, if you opt for profit per grid, the script will calculate the price increment required to achieve your desired profit level per grid.
Note that when choosing Profit per Grid , an approximation usually is performed, as all grid lines must be evenly distributed. To achieve that, the script computes the grid distance using the mean price between top and bottom, then computes how many of those complete distances may enter the entire range, and lastly, creates a grid with evenly distributed distances as close as possible to the previously computed.
Customize Styling and Display: Adjust the line color, line style, transparency, and other visual aspects to ensure clear visibility on your charts.
Analyze and Trade: Once the gridlines are plotted on your chart, carefully observe how the market interacts with them. The gridlines can act as reference points for potential support and resistance levels, as well as simple buy/sell orders for a trading bot.
Try to find gridlines that intersect prices as frequently as possible from one to another.
A grid with too many lines will make lots of potential trades, but the amount traded will be minimal (as the total amount invested is divided over the number of grids).
A grid with too few lines will make lots of profits with each trade, but the trades will be less likely to occur (depending on the top/bottom distance).
This tool aims to help visually which grid parameters seem to optimize this problem.
Future versions may include automatic profit computation.
Dynamic Trend RipperThe "Dynamic Trend Ripper" indicator is designed to identify dynamic support and resistance levels based on exponential moving averages (EMA) and the average true range (ATR). It aims to assist traders in identifying potential trading opportunities by visualizing dynamic support and resistance areas on the price chart. Think of it as more of overbought or oversold areas then true support and resistance,
The indicator calculates two sets of EMAs: two for the top cloud and two for the bottom cloud. The lengths of these EMAs are determined by user-defined input parameters. Additionally, the indicator uses the ATR to adjust the EMAs, enhancing their effectiveness as dynamic support and resistance levels.
The top cloud is formed by adding the ATR to the top fast EMA and subtracting the ATR from the top slow EMA. The bottom cloud is formed by subtracting the ATR from the bottom fast EMA and adding the ATR to the bottom slow EMA.
The indicator plots the dynamic OB (Overbought) level, which is the top fast EMA plus the ATR multiplied by the OBOS multiplier. It also plots the dynamic OS (Oversold) level, which is the top slow EMA minus the ATR multiplied by the OBOS multiplier. These levels are visualized using colored lines on the chart.
The top fast EMA, top slow EMA, bottom fast EMA, and bottom slow EMA are also plotted on the chart. The area between the top slow EMA and top fast EMA is filled with a color, forming the top cloud. The area between the bottom fast EMA and bottom slow EMA is filled with another color, forming the bottom cloud. The color of the clouds changes based on the relationship between the top fast EMA and top slow EMA. If the Regular Fast EMA is greater than the Regular slow EMA, indicating a bullish trend, the clouds are displayed in green. Otherwise, if the top fast EMA is less than the top slow EMA, indicating a bearish trend, the clouds are displayed in red.
The indicator can be used to identify potential support and resistance zones where the price may encounter obstacles or reverse its direction. Traders can look for price interactions with the dynamic support and resistance levels, as well as the OB and OS levels, to make trading decisions. For example, a trader might consider entering a short trade when the price approaches the top cloud, or a long trade when the price bounces off the bottom cloud.
By incorporating the ATR, which measures volatility, the indicator adjusts the EMAs to adapt to changing market conditions. Traders can watch for price reactions or reversals near these levels to gauge potential overextension or exhaustion in the price movement. I'm not going to claim this as my own idea, but I will say that I came up with this version myself. I haven't seen anyone else take this approach which is why I think it can be revolutionary to trading.
EXTREME OVERBOUGHT/SOLD BANDS
ATR-ADJUSTED EMA'S
Powertrend - Volume Range Filter Strategy [wbburgin]The Powertrend is a range filter that is based off of volume, instead of price. This helps the range filter capture trends more accurately than a price-based range filter, because the range filter will update itself from changes in volume instead of changes in price. In certain scenarios this means that the Powertrend will be more profitable than a normal range filter.
Essentials of the Strategy
This is a breakout strategy which works best on trending assets with high volume and liquidity. It should be used on middle to higher timeframes and can be used on all assets that have volume provided by the data source (stocks, crypto, forex). It is long-only as of now. It can work on lower timeframes if you optimize the strategy filters to make less trades or if your exchange/broker is low/no fees, provided that your exchange/broker has high liquidity and volume.
The strategy enters a long position if the range filter is trending upwards and the price crosses over the upper range band, which signifies a price-volume breakout. The strategy closes the long position if the range filter is trending downwards and the price crosses under the lower range band, which signifies a breakdown. Both these conditions can be altered by the three filter options in the settings. The default trend filter is not alterable because it helps prevent false entries and exits that are against the trend.
Settings
The Length setting is the lookback period for the range smoothing.
The ADX Filter setting enables you to turn on an ADX filter, which will halt entries and exits unless the ADX of your customizable length is above a ADX VWMA of that length.
The Range Supertrend setting creates a supertrend from the top and bottom ranges, which can be used to filter entries and exits. The length is customizable. The filter can show you whether the range is making higher highs and lower lows. Below is an example of the Range Supertrend being used as a filter and plotted on-chart:
The VWMA setting halts entries if they are below a customizable length VWMA.
Both the Range Supertrend and the VWMA can also be plotted separately without actually filtering the strategy, so that you can use them independently if you wish. You can turn off the bar color, the highlighting, and the labels if you wish in the settings. A note about the bar color: if the color changes but the strategy does not signal an exit or entry this means that the crossover was against the trend. In these circumstances it may be indicative of a pullback to enter or exit or to add onto your position.
About the Strategy Results Below
A range filter is normally composed of two components - the range filter itself and a smoothing function. In the development of this script I tested both normal and volume-based varieties of the range filter and the smoothing function:
Tests Performed
Volume-based Range x VWMA smoothing
Price-based Range x VWMA smoothing
Price-based Range x EMA smoothing
Volume-based Range x EMA smoothing (final result)
The highest-performing was a volume-based range filter and a normal EMA-based smoothing function, but that does not mean that this strategy will be profitable - exits are based off of signal reversion so I strongly encourage you to develop your own take profits/stop losses for the strategy if you think it may be a good fit for you. The results below are with a commission value of 0.05% (because I built the strategy first for equities), slippage of 3, so if your exchange/broker has a higher fee schedule, I recommend adding filters and/or moving to higher timeframes for the strategy. Additionally, I used 10% of equity in each trade, while using the Range Supertrend filter (the previous upload was unrealistic because it used 100% of equity - missed a 0, apologies, and added in slippage).

Fibonacci Trend Zone The "Fibonacci Trend Zone" indicator is a supplementary tool that helps identify the current trend based on Fibonacci zones. It utilizes Fibonacci levels (0.62, 0.705, and 0.79) to define long-term trend zones. The green zone indicates potential long trades, while the red zone suggests potential short trades. The indicator also includes the Triple Exponential Moving Average (TEMA), which helps confirm trend reversals. When the TEMA crosses the Fibonacci level of 0.5, it may signal a possible trend reversal. Use this indicator in conjunction with your primary trading strategy to make more informed trading decisions. Additionally, the indicator provides flexibility in customizing the styles, allowing you to change the color scheme or disable the display of certain elements to suit your preferences and requirements.
Индикатор "Fibonacci Trend Zone" является вспомогательным инструментом, который помогает определить текущий тренд на основе зон фибоначчи. Он использует уровни фибоначчи (0,62, 0,705 и 0,79) для определения зон долгосрочного тренда. Зеленая зона указывает на возможность лонг-сделок, а красная зона - на возможность шорт-сделок. Индикатор также включает Triple Exponential Moving Average (TEMA), который помогает подтвердить смену тренда. Когда TEMA пересекает уровень фибоначчи 0,5, это может сигнализировать о возможной смене тренда. Используйте данный индикатор в сочетании с вашей основной торговой стратегией для принятия более информированных решений. Индикатор также предоставляет гибкость в настройке стилей, позволяя вам изменить цветовую схему или отключить отображение некоторых элементов, чтобы соответствовать вашим предпочтениям и требованиям.

Anchored VWAP (Auto High & Low)OVERVIEW
This script plots, and auto-updates, 3 separate VWAPs: a traditional VWAP, a VWAP anchored to a trends high, and another anchored to a trends low.
VWAP and Anchored VWAPs are commonly used by institutions responsible for the majority of market volume on a given day. Citadel Trading, for example, accounts for approximately 35% of all U.S. listed retail volume , largely executed through program trades over the course of a day, week, or month.
Because VWAP is a prominent market maker tool for executing large trades, day traders can use it to better anticipate trends, mean reversion, and breakouts.
This is most useful on charts with intraday time frames (1 minute, 5 minute etc.) commonly used for day trading. This is not ideal for larger time frames (1 hour or greater) commonly used for swing trading or identifying larger trends.
INPUTS
You can configure:
The size, color, and visibility of 6 different plots (VWAP, High Anchor, Low Anchor, Average of Anchors, Quarter Values, Interim Bands)
How smooth the average displays
INSPIRATION
1. "How To Measure Anything" by Douglas W. Hubbard
2. "Maximum Trading Gains With Anchored VWAP" by Brian Shannon
Better understanding probability and how to analyze risk (first book), as well as the tools market makers use (second book), has completely reframed how I approach day trading.

Trend Channels With Liquidity Breaks [ChartPrime]Trend Channels
This simple trading indicator is designed to quickly identify and visualize support and resistance channels in any market. The primary purpose of the Trend Channels with Liquidity Breaks indicator is to recognize and visualize the dominant trend in a more intuitive and user-friendly manner.
Main Features
Automatically identifies and plots channels based on pivot highs and lows
Option to extend the channel lines
Display breaks of the channels where liquidity is deemed high
Inclusion of volume data within the channel bands (optional)
Market-friendly and customizable colors and settings for easy visual identification
Settings
Length: Adjust the length and lookback of the channels
Show Last Channel: Only shows the last channel
Volume BG: Shade the zones according to the volume detected
How to Interpret
Trend Channels with Liquidity Breaks indicator uses a combination of pivot highs and pivot lows to create support and resistance zones, helping traders to identify potential breakouts, reversals or continuations of a trend.
These support and resistance zones are visualized as upper and lower channel lines, with a dashed center line representing the midpoint of the channel. The indicator also allows you to see the volume data within the channel bands if you choose to enable this functionality. High volume zones can potentially signal strong buying or selling pressure, which may lead to potential breakouts or trend confirmations.
To make the channels more market-friendly and visually appealing, Trend Channels indicator also offers customizable colors for upper and lower lines, as well as the possibility to extend the line lengths for further analysis.
The indicator displays breaks of key levels in the market with higher volume.
